
I’ve been working on a coin selection algorithm using Evolutionary Algorithm. I am creating this issue to discuss the possibilities related to it. If here is not the best place to discuss it, feel free to close this issue.
If you don’t know what an Evolutionary Algorithm is, here is a good definition: "EA is a subset of evolutionary computation, a generic population-based metaheuristic optimization algorithm. An EA uses mechanisms inspired by biological evolution, such as reproduction, mutation, recombination, and selection. Candidate solutions to the optimization problem play the role of individuals in a population, and the fitness function determines the quality of the solutions (see also loss function). Evolution of the population then takes place after the repeated application of the above operators". Anyway, I recommend you to study more about EA before trying to understand this proposal.
In Evolutionary Algorithms we have genes, chromosomes, and population, for example:
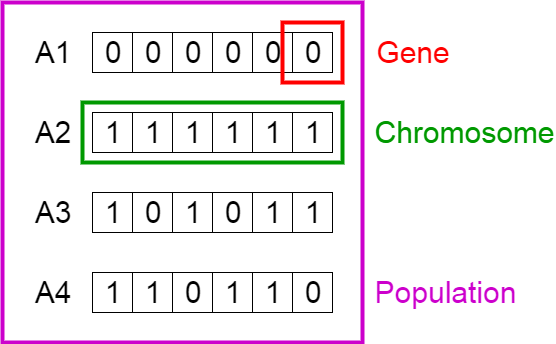
So, to begin our algorithm, we must first create an initial population. The population will contain an arbitrary number of possible solutions to the problem, oftentimes called members. In this case, a gene is a UTXO, so, every chromosome is a set of UTXOs.
member1 = [utxo1, utxo2, utxo3]
member2 = [uxto2, utxo5, utxo6, utxo7, utxo8]
...
To create the initial population, we can use the following approach (considering 5 members per population):
- 1 member composed of all UTXOs
- 1 member that selects randomly from the shuffled UTXOs until the target is exceeded
- 3 random members
Obs.: Most evolutionary algorithms set a length for the chromosome. However, for this approach, we don’t do it because we don't know how many UTXOs our final solution will use.
Ok, having our initial population, it is time to evaluate each solution (fitness). To do it, we can use the waste metric, introduced in Bitcoin Core recently. So, our metric to evaluate the members is the cost of creating change, the excess selection amount, and the cost of spending inputs now as opposed to sometime in the future (when we expect to be able to consolidate inputs). See more: https://bitcoincore.reviews/22009
After evaluating each member, we can define what is the best one among them and build our next population (new generation).
Our new population will have (considering 5 members):
- 3 members from mutation
- 1 member keeping the same chromosome of the best solution from the previous generation
- 1 new random member
Considering 50% mutation rate, we create 3 members copying the same chromosome of the best solution from the previous generation and applying mutation, like:
for (gene in chromosome) {
const random_value = getRandomValueBetween0and1()
if (random_value == 1) {
gene = getRandomUtxo()
}
}
Ok, now we have a new population, and then, we can repeat all the processes (fitness and mutation) N times (being N the number of generations), the best member of the last generation will be our final solution.





