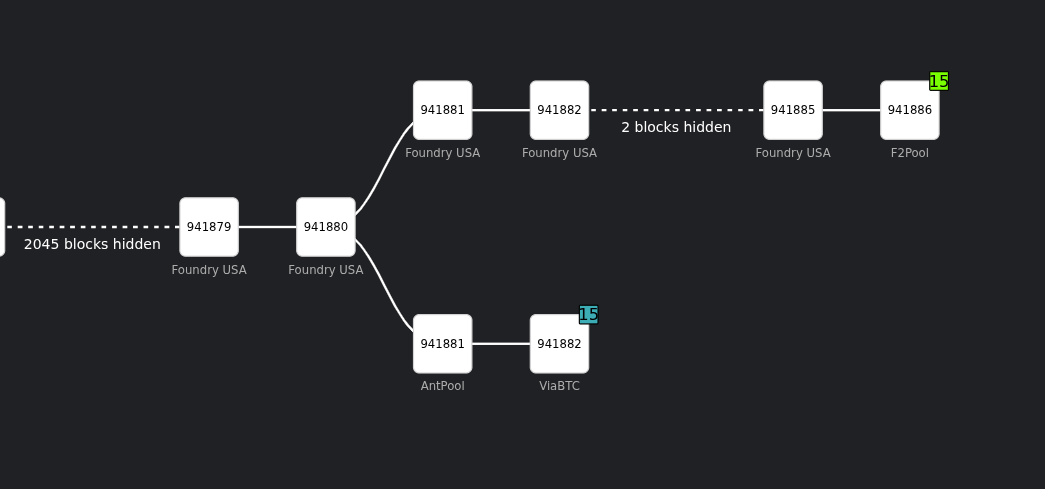
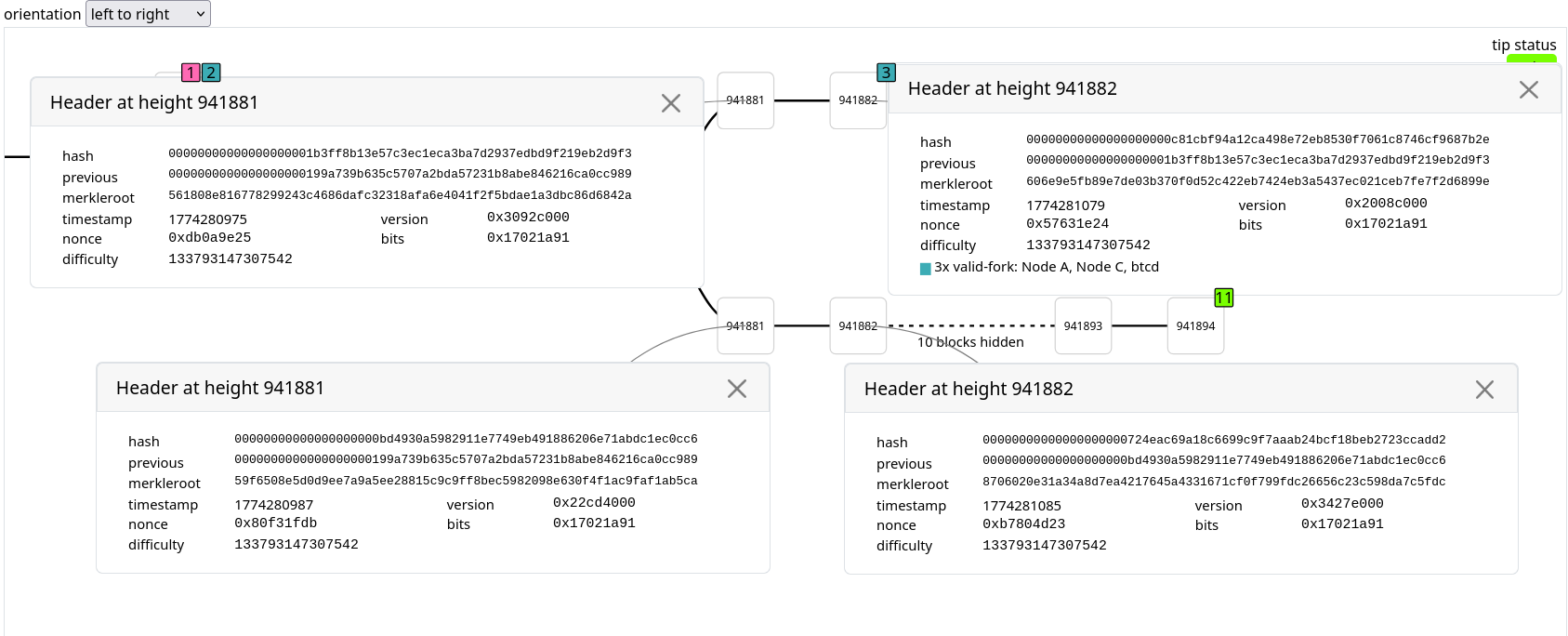
00000000000000000001b3ff8b13e57c3ec1eca3ba7d2937edbd9f219eb2d9f3 (AntPool) at height 941881
00000000000000000000c81cbf94a12ca498e72eb8530f7061c8746cf9687b2e (ViaBTC) at height 941882
While Foundry mined the following blocks to win the race:
00000000000000000000bd4930a5982911e7749eb491886206e71abdc1ec0cc6 (Foundry) at height 941881
00000000000000000000724eac69a18c6699c9f7aaab24bcf18beb2723ccadd2 (Foundry) at height 941882
000000000000000000009c9acd0bc3207fa181f79f8573bf27d8a81d1ef3aa8e (Foundry) at height 941883
I found it interesting that boerst’s stratum-work did not see any stratum jobs from Foundry mining on their winning blocks. See e.g. 941882 on stratum.work.
Maybe they were only mining on them in one region, and stratum-work is connected to a different one, or they kept quite about them (i.e. selfish mining), or it’s a bug on stratum-work
Yup, I am just hoping these pool operators are running sensible clocks - if not using ntp.
I looked into this cause I am interested in the uncles probability in p2poolv2. If we look at the fork monitor, it looks like if blocks are within 15-30 seconds of each other it results in a fork. This makes me think if we can get the mean/stddev on the fork blocks timestamps deltas Again, assuming clock drift is not too high.
It’ll be fascinating to see how this delta changes between different pairs of pools. Detect friends and enemies
Yeah, but they should also send a new job immediately on seeing a new block. Unless of course there are some strategies they use to detect how to react to blocks from different pools. Might be interesting to uncover
Thanks for that link to the data. We don’t see the pool name there, right? Do you think we can include that for the data from now on? Or it might be in another data set somewhere that I can join. We want to get the pool names for the orphan blocks too.
Sorry, am new to all your work, so probably asking naive questions.
I’m not sure what the maths would be to figure out what to expect there – naively I would have thought you’d square the frequency of one-block reorgs (since you need two blocks in a row to be found almost simultaneously to avoid everyone agreeing on a single tip) which would lead to expecting about a million blocks between 2-block reorgs if we’re seeing 1-block reorgs every thousand blocks, but perhaps you get different results if you model internal delays getting jobs/work distributed between the pool and ASICs separately from network block propagation.
My timings for the headers in question were:
2026-03-23T15:49:53.982265Z Saw new cmpctblock header hash=00000000000000000001b3ff8b13e57c3ec1eca3ba7d2937edbd9f219eb2d9f3 height=941881 peer=14899 peeraddr=45.32.83.173:54302
2026-03-23T15:51:47.008245Z Saw new header hash=00000000000000000000c81cbf94a12ca498e72eb8530f7061c8746cf9687b2e height=941882 peer=38718 peeraddr=124.156.199.113:36184
2026-03-23T15:55:03.500660Z Saw new header hash=000000000000000000009c9acd0bc3207fa181f79f8573bf27d8a81d1ef3aa8e height=941883 peer=36252 peeraddr=65.109.99.249:35498
I didn’t see Foundry’s racing blocks until the reorg. (Which might suggest that 1-block stale blocks are much more common than 1-in-a-thousand, but they just aren’t visible)
FWIW, I’m not collecting Foundry’s templates on https://stratum.work/ - I could never get a working account from them.
From the pools that I do collect, I can see that none of the other pools were sending work building on top of Foundry’s 941881 and 941882 blocks. Everyone else was seemingly following the AntPool/ViaBTC chain.
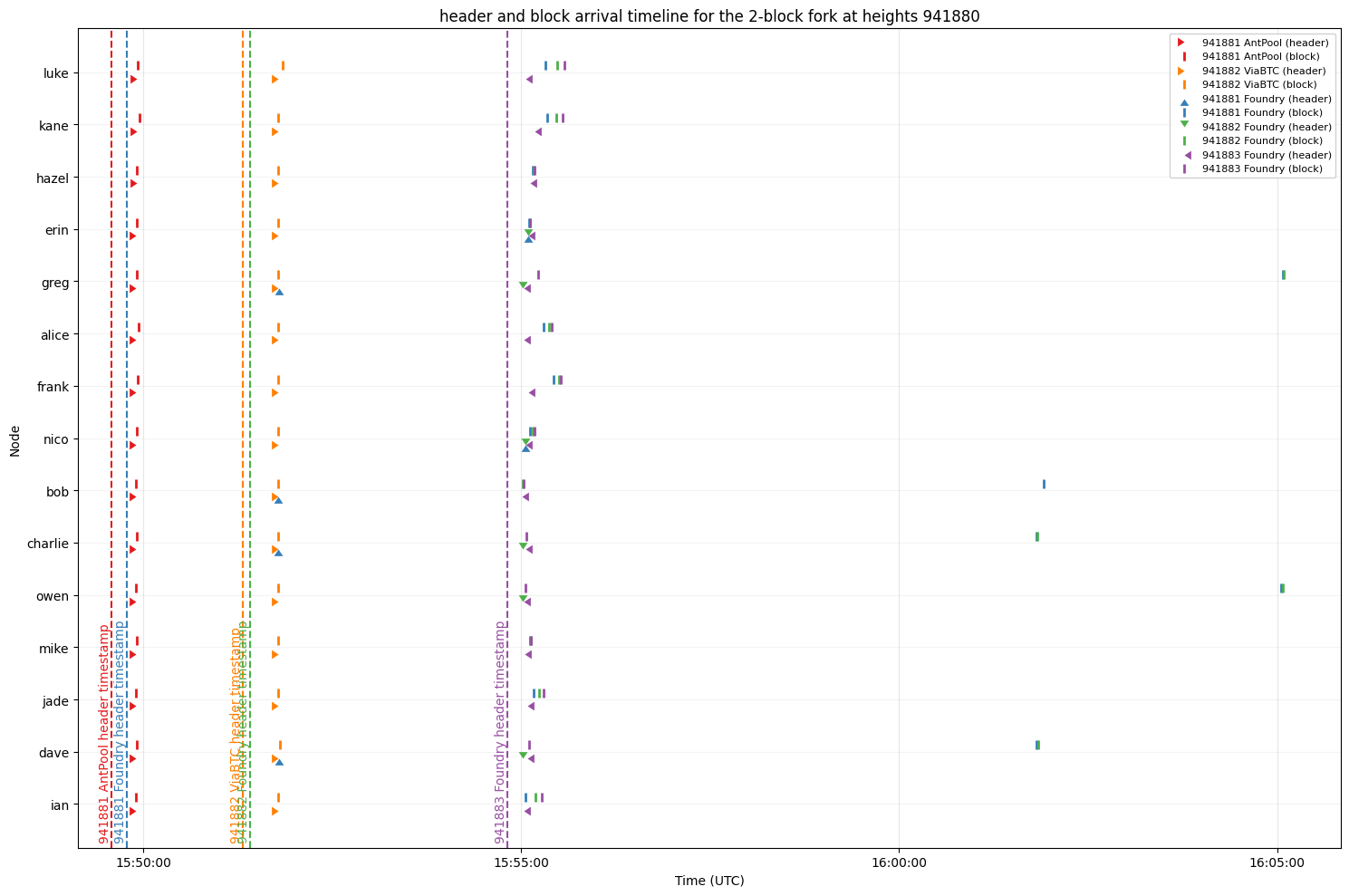
I looked a bit at the header and block arrival times in the debug.logs of my monitoring nodes. Here, “header” means we either got an INV for this block, saw a cmpctblock or a header. Full block means we received the block or successfully reconstructed the block from a compact block.
Foundry released their 1st block (header) immediately after the others’ 2nd block was found. According to their own timestamp on their 1st and 2nd blocks, they found them a few seconds after the others’ 1st and 2nd blocks. They released their 2nd and 3rd at the same time, exactly when the 3rd block was found, winning the race. This is effectively a selfish-mining attack by definition even if it was on “accident” or network hiccup (to the extent “attack” doesn’t imply intentional). But it all seems to point to intentional.
Intentional or not, other miners should ignore 2 of Foundry’s blocks. Without enforcing accurate timestamps, this how selfish mining can be made a “nothing burger”. >50% needs to collude to disincentivize future attacks. If Foundry stops displaying it’s name to prevent this, the only solution is to enforce more accurate timestamps. For example, the rule would be to ignore a header for 600 seconds if its timestamp is more than 15 seconds different from local time (rounded to the nearest 10 s interval) when it arrives. This works because the attacker has to assign a timestamp before he knows when he will need to release it. People complain that this can cause a real problem in real network partitions and it’s true a chain split would last longer if that’s the case, but it will eventually resolve itself based on PoW and which partition has the most hashrate. Rounding to the nearest 10 second interval prevents an attack on the interval. Clocks shouldn’t be off more than 2 seconds which is the other big complaint. Also, miners would have to update the timestamp every 2 seconds.
Concerning not being able to get Foundry’s templates, Grok says:
Yes, restricting public or easy access to block templates can serve Foundry (or any large pool) if they were engaging in illicit or strategically deviant behavior like selfish mining or block withholding—primarily by reducing detectability and transparency.
@b10c, it would also be interesting to see this chart split by mining pool. I wonder whether some mining pools that time-roll would have a distinctly different pattern than pools that don’t. Also, I was curious how accurate timestamps of the involved pools are, i.e., whether the timestamps on these concrete competing blocks would lend credence to the idea that Foundry happened to actually find both their blocks right after the competing block as the timestamps seem to hint.
I looked at the arrival times of the inv messages corresponding to these blocks at one of our monitor nodes. These monitor nodes receive and log inv messages but do not request the data for headers or blocks.
The following list of blocks contains in the first column the point in time at which the monitor received the first inv message for a certain block. The last column shows the number of peers from which the monitor node received the inv message.
An announcement for Foundry’s block at height 941881 was received before any announcement for a block at height 941882 was received.
The monitor node received announcements for Foundry’s blocks at heights 941881 and 941882 only from a few peers. I don’t have an idea why. I would expect that nearly all peers should announce these blocks once they become part of the active chain.
EDIT: The majority of nodes announcing these blocks has in common that they announce btcd as their user agent. It seems that Bitcoin Core does not send inv messages for these blocks to our monitor.
Looking at debug logs for one of @achow101’s node which was stalled from reorging to the foundry chain until ~16:05, I constructed the following table of events:
2026-03-23T15:49:54.432974Z [msghand] [../../src/blockencodings.cpp:228] [FillBlock] [cmpctblock] Successfully reconstructed block 00000000000000000001b3ff8b13e57c3ec1eca3ba7d2937edbd9f219eb2d9f3 with 1 txn prefilled, 4510 txn from mempool (incl at least 0 from extra pool) and 56 txn (21474 bytes) requested
2026-03-23T15:51:47.089420Z [msghand] [../../src/blockencodings.cpp:228] [FillBlock] [cmpctblock] Successfully reconstructed block 00000000000000000000c81cbf94a12ca498e72eb8530f7061c8746cf9687b2e with 1 txn prefilled, 871 txn from mempool (incl at least 1 from extra pool) and 0 txn (0 bytes) requested
15:51:47.176
Antpool 2
UpdateTip
1271642
2026-03-23T15:51:47.175709Z [msghand] [../../src/validationinterface.cpp:182] [UpdatedBlockTip] [validation] Enqueuing UpdatedBlockTip: new block hash=00000000000000000000c81cbf94a12ca498e72eb8530f7061c8746cf9687b2e fork block hash=00000000000000000001b3ff8b13e57c3ec1eca3ba7d2937edbd9f219eb2d9f3 (in IBD=false)
2026-03-23T16:02:32.049006Z [msghand] [../../src/blockencodings.cpp:228] [FillBlock] [cmpctblock] Successfully reconstructed block 0000000000000000000085ebdcd669c404195dbfeccbee902fc646dadc367a20 with 1 txn prefilled, 3268 txn from mempool (incl at least 76 from extra pool) and 736 txn (267962 bytes) requested
To kind of summarize what happened here, peer 199 (who aggressively INV’s blocks to this node and is often the first to do so) sent an INV of foundry’s first block, then this node sent a GETHEADERS then peer 199 replied with HEADERS, then the node sent a GETDATA for the block and peer 199 did not respond, notably the block stall time out is 10 minutes, and Bitcoin Core will not request a block while there is a block in-flight from a peer, the only escape valve during this stalling period is if one of a node’s high-bandwidth compact block peers sends an unrequested block, but this node was unlucky enough to have all of its compact block HB peers end up on one side of the race. I suspect @b10c’s owen and greg were similarly stalled.
I mostly built the table by hand using grep and bubblegum, but I pasted it into gemini-3.1 and asked it to write a script to generate such tables from debug.log files and (with a few tweaks) it seems (at a glance) to mostly work with a few small hiccups, if others want to automate making similar tables:
A miner mining on Foundry shared the following stratum job data with me. I’ve anonymized it a bit.
first job arrival timestamp
mining on block
duration on this tip
15:48:16.700
941880 Foundry
~ 98s
15:49:54.200
941881 AntPool (stale)
~ 1s
15:49:55.300
941881 Foundry
~ 112s
15:51:47.350
941882 ViaBTC (stale)
~ 1.3s
15:51:48.700
941882 Foundry
~ 192s
15:55:00.500
941883 Foundry
> 5min
My takeaway from this is:
at 15.49:54, Foundry send a job building on top of the AntPool 941881 block, but switched to it’s Foundry 941881 block around 1s later
then, at 15:51:47, ViaBTC found a block at height 941882, Foundry switched to this block, but after 1.3s switched to Foundry’s 941882
Foundry switching to their own block (e.g. with preciousblock) is a very reasonable thing to do for them. We know Foundry has been doing this for a while, and AntPool, for whatever reason, does not: Mining Pool Behavior during Forks
This also shows that Foundry too saw the AntPool and ViaBTC blocks arriving first. However, it’s not unreasonable that a miner submitted a valid share even after the AntPool & ViaBTC blocks where known to the network. See e.g. AntPool mines two blocks at height 925051 where AntPool miners found two valid shares at a similar time.
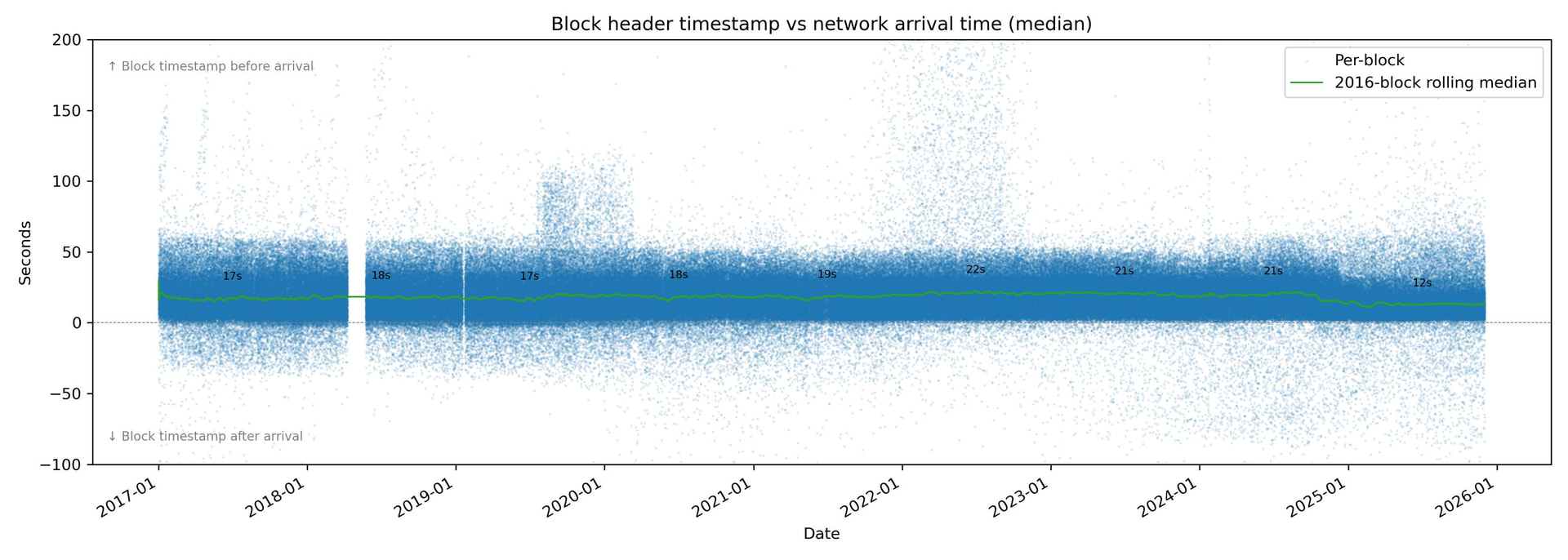
In a sample 2 years ago, all the pools seemed to be time-rolling because timestamps of all the pools seemed to average ~20 seconds before the header arrived and had a 20 s stdev. 5% of blocks had a stamp in the future. 0.4% had a block > 60 s in the past. Brainspool was an exception averaging 11 seconds with stdev of 25 (they a lot of blocks with timestamps in the future).
I raw two of my nodes logs through @davidgumberg’s script.
owen, a node that got stalled (by the same peer; see Block stall timeout: disconnect peer) and did only receive the 941881 Foundry block at around 16:05:
owen
Time
Block
Msg/Action
From Peer
To Peer
Log message
15:49:53.833781
Antpool1
INV
140374
2026-03-23T15:49:53.833781Z [msghand] [net] got inv: block 00000000000000000001b3ff8b13e57c3ec1eca3ba7d2937edbd9f219eb2d9f3 new peer=140374
15:49:53.834143
Antpool1
GETHEADERS
140374
2026-03-23T15:49:53.834143Z [msghand] [net] getheaders (941880) 00000000000000000001b3ff8b13e57c3ec1eca3ba7d2937edbd9f219eb2d9f3 to peer=140374
15:49:54.029989
Antpool1
HEADERS
127889
2026-03-23T15:49:54.029989Z [msghand] Saw new cmpctblock header hash=00000000000000000001b3ff8b13e57c3ec1eca3ba7d2937edbd9f219eb2d9f3 height=941881 peer=127889 peeraddr=X
15:49:54.030397
Antpool1
CMPCTBLOCK
127889
2026-03-23T15:49:54.028551Z [msghand] [net] received: cmpctblock (27910 bytes) peer=127889 \n 2026-03-23T15:49:54.030397Z [msghand] [cmpctblock] Initializing PartiallyDownloadedBlock for block 00000000000000000001b3ff8b13e57c3ec1eca3ba7d2937edbd9f219eb2d9f3 using a cmpctblock of 27910 bytes
15:49:54.056084
Antpool1
GETBLOCKTXN
127889
2026-03-23T15:49:54.055526Z [msghand] [cmpctblock] Initialized PartiallyDownloadedBlock for block 00000000000000000001b3ff8b13e57c3ec1eca3ba7d2937edbd9f219eb2d9f3 using a cmpctblock of 27910 bytes \n 2026-03-23T15:49:54.056084Z [msghand] [net] sending getblocktxn (93 bytes) peer=127889
2026-03-23T15:49:54.133473Z [msghand] [cmpctblock] Successfully reconstructed block 00000000000000000001b3ff8b13e57c3ec1eca3ba7d2937edbd9f219eb2d9f3 with 1 txn prefilled, 4510 txn from mempool (incl at least 0 from extra pool) and 56 txn (21474 bytes) requested
2026-03-23T15:49:54.585931Z [msghand] [validation] Enqueuing UpdatedBlockTip: new block hash=00000000000000000001b3ff8b13e57c3ec1eca3ba7d2937edbd9f219eb2d9f3 fork block hash=0000000000000000000199a739b635c5707a2bda57231b8abe846216ca0cc989 (in IBD=false)
15:50:01.254651
Foundry1
INV
140374
2026-03-23T15:50:01.254651Z [msghand] [net] got inv: block 00000000000000000000bd4930a5982911e7749eb491886206e71abdc1ec0cc6 new peer=140374
15:50:01.254993
Foundry1
GETHEADERS
140374
2026-03-23T15:50:01.254993Z [msghand] [net] getheaders (941881) 00000000000000000000bd4930a5982911e7749eb491886206e71abdc1ec0cc6 to peer=140374
15:51:47.118183
Antpool2
HEADERS
42523
2026-03-23T15:51:47.118183Z [msghand] Saw new header hash=00000000000000000000c81cbf94a12ca498e72eb8530f7061c8746cf9687b2e height=941882 peer=42523 peeraddr=X
15:51:47.118237
Antpool2
GETDATA
42523
2026-03-23T15:51:47.118237Z [msghand] [net] Requesting block 00000000000000000000c81cbf94a12ca498e72eb8530f7061c8746cf9687b2e from peer=42523
15:51:47.134567
Antpool2
CMPCTBLOCK
59642
2026-03-23T15:51:47.134077Z [msghand] [net] received: cmpctblock (5773 bytes) peer=59642 \n 2026-03-23T15:51:47.134567Z [msghand] [cmpctblock] Initializing PartiallyDownloadedBlock for block 00000000000000000000c81cbf94a12ca498e72eb8530f7061c8746cf9687b2e using a cmpctblock of 5773 bytes
15:51:47.152286
Antpool2
CMPCTBLOCK Reconstructed
59642
2026-03-23T15:51:47.152286Z [msghand] [cmpctblock] Successfully reconstructed block 00000000000000000000c81cbf94a12ca498e72eb8530f7061c8746cf9687b2e with 1 txn prefilled, 871 txn from mempool (incl at least 1 from extra pool) and 0 txn (0 bytes) requested
2026-03-23T16:02:31.216282Z [msghand] [cmpctblock] Successfully reconstructed block 0000000000000000000085ebdcd669c404195dbfeccbee902fc646dadc367a20 with 1 txn prefilled, 3272 txn from mempool (incl at least 80 from extra pool) and 732 txn (267066 bytes) requested
16:02:35.325659
Main4
BLOCK
200279
2026-03-23T16:02:35.325659Z [msghand] [net] received block 0000000000000000000085ebdcd669c404195dbfeccbee902fc646dadc367a20 peer=200279
16:04:49.362087
Main5
HEADERS
127889
2026-03-23T16:04:49.362087Z [msghand] Saw new cmpctblock header hash=00000000000000000001f8562235e11fc74d5eea589e4c37b671b4213e89f52f height=941885 peer=127889 peeraddr=X
16:04:49.362198
Main5
GETDATA
127889
2026-03-23T16:04:49.362198Z [msghand] [net] Requesting block 00000000000000000001f8562235e11fc74d5eea589e4c37b671b4213e89f52f from peer=127889
16:04:49.376749
Main5
INV
140374
2026-03-23T16:04:49.376749Z [msghand] [net] got inv: block 00000000000000000001f8562235e11fc74d5eea589e4c37b671b4213e89f52f have peer=140374
16:04:50.082036
Main5
BLOCK
127889
2026-03-23T16:04:50.082036Z [msghand] [net] received block 00000000000000000001f8562235e11fc74d5eea589e4c37b671b4213e89f52f peer=127889
16:04:55.059965
Main5
INV
215836
2026-03-23T16:04:55.059965Z [msghand] [net] got inv: block 00000000000000000001f8562235e11fc74d5eea589e4c37b671b4213e89f52f have peer=215836
2026-03-23T15:49:54.893326Z [msghand] [cmpctblock] Successfully reconstructed block 00000000000000000001b3ff8b13e57c3ec1eca3ba7d2937edbd9f219eb2d9f3 with 1 txn prefilled, 4510 txn from mempool (incl at least 0 from extra pool) and 56 txn requested
2026-03-23T15:49:55.981503Z [msghand] [validation] Enqueuing UpdatedBlockTip: new block hash=00000000000000000001b3ff8b13e57c3ec1eca3ba7d2937edbd9f219eb2d9f3 fork block hash=0000000000000000000199a739b635c5707a2bda57231b8abe846216ca0cc989 (in IBD=false)
15:51:47.098370
Antpool2
GETDATA
1030531
2026-03-23T15:51:47.098370Z [msghand] [net] Requesting block 00000000000000000000c81cbf94a12ca498e72eb8530f7061c8746cf9687b2e from peer=1030531
15:51:47.160858
Antpool2
CMPCTBLOCK Reconstructed
1030531
2026-03-23T15:51:47.160858Z [msghand] [cmpctblock] Successfully reconstructed block 00000000000000000000c81cbf94a12ca498e72eb8530f7061c8746cf9687b2e with 1 txn prefilled, 871 txn from mempool (incl at least 1 from extra pool) and 0 txn requested
2026-03-23T15:55:10.273036Z [msghand] [validation] Enqueuing UpdatedBlockTip: new block hash=000000000000000000009c9acd0bc3207fa181f79f8573bf27d8a81d1ef3aa8e fork block hash=0000000000000000000199a739b635c5707a2bda57231b8abe846216ca0cc989 (in IBD=false)
16:02:30.912021
Main4
HEADERS
33316
2026-03-23T16:02:30.912021Z [msghand] Saw new cmpctblock header hash=0000000000000000000085ebdcd669c404195dbfeccbee902fc646dadc367a20 peer=33316
16:02:31.006373
Main4
CMPCTBLOCK Reconstructed
33316
2026-03-23T16:02:31.006373Z [msghand] [cmpctblock] Successfully reconstructed block 0000000000000000000085ebdcd669c404195dbfeccbee902fc646dadc367a20 with 1 txn prefilled, 4004 txn from mempool (incl at least 1 from extra pool) and 0 txn requested
2026-03-23T16:04:49.645486Z [msghand] [cmpctblock] Successfully reconstructed block 00000000000000000001f8562235e11fc74d5eea589e4c37b671b4213e89f52f with 1 txn prefilled, 4216 txn from mempool (incl at least 14 from extra pool) and 20 txn requested
Perhaps charterino, its dev is completely unaware of how the node’s behavior affects other nodes. Maybe someone should open an issue there to make him aware?
Thank you for bringing this up to my attention! murchandamus is correct, I was unaware of this. What do you guys think is the best thing for me to do here? Other than respond to GETDATA requests.
While I agree that a selfish-minnig attack might look similar on monitoring tools, I don’t think this was one. And if it was one, it was a poorly exectued one:
why briefly mine on AntPools and ViaBTC’s blocks?
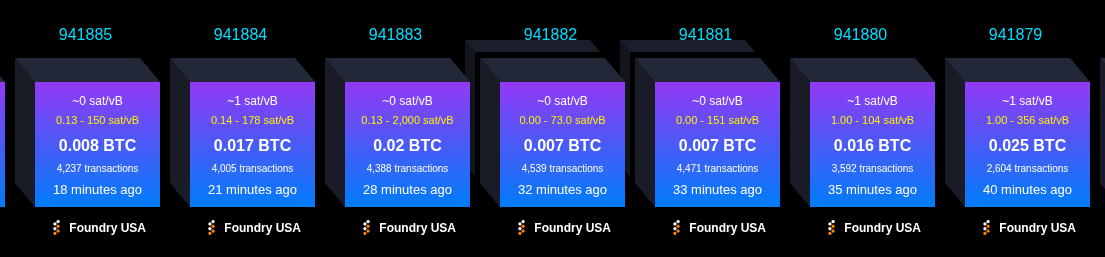
why reveal it to the world during a low fee period? The two reorged blocks made 0.008 + 0.017 BTC in fees.. This is a bad risk (of e.g. miners moving away) reward I would not take.
I guess if I’m wrong, then we are going to see it again soonish.
However, my main reason is the following: The data we’ve seen exactly matches the expected network and relay behavior. I’ve written a Bitcoin Core functional test that shows this.
To summarize some data:
We know Foundry uses preciousblock and we’ve seen them use it multiple times before in e.g. Mining Pool Behavior during Forks - and it’s a very reasonable thing to do, if you want to maximize profits.
We know the Foundry blocks didn’t propagate well. We had @matthias share a very valuable global network view on this in Two block reorg at height 941880 - #18 by matthias, we have Json Huge from OCEAN who said No DATUM miner on OCEAN ever built work on top of either Foundry block 941881 or 941882 (around a thousand globally diverse nodes) (https://x.com/wk057/status/2036674054971703361), and we have a bunch of monitoring nodes that didn’t see them either before we reorged.
This functional test mimics the event stratum job event order from 2), uses preciousblock 1), and checks that the header does not propagate further than one hop from the miner (and the block does not propagate at all) as seen in 3).
#!/usr/bin/env python3
# Copyright (c) 2022-present The Bitcoin Core developers
# Distributed under the MIT software license, see the accompanying
# file COPYING or http://www.opensource.org/licenses/mit-license.php.
""" Shows what nodes consider the tip during a two block fork where miners use preciousblock.
This is meant to explain the network behavior seen in:
https://bnoc.xyz/t/two-block-reorg-at-height-941880/97
- The two Foundry blocks didn't propagate well as they weren't seen first (here F881 and F882)
- Only a few nodes announced the Foundry blocks F881 and F882, but the headers weren't realyed
- The AntPool and ViaBTC blocks did propagate well as they were seen first
"""
from test_framework.test_framework import BitcoinTestFramework
from test_framework.blocktools import create_block
from test_framework.util import assert_equal
class TwoBlockReorg(BitcoinTestFramework):
def set_test_params(self):
self.setup_clean_chain = True
self.num_nodes = 4
def setup_network(self):
self.setup_nodes()
# Construct a network:
# minerA -> node1 <-> node2 <- minerF
# node1 is connected to minerA and node2
# node2 is connected to minerF and node1
#
# minerA to node1
self.connect_nodes(0, 1)
# node1 to node2 and node2 to node1
self.connect_nodes(1, 2)
self.connect_nodes(2, 1)
# minerF to node2
self.connect_nodes(3, 2)
def run_test(self):
minerA = self.nodes[0]
node1 = self.nodes[1]
node2 = self.nodes[2]
minerF = self.nodes[3]
self.log.info("Setup network: minerA -> node1 <-> node2 <- minerF")
self.log.info("Mining one block on node1 and verify all nodes sync")
# generate verify's that all nodes are in sync under the hood
self.generate(node1, 880)
# We start of at height 880. G is the Genesis block.
# G - ... - 880
assert_equal(node1.getblockcount(), 880)
assert_equal(node1.getblockcount(), node2.getblockcount())
assert_equal(node1.getblockcount(), minerA.getblockcount())
assert_equal(minerF.getblockcount(), minerA.getblockcount())
self.log.info("minerF starts working on a block block F881")
blockF881 = create_block(
hashprev=int(node1.getbestblockhash(), 16),
tmpl={"height": 881}
)
self.log.info("however, minerA beats it and publishes a block A881 and everybody sees it")
self.generate(minerA, 1)
# G ... -- 880 -- A881
# ^: minerA, minerF, node1, node2
assert_equal(node1.getblockcount(), 881)
assert_equal(node1.getblockcount(), node2.getblockcount())
assert_equal(node1.getblockcount(), minerA.getblockcount())
assert_equal(minerF.getblockcount(), minerA.getblockcount())
self.log.info("minerF finds the block F881, publishes it, and switches to it")
blockF881.solve()
minerF.submitblock(blockF881.serialize().hex())
# minerF is still on the minerA block, as it heard about this one first
assert_equal(minerF.getbestblockhash(), minerA.getbestblockhash())
minerF.preciousblock(blockF881.hash_hex)
assert_equal(minerF.getbestblockhash(), blockF881.hash_hex)
# We now have a fork.
# v: minerF
# /- F881
# G .. -- 880
# \- A881
# ^: minerA, node1, node2
self.log.info("Only node2, who is directly connected to minerF, has seen F881. It did not relay the header/block to node1")
chaintips_node1 = node1.getchaintips()
chaintips_node2 = node2.getchaintips()
assert_equal(len(chaintips_node2), 2)
for tip in chaintips_node2:
if tip["status"] == "active":
assert_equal(tip["hash"], minerA.getbestblockhash())
elif tip["status"] == "headers-only":
assert_equal(tip["hash"], blockF881.hash_hex)
assert_equal(len(chaintips_node1), 1)
assert_equal(chaintips_node1[0]["hash"], minerA.getbestblockhash())
self.log.info("Our node1 node is still on the A881 block, as it saw this one first")
assert_equal(node1.getbestblockhash(), minerA.getbestblockhash())
self.log.info("Again, minerF starts mining on a block F882")
blockF882 = create_block(
hashprev=int(minerF.getbestblockhash(), 16),
tmpl={"height": 882}
)
self.log.info("minerA finds block A882. node1 and minerF switch to it")
self.generate(minerA, 1)
#
# /- F881
# G .. -- 880
# \- A881 - A882
# ^: minerA, minerF, node1
assert_equal(node1.getbestblockhash(), minerA.getbestblockhash())
assert_equal(minerF.getbestblockhash(), minerA.getbestblockhash())
self.log.info("minerF finds block F882, publishes it, and switches to it")
blockF882.solve()
minerF.submitblock(blockF882.serialize().hex())
# minerF is still on the minerA block, as it heard about this one first
assert_equal(minerF.getbestblockhash(), minerA.getbestblockhash())
minerF.preciousblock(blockF882.hash_hex)
assert_equal(minerF.getbestblockhash(), blockF882.hash_hex)
# We now have a two block fork.
# v: minerF
# /- F881 - F882
# G .. -- 880
# \- A881 - A882
# ^: minerA, node1
self.log.info("Only node2, who is directly connected to minerF, has seen F882. It did not relay the header/block to node1")
chaintips_node1 = node1.getchaintips()
chaintips_node2 = node2.getchaintips()
assert_equal(len(chaintips_node2), 2)
for tip in chaintips_node2:
if tip["status"] == "active":
assert_equal(tip["hash"], minerA.getbestblockhash())
elif tip["status"] == "headers-only":
assert_equal(tip["hash"], blockF882.hash_hex)
assert_equal(len(chaintips_node1), 1)
assert_equal(chaintips_node1[0]["hash"], minerA.getbestblockhash())
self.log.info("minerF finds block F883, causing a two block reorg")
self.generate(minerF, 1)
# v: minerF, minerA, node1
# /- F881 - F882 - F883
# G .. -- 880
# \- A881 - A882
#
assert_equal(node1.getbestblockhash(), minerA.getbestblockhash())
assert_equal(minerF.getbestblockhash(), minerA.getbestblockhash())
self.log.info("minerF wins the fork race")
if __name__ == '__main__':
TwoBlockReorg(__file__).main()
TestFramework (INFO): PRNG seed is: 1283534758446118571
TestFramework (INFO): Initializing test directory bitcoin_func_test_k7vv6x4w
TestFramework (INFO): Setup network: minerA -> node1 <-> node2 <- minerF
TestFramework (INFO): Mining one block on node1 and verify all nodes sync
TestFramework (INFO): minerF starts working on a block block F881
TestFramework (INFO): however, minerA beats it and publishes a block A881 and everybody sees it
TestFramework (INFO): minerF finds the block F881, publishes it, and switches to it
TestFramework (INFO): Only node2, who is directly connected to minerF, has seen F881. It did not relay the header/block to node1
TestFramework (INFO): Our node1 node is still on the A881 block, as it saw this one first
TestFramework (INFO): Again, minerF starts mining on a block F882
TestFramework (INFO): minerA finds block A882. node1 and minerF switch to it
TestFramework (INFO): minerF finds block F882, publishes it, and switches to it
TestFramework (INFO): Only node2, who is directly connected to minerF, has seen F882. It did not relay the header/block to node1
TestFramework (INFO): minerF finds block F883, causing a two block reorg
TestFramework (INFO): minerF wins the fork race
TestFramework (INFO): Stopping nodes
TestFramework (INFO): Cleaning up bitcoin_func_test_k7vv6x4w on exit
TestFramework (INFO): Tests successful
The question for me is “Why did they stop mining on them?” Maybe they received a “late header” from their miner but had not yet validated the block for the “foreign” header, so they go with the first block they can validate. Maybe the reason Foundry’s blocks 1 and 2 were so late in being seen is because most nodes had validated the other blocks before seeing them.
If this is the case, then the rules aren’t strictly following proof of work which means “the partition with the highest hashrate”. We’re following “proof of fastest block validation”. To strictly follow proof of work, both headers should be relayed and mined equally by each miner who receives them immediately from the same peer, or within half a typical network propagation delay from different peers, until both blocks have had “sufficient” time to be transmitted and validated. If that estimated time has not passed, other miners continue working on the header that came first even if the other header’s block can be validated. In this way, the partition that had the highest hashrate wins.
The timestamp differences are less than 1/2 the standard deviation of their accuracy, so they can’t be used to make a determination.
The link didn’t seem to indicate @murchandamus concludes it was normal network behavior.
With only 33% hashrate and apparently not getting much help from other miners, Foundry can’t expect to profit from it being a selfish mining attack (at 33% it would be break even for “gamma=0”).
In the case where your pool is competing with another pool in a block-race, you want to be mining on your own block. Let’s play the scenario through with an example:
Imagine you’re a pool with 1% of the hashrate and you just found a valid block, but know that the other 99% of hashrate just switched to another block found by a competing pool.
Case A: You mine on the competing block and give up on your own block. The chance of you finding the next block are 1%. You can gain the block reward of that next block, if you find it.
Case B: You mine on your own block (e.g. by switching to it via preciousblock) and ignore the competing one. Your chance of finding the next block is still 1%, however if you do, you get the reward from your previous block and the next one.
Case B is strictly better for a pool. No matter the odds.
I guess @murchandamus might chime in at some point, but to quote him a bit from that link:
However, if the timestamps are accurate, it is possible that Foundry found both of those blocks just after the competing blocks were found, before they had learned about the competing blocks, but after their block would have propagated widely on the network.
It could perhaps even be the case that the block was found by a pool participant even after Foundry saw the Antpool block, but before they had updated all the jobs. It would still make sense and not be malicious for a pool to mine on their own block when they have one.
As I mentioned above, Bitcoin Core nodes will request and store blocks in competing chaintips with the same PoW as their best chaintip, but they will not announce those blocks to their own peers. Even if Foundry had announced it after having found it, the block could have not made it beyond the Foundry nodes’ peers if they all had seen the competing block before it, or it would have possible made it another hope from a few peers before getting blackholed.
Thanks for these details. So, it’s not a huge leap to say that it was mostly a coincidence that some nodes didn’t see Foundry’s blocks until after the reorganization?
I think that it is plausible, yeah. And if we’re honest, Bitcoiners tend to entertain conspiracy theories perhaps a little to enthusiastically.
I completely missed that, but it works the same as a selfish mining attack. It’s not following proof of work, i.e. mining on the partitition with the highest hashrate. The pool knows which block came first and it knows the majority hashrate isn’t working on his “private” block.
Murch doesn’t seem to “conclude it was” an accident, but shows it could have been. But an accidental delay in getting new jobs out to workers works the same as a selfish mining attack. We can’t know if a pool does it on purpose or not. The pool only has to “accidentally” delay getting new jobs out to workers for it to be a purposeful attack. Another tactic is to “accidentally” delay releasing a block, or for the 2 largest pools to make sure they have a faster connection to each other than to the rest of the network. For example if they are 50 ms apart instead of the median of 500 ms, they gain 0.45/600 = 0.075% excess rewards.
To reiterate what I said before, selfish mining is possible only because timestamps aren’t enforced more accurately than MTP and FTL. It’s not a clever attack as much as it’s the result of not following strict proof of work rules, i.e. staying on the chain that has the highest hashrate since the last block, which requires checking to see if the timestamps are reasonable compared to typical network delays in the manner I described.
I’d say it would be helpful to only INV blocks that you can actually provide. Ideally answering GETDATA requests, or if that is an issue for some reason, not sending INV for those blocks in the first place. That being said, the Bitcoin Core behavior should be improved too (e.g. by lowering timeouts or allowing to download from another peer if there is a staller), which is being discussed in Seemingly second (very long) validation at the same height · Issue #33687 · bitcoin/bitcoin · GitHub
Nice analysis. Thanks for continuing to dig into this. About foundary blocks not propagating well, is it possible to see stats on time it takes for blocks from different pools to propagate? You probably have this already somewhere
I’m not sure whether that was the question, but yes, it seemed to me that there were innocuous explanations why we saw that two-block reorg, but I didn’t have enough data to make any confident determination. Per the data that b10c has provided since, it seems to me that Foundry indeed found their blocks slightly after the competing blocks, but decided to mine on their own blocks while the chaintips were tied which seems completely reasonable.