What should the RBF rules be in a cluster-mempool implementation? I originally proposed a heuristic involving a new transaction and its conflicts that I thought would be incentive compatible. Another option is to define a measure on the mempool that we try to optimize.
Potential ways of evaluating an RBF
Heuristic proposal
My first proposal of a heuristic for an RBF is to (a) require that the new transaction have a higher mining score than that
of any transaction which would be evicted, and (b) require that the new transaction have a higher total fee than that of
all transactions being evicted.
To implement this, we have to calculate all conflicts (including descendants of direct conflicts), and then construct the
cluster for a candidate replacement, linearize that cluster, and from there we get the new transaction’s score. We can compare
that score to that of the conflicting transactions (which are cached in the mempool) to test whether the heuristic is met.
Mempool metric
An alternative approach would be to ensure that the the mempool that would result from a replacement is
strictly better than the current mempool.
To define strictly better, we consider the mempool fee vs. size diagram that we construct by looking at the accumulated size and accumulated fee of each in-mempool chunk, when we sort the mempool’s chunks by chunk feerate. We can compare two diagrams A and B by checking, for each diagram, whether each (size, fee) data point is contained within (or along) the convex hull of the points in the other diagram (that is, connect each pair of successive points in diagram A with a straight line, and test
whether the chunk (size, fee) points of diagram B are inside, outside, or along the lines of diagram A; then repeat in the opposite direction). In this way, two diagrams can be equivalent (if all points of each are along the lines of the other), or
they can be incomparable (if each has points that lie outside the other), or one can be strictly better (if exactly one diagram contains points that are outside the other diagram).
Example fee vs. size diagram from a live mempool (truncated to first 25 chunks):
With this in mind, we can define an RBF validation strategy by requiring that the new mempool that would result must be strictly better than the current mempool. To do this, we’d first determine the clusters affected by the replacement (ie the
clusters containing all the conflicts and the cluster(s) that the new transaction would join); we’d calculate the fee vs size diagram for the chunks in those clusters; we’d simulate removing the conflicts and adding the new transaction, and re-cluster/re-linearize those clusters; we’d compute a new fee vs size diagram for the resulting clusters; and finally we’d compare them to see if the new diagram is strictly better.
Discussion
Ultimately the intuition behind the heuristic is to implement something simple that would capture the improvement described
in the mempool metric. However, it turns out that even with an optimal cluster sort, the heuristic doesn’t guarantee that
the resulting mempool will be strictly better than what it replaced.
Example of heuristic-based rbf not strictly improving the mempool
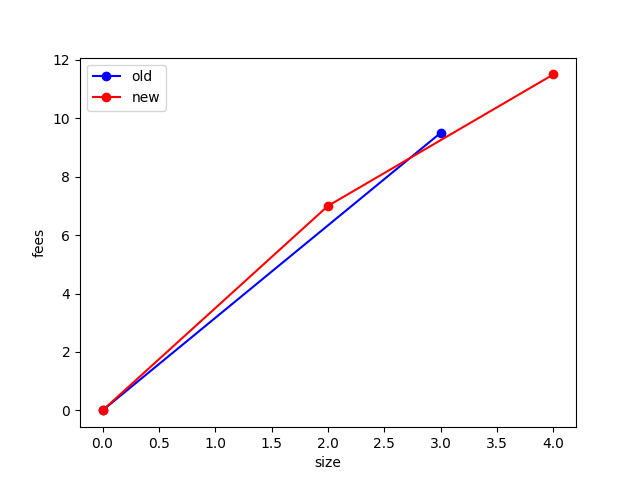
All transactions are the same size (say, 100 bytes), and the numbers indicate feerate in sat/byte:
In this graph, the optimal sort is [A, B, C],[D] (brackets indicate chunks). The first chunk has total (size in bytes, fee in sats) = (300, 950), while the second chunk is (100, 100). (See below for the fee vs size diagram.)
Now consider an RBF that replaces tx C with tx E, as follows:
The optimal sort of this new mempool would be: [D, E], [A, B]. The score of E is 700/200 = 3.5sat/byte, which
is higher than the mining score of C before the replacement (3.17 sat/byte). Also, E pays more total fee than C (600 > 500).
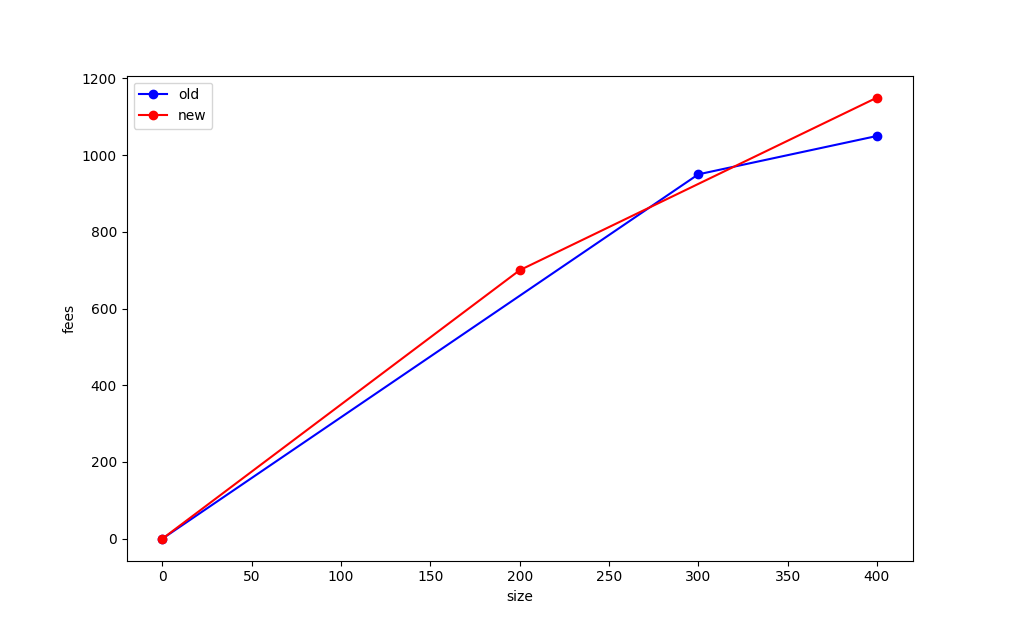
So this replacement would pass the heuristic. However, the fee vs. size diagram for the new mempool (after replacement) has points (200, 700) and (400, 1150). Let us now compare the old and new mempool diagrams:
Note that the (300, 950) point from the first diagram lies outside the diagram for the new mempool, and so the replacement under these rules did not make the mempool strictly better.
Mempool metric
A few questions arise after seeing this example:
Is there a simple way to understand why the mempool might not be strictly better off based on the heuristic, and can we add a simple rule that would eliminate the possibility?
If not, should we instead just use the fee-size diagram test as our RBF validation metric? Engineering this correctly will be annoying to do, particularly if we want to avoid linearizing the same clusters multiple times, but fundamentally this shouldn’t be an operation that is too slow.
Does the fee-size diagram actually capture the right idea? For instance, would using this as our test allow for more pinning vectors than we have today? How can we reason about what is happening?
I’m working on a feerate diagram comparison implementation for (single transaction) RBF and thinking through the constant factors:
The number of different clusters that a single transaction can conflict with will govern how many chunks we have to consider in the feerate diagram comparison.
In theory, the number of such chunks is bounded by # of clusters * # of transactions in each cluster, and the feerate diagram comparison test is linear in the number of chunks that form the two diagrams.
So if we permit a transaction to conflict with 100 in-mempool transactions, and if we permit each cluster to have up to 100 transactions, then we’re looking at 10000 potential chunks to iterate. That seems like it could be slow.
We’ve also previously discussed getting rid of this limit on number of conflicts, and replacing it with the number of clusters that would need to be relinearized. I’m no longer sure we’ll be able to do that, given this new proposed validation logic.
Are there any tricks we can perform to bring these numbers down?
Yeah my only point is that if we get rid of the bound on the number of conflicted transactions altogether, then we are effectively removing the bound on the number of elements in a diagram check (or limiting it to whatever the max number of inputs you could fit into a standard transaction multiplied by the cluster count limit).
So in this case, we might have to bring down the maximum number of transactions in a cluster as our only lever to cap the amount of work we might have to do…?
An O(n) operation on two sets of 10k pairs of int64_t seems pretty fine? (Maybe add a log(n) factor to combine the clusters) You might need to be clever about generating the set of new clusters efficiently, based on the original set and the conflicted/new transactions, rather than doing it from scratch though?
The O(n^2) step to re-optimise the new chunks has to be performed per cluster (ie, it’s O(bc^2) where b is number of clusters, and c is chunks per cluster), so limiting the number of clusters that can be conflicted with would make sense. Affecting many clusters without actually combining those clusters as a result of the RBF seems like it would be unusual behaviour, too?
Well I have no idea whether this would be unusual or not, but if you generated a bunch of small transaction chains, and then did a single RBF to batch them into one transaction, then you might exactly get this behavior where you are eliminating a bunch of existing clusters in favor of a single new one.
In practice, I think the fees grow so large when conflicting with lots of transactions that this is probably not something that comes up very often, but people have brought up esoteric rbf pinning vectors in the past, so I just want to not preclude something from happening unless we have a specific CPU concern we’re dealing with.
If you limit the number of allowed clusters to touch but dropped the ancestor count limit (leaving it implied by the chunk limit), you could get a weird scenario:
Suppose you have a CPFP arrangement to pay for a bunch of txs:
graph TD
P1 --> C
P2 --> C
Pn[P3..P10] --> C
But then you realise there’s another 20 txs you want to CPFP, so you RBF C as:
graph TD
P1 --> C
P2 --> C
P3 --> C
P4 --> C
P5 --> C
Pn[P6..P30] --> C[C2]
You repeat this until you hat max chunk size:
graph TD
P1 --> C
P2 --> C
Pn[P3..P99] --> C[C6]
And that all works fine: you’re merging 21 clusters with C2, another 21 clusters with C3, C4 and C5 and a final 10 clusters with C6.
But what if you didn’t see C2, C3, C4 or C5, but had seen P11…P99? C6 alone would look like it was merging 90 clusters, which would presumably be more than the allowed cluster limit. So the rbf from C1 to C6 becomes path dependent: doing it directly fails, but doing it indirectly works.
Yeah that’s kind of annoying in how order-dependent it is, without any external actions by griefing parties.
Another metric could be number of total txs in effected clusters.
f.e. We continue to evaluate an RBF if the number of effected clusters is <= 100 AND number of total effected transactions in effected clusters is <= 2,500.
Would allow “simple” CPFP patterns like @ajtowns writes above up to cluster limits, and still bound the diagram checks? In adversarial case, someone could still package RBF/CPFP ~25 separate clusters, assuming each thing being bumped was part of a max size cluster.
Maintaining the ancestor limit and having it equal the affected clusters limit would let you do simple CPFPs without worrying about RBFs – anything after C2 paying for P1…P24 would just be non-standard due to the ancestor limit that way, no matter the order.
I don’t think this scenario poses a problem (but maybe there’s another that does). Originally there were two different limits that I had been thinking about:
A limit on the size of the cluster that a new transaction would be part of (eg 100 transactions). For both RBF and non-RBF situations where a transactions is added to the mempool, we test that the size of the resulting cluster is not too big. I think that in this example C6 is fine no matter what path of transactions is followed to get there.
Some kind of limit on the number of clusters that a new transaction could conflict with. This could be a few different things: (a) just a cap on the number of direct conflicts; (b) a cap on the number of transactions that would have to be evicted (ie both direct conflicts and their descendants); (c) a cap on the number of linearizations we’d have to perform in order to accept a transaction (ie counting the number of clusters that need to be linearized after all conflicts are removed and the replacement transaction is added).
In this example, I don’t see how any of these proposed limits (2a, 2b, or 2c) would pose a path-dependence where seeing more RBFs makes C6 easier to get in.
Edit: Forgot to add – in practice I think we can treat 2c as being limited by 2a, in that if we have at most N direct conflicts, then we have at most N+1 linearizations to perform when adding the replacement. This is because descendants of direct conflicts are always in the same cluster as the direct conflict, so we clearly have at most N clusters containing transactions that would be evicted. Also, even if an eviction causes a cluster to split, I think it’s fair to say that the polynomial/exponential run-time of the linearization algorithm means that the cost of linearizing a cluster split into k parts is less than k times the cost of linearizing the unsplit cluster, so we can ignore that effect.
You get the same thing if Pn had previously been CPFPed for by different transactions Xn (C2 conflicts with each Xn due to spending the same output of Pn):
where C2 conflicts with C1, X11…X30; C3 conflicts with C1, C2, X11…X50. Then you hit 2a and 2b if they’re below 40 when you go C1 to C3, but not if you got C1 then C2 then C3 (assuming you have C1, P1…99, X1…99 in your mempool initially).
I think as far as linearisation goes, the issue is you need to:
create a diagram for the relevant clusters from original mempool: easy, O(n\cdot \log(c)) where c is number of clusters, n is number of txs in the clusters
create a diagram for the post RBF mempool:
keep all the old clusters; removing any conflicts. don’t worry if they’ll end up splitting
create a new cluster for the new tx(s); move all related txs from all clusters
linearise this new cluster
combine what’s left from the old clusters and the new cluster into a single diagram
compare it
So I’d only count that as “1” linearisation, though you’d probably want to re-linearise all the old clusters you touched after you’ve decided to accept the RBF before you update the mempool?
The algorithm you describe is exactly what I’m trying to do (so that’s good!). But when calculating the feerate diagram for the post-RBF mempool, you omitted the re-linearization of all the old clusters that are affected by evictions – I don’t think we can do that?
just remove the conflicts and related txs and rechunk what’s left of the old clusters, without relinearising O(n)
combine those chunkings to produce a new diagram and compare it with the current diagram O(n\log(c)). if the diagram’s not better, throw it away, reject the RBF, all done
if it is better; split and re-linearise the old clusters, and update the mempool O(\frac{n^2}{c})
Relinearising before comparing the diagrams would make RBFing slightly cheaper/easier in complicated cases, but I don’t think we need to do that, and deferring the O(n^2) steps until we know we’re doing something to improve the mempool seems worthwhile?
I think that if we don’t re-linearize what is left of the old clusters, that we might open the door to some RBF pinning scenarios that otherwise wouldn’t exist.
Imagine you are doing an RBF where you are swapping out one low fee parent with another. Old tx graph (feerates in parens, all txs same size):
Assuming B’s feerate is going up, then if we didn’t relinearize the cluster containing A, the mempool chunks we’d get from this graph would have feerates: [(R(B)+1)/2, 5, 1]. If you were to relinearize, you’d instead get [(R(B)+1)/2, 9, 1, 1].
Using the feerate diagram test as our RBF metric, if we don’t relinearize, then I think you could just increase the size of P2 (and leave it at the same feerate) in order to increase the feerate required for B to be accepted. Not sure exactly what the mathematical relationship is, but this strikes me as a bad outcome?
Update:
I did a quick check to see how high I could get the required feerate of B based on the (a) size of P2 (holding feerate constant), and (b) the feerate of P2 (in the range of 1-9), assuming we do/do not relinearize the old cluster when processing an RBF.
Changing P2’s size, fixing P2 at feerate 9:
P2’s size
Min fee bump with relinearization
Min fee bump without relinearization
1
1
4
2
1
6
3
1
6
4
1
7
8
1
8
9 & higher
1
8
Changing P2’s feerate, fixing P2 at size 1:
P2’s feerate
Min fee bump with relinearization
Min fee bump without relinearization
1
1
1
4
1
2
6
1
3
8
1
4
My conclusion from this is that we ought to relinearize the old clusters, to avoid artificially increasing the fee bump needed due to unrelated transactions like P2 (and X, which is the only reason that P2 is relevant in the graph).
(Not sure where else to put this, but wanted to log this somewhere)
I was thinking about Cluster size 2 package rbf by instagibbs · Pull Request #28984 · bitcoin/bitcoin · GitHub, and realized just now that the RBF rules there for the cluster-size-2 case has the same sort of problem that I brought up here, with regard to the RBF heuristic not quite lining up with the feerate diagram test that we’d like to use in the future.
Issue 1: The feerate diagram might not improve using the rules described in #28984.
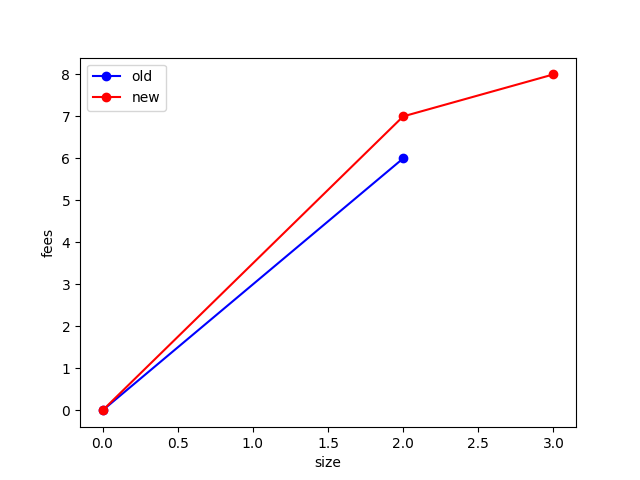
This is similar to the example posted above. Imagine the starting mempool is:
Using the heuristic in the PR, we’d say the package feerate of (C, D) is 3.5, which is greater than the ancestor feerate of B (9.5/3), and the total fee of (C, D) is 7, which is more than 5.
However the feerate diagram does not strictly improve:
Issue 2: The rules proposed in #28984 might be satisfied when validating a package (A, B), but might fail to successfully relay if A is valid in a peer’s mempool and then B is evaluated using legacy RBF rules (as a singleton RBF).
Consider the same situation as above, but with feerates such that the package would pass validation rules (this could be accomplished by raising the fee for tx D sufficiently high).
Now suppose that tx C would relay to our peers, because it has a high enough feerate that it passes the mempool min fee and minrelayfee. Then using submitpackage (or package relay) to get (C, D) to our own node might still result in tx D failing to propagate, because once tx C propagates, then attempts to relay D will trigger the old RBF rules, which (in particular) prohibit an RBF that introduces a new unconfirmed parent.
So it would seem that to make package RBF of (C, D) useful, users would need to ensure that C would not relay on its own (eg by making its feerate below the minrelayfee).
Issue 3: In the new cluster mempool world, the feerate diagram might be satisfied for a transaction package (A, B), but fail to relay successfully if A is valid in a peer’s mempool and then B’s RBF attempt is validated using feerate diagram rules (which can fail because the starting diagram for a peer might include tx A).
It turns out that the feerate diagram test might not be strictly improved if we are able to break up a transaction package into its parts.
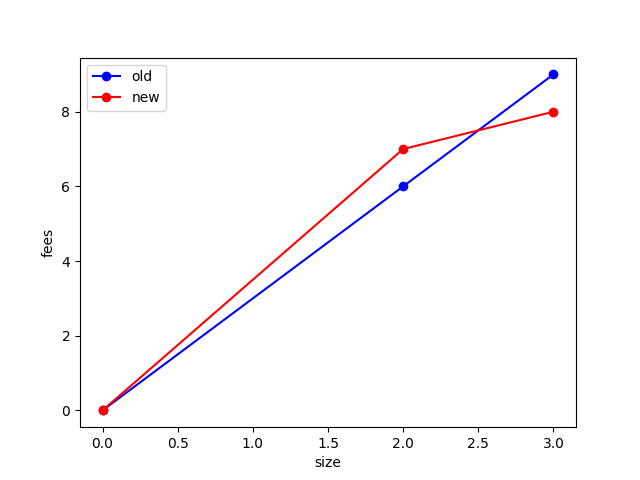
Consider this starting mempool, all transactions are the same size:
graph TD;
A[Tx A: fee 1]-->B[Tx B: fee 5]
And we are considering a new package (C, D) where D conflicts with B, which would bring the mempool to this:
This would pass the feerate diagram check if (C, D) is evaluated as a package against the starting mempool:
However, if tx C were to relay on its own (it has no conflicts, so this is plausible), then the feerate diagram check for tx D versus a starting mempool of (A, B, C) would fail:
[EDIT: just realized the total fee didn’t go up, which is perhaps not a great example.]
Noting up front that these scenarios are what I’m calling “cross-sponsor” RBF, where the funding tx is sponsoring on package, then switches over to sponsor another parent. Typical example for a wallet would be they’re CPFPing something with a nice sized utxo, then another package becomes higher priority and they want to switch.
I don’t think it should be shocking miner scores isn’t strictly improving the mempool. I’m also unconvinced it’s worth stalling out limited package rbf given the current state of the art, which is substantially worse.
At the risk of re-adding a pin, changing the heuristic to:
for all direct conflicts, package feerate must exceed direct conflict’s feerate
for all conflicts(direct or indirect), package feerate must exceed ancestor feerate of conflict
Wallet authors can avoid this in a fairly simple manner, by not “cross-sponsoring”. If they do, make it a 0-fee parent package via v3/ephemeral anchors, but note that if a counter-party has already sponsored the package, cross-sponsoring will still be disallowed since parent will still be in the mempool. Post-cluster mempool this issue goes away (except the mild pinning as you note in issue 3?)
Don’t have anything intelligible to say about issue 3 yet other than it’s interesting!
Seems like per-chunk processing allows for a mild “parent pays for child RBF”. The “cost” of doing per-chunk evaluation: people may be making cpfp chains one by one, and this will not be in lock-step with a whole package being gossiped at once. #26711-like solutions mean you get less of this asymmetry, at increased cost of complexity, and not always dealing with chunks.