A Node can get a fee estimate by generating a block template from mempool transactions, using the fee rate of the transaction/package at the 50th percentile[0] of the generated block weight as the fee rate estimate k for the next block.
Creating a new transaction/package with the same fee rate as k will align it with transactions/packages in the block template and will likely be included in the next block when propagated in the network.
Relevance of mempool-based fee estimation.
It is assumed that most miners are generating block templates they intend to mine next from their node’s mempool[1]. Hence placing a bid using mempool-based fee estimation puts the transaction/package in the same rank as the transactions/package in the block template miners are processing and will most likely be included in the block.
As such, if your mempool is roughly in sync with miners this is the most accurate method of ensuring your transaction gets mined in the next block.
It quickly reacts to changing conditions when the mempool is full due to high block confirmation time or the user’s mempool becomes shallow.
Instances where mempool-based fee estimation falls short.
When a node’s mempool diverges with the network miners’ mempool, assumptions will be wrong and lead to inaccurate results.
This will happen due to the policy rules[2] of the node.
The peers connected to a node, i.e. how well connected the node is in the network to get information on all the transactions being broadcasted in the network.
If miners are accepting most of the transactions they mine via other means than the P2P network, users’ mempool will not be roughly the same as miners.
The mempool-based fee estimate for confirmation target > 1 is unreliable due to mempool changing conditions.
When the confirmation target is > 1 block in the future the mempool conditions will likely change e.g. high confirmation time, high demand for block space. Assertions made on the miner’s block template previously will not hold.
The node might be accepting some transactions that miners might not accept into their mempool due node’s lax policy rules[2] and this will mess with their estimate.
How do we know if a node’s mempool aligns with the network or not?
By adding sanity checks that will serve as indications of whether a node is roughly in sync with miners in the network or not based on previously mined blocks and the transactions that are in the node’s mempool at the time the previous block was mined.
Whenever we suspect that a node’s mempool diverges from miners we prevent the node from getting a fee estimate.
We can do this by checking if most of the transactions in previously mined blocks were present in the node’s mempool when the target block arrived.
Check if the node’s mempool high mining score transactions are getting confirmed.
We can count the number of times we had expected a mempool transaction with a high mining score to confirm and it did not, if its count value reached a certain threshold we prevent considering the transaction when generating a block template, it’s most likely that miners don’t consider this transaction.
These sanity checks are based on the past blocks and past mempool; they will not accurately tell us that the node’s current mempool is likely the same as miners.
The checks only give some confidence that if previously our mempool was roughly in sync with miners then we can use it for fee estimate because it’s most likely the node is widely connected and maintains sane policy rules that are alike with miners, and the network miners are also picking from the broadcasted transaction in the network. That might not always be true. I can’t think of a scenario when it will not be true.
The challenge of mempool-based fee estimation Implementation above.
Performing these sanity checks requires that immediately after a new block is connected we build a block template[3] we are expecting before evicting the block transactions from the node’s mempool, building a block template has roughly O(n*m) (n is the total mempool transaction and m is mapModified transactions) which might take some time and we don’t want any expensive code execution at that code path as it will slow block propagation in the network.
Post cluster mempool, we will have a total mempool ordering, enabling getting the block template in linear time. Hence getting the expected block template after a new block is connected is not expensive.
Is it worth adding this feature?
We can have an RPC with this estimation mode that users can manually use as the fee rate of their transactions/packages. Subsequently, in the future, we can automate it in the wallet if it is deemed to be reliable.
Cluster Mempool is still a work in progress, What is the way Forward?
CBlockPolicyEstimator[4] is the current fee estimation being used by Bitcoin Core and its dependencies which has known issues[5] of Overestimating / Underestimating fee rates and in some cases making transactions become stuck in the mempool due to inaccurate estimates.
We can have a mempool-based fee estimator without any sanity check, available from an experimental RPC that can be used by node users with caution. and then add the sanity checks upon deployment of Cluster mempool.
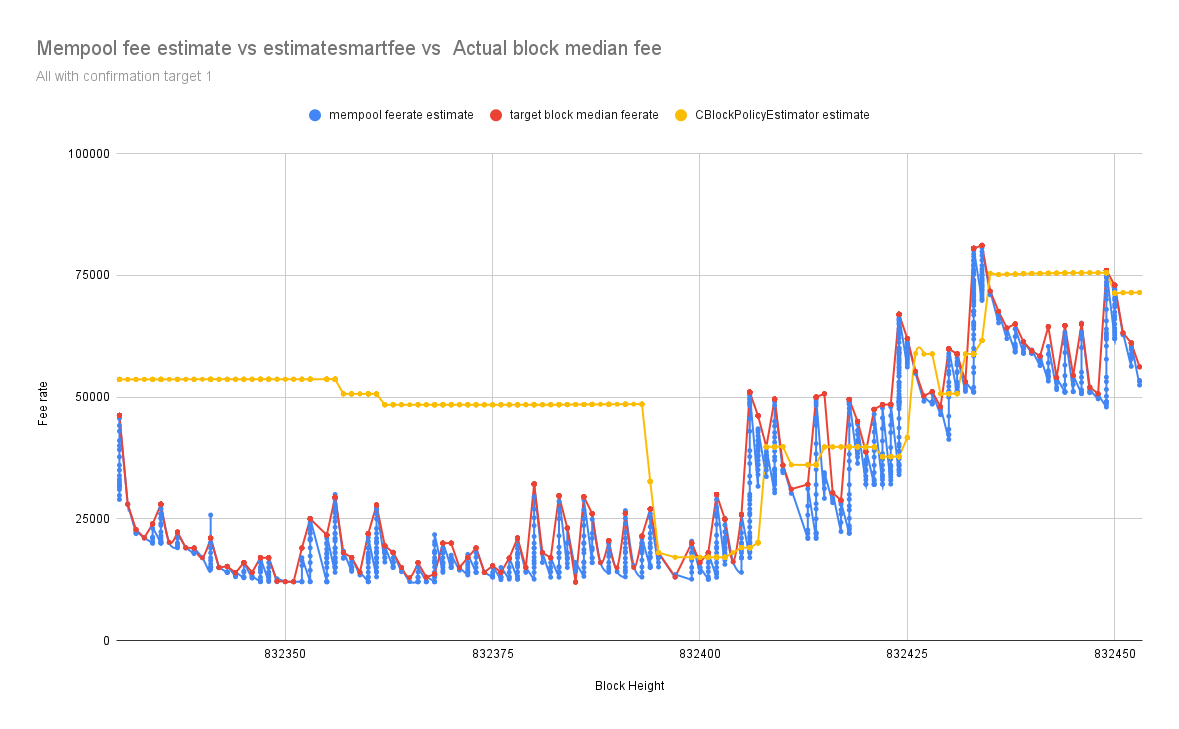
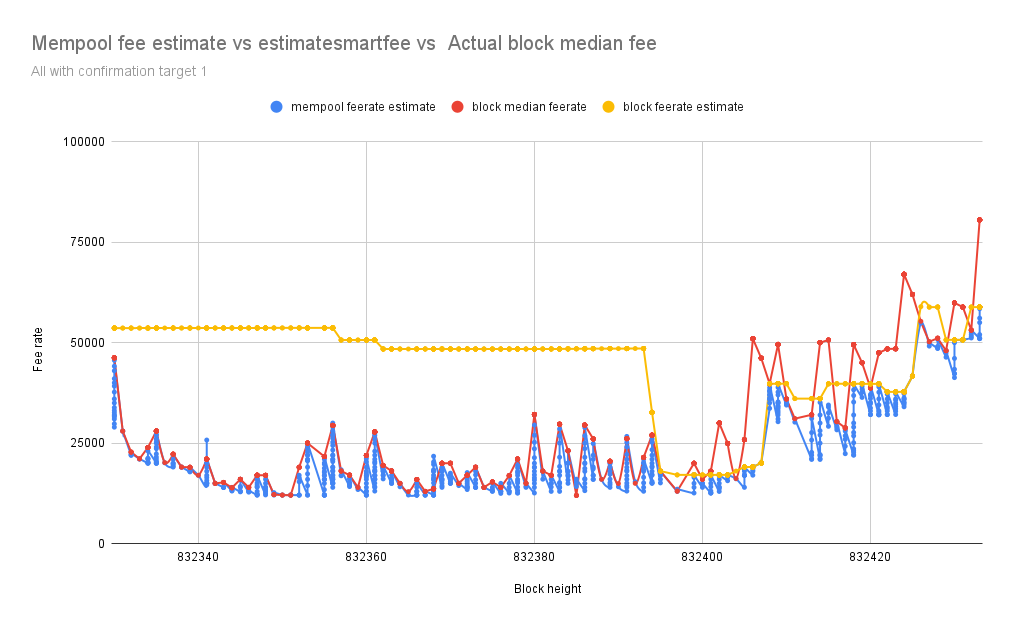
I have been analyzing the disparities between fee estimates of the mempool-based fee estimator without sanity check, CBlockPolicyEstimator[4], against the confirmed block target median fee rate.
Methodology
I’ve implemented a mempool-based fee estimator without any sanity check, made it available in an RPC, and schedule a job that logs the fee estimate from mempool, CBlockPolicyEstimator[4] estimatesmartfee after every one minute with confirmation target 1, then when the target block is confirmed its median and average fee rate are also logged.
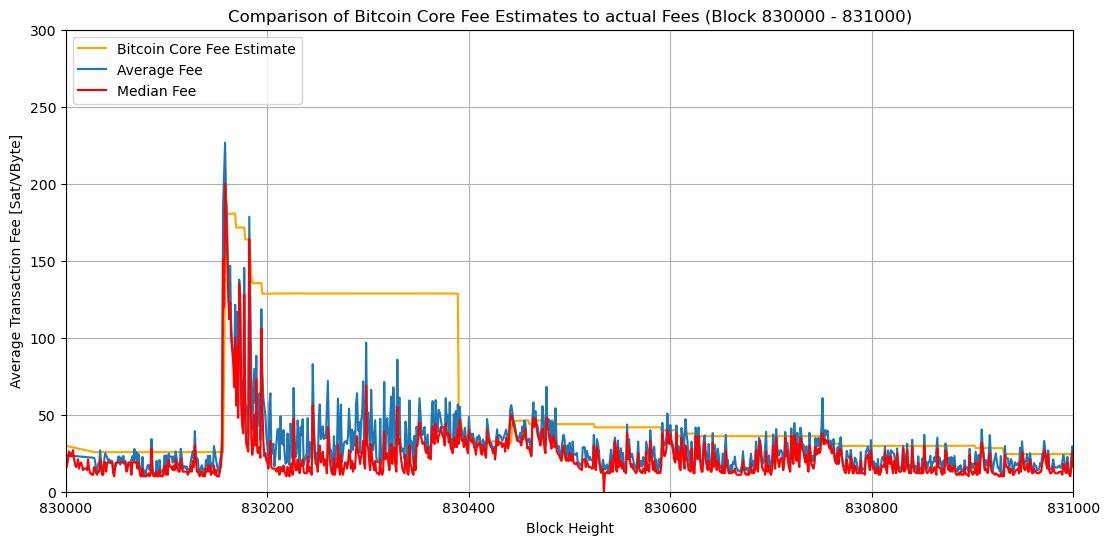
My node runs from 832330 to 832453, after that using a simple Python script I filter through my debug.log and collect all the fee estimates and the confirmed block target median and average fee rate to make a comparison.
The chart below represents fee estimates with mempool in blue and estimatesmartfee in yellow, and the block median fee rate in red consecutively every one minute from Block 832330 to 832453
From the data above fee estimation with mempool is closely following the block median fee rate, more accurate than CBlockPolicyEstimator[4] estimatesmartfee.
You can make a copy of the sheet and mess around with the chart data range to see the difference.
You can also build the branch and call estimatefeewithmempool and make a comparison with mempool.space and the target block median fee rate that will be logged.
This is a joint work with @willcl-ark , I appreciate @glozow 's input on some of the ideas above.
One of his points I recall finding particularly insightful was that, for anyone in a position to RBF, we can simply choose a feerate that is min(confirmed_estimate,mempool_estimate) where confirmed_estimate is based on non-gameable data (like the existing Bitcoin Core estimatesmartfee) and mempool_estimate is based on mempool stats like you describe (which has the risk of potentially being gameable and might also break accidentally, such as after a soft fork).
Using the minimum of the two returned values allows the feerate to adapt downwards very quickly without introducing any new risk that feerates could be manipulated upwards by miners or other third parties. If people only use the enhanced estimation for cases where they can RBF, then they can always fee bump if they end up underpaying. (Though it’s worth noting that RBFing has non-financial costs: it typically leaks which output is the change output and it requires the fee bumper either be online to bump or create presigned incremental fee bumps.)
Nice work and very interesting direction. I think that an approach combining the state of the mempool with information gathered from the blocks themselves could work significantly better than the current fee estimation.
As the block will be mined in ~10 minutes, the block template can change significantly. Do you have some estimate on the number of transactions that wouldn’t make it in to the block eventually? Some fee rate estimates in the graph look low.
Do things change significantly if you choose the bottom 25th percentile?
What do you suggest to do in this case? I think that involving information from the blockchain itself to make the estimation better can help.
Thank you for the link I find the ideas very insightful
we can simply choose a feerate that is min(confirmed_estimate,mempool_estimate)
The issue with the approach you mentioned is that we will be adapting downwards towards lower estimates, especially in cases where previously mined blocks have lower fee rate. Instead of adapting to the current mempool state, we will be providing a low fee rate estimate.
I try modifying the current data to give provide min(confirmed_estimate,mempool_estimate).
It is underestimating as expected, this will prevent the current overestimating of CBlockPolicyEstimator but the problem of underestimation will still be relevant.
mempool_estimate is based on mempool stats like you describe (which has the risk of potentially being gameable and might also break accidentally, such as after a soft fork).
I believe the checks we will have in place could prevent a node from using this estimation mode in the case of soft forks.
One scenario where miners could manipulate the mempool and cause congestion is by mining empty blocks or deliberately refraining from mining for some time to congest the mempool and make fee estimate spike up. However, assuming mining is decentralized, this scenario will not hold? Are their other instances ?
Yes, indeed, they are low because in ~10 minutes after a fee rate estimate, if there is a high inflow of transactions, there is a likelihood of transactions getting bumped out by other transactions with higher mining scores. If you estimated the fee rate with the 50th percentile of the block weight, and the weight of new transactions in the mempool with higher mining scores is > 4000000/2, then it’s most likely that your transaction will be bumped out and will not be mined in the next block.
You would have to make a new fee rate estimate and RBF bump the transaction in this case.
We could also use the top 25th percentile to reduce the likelihood of getting bumped out; and also reduce the low estimates.
Yes I think it will lower the fee rate estimate! and the potential of getting bumped out is higher in this case.
In this case, the sanity checks will indicate that we are not in sync with miners and we will not use this estimation mode, we could just fall back to CBlockPolicyEstimator?
Miner Mallory creates (but does not immediately broadcast) several large and high-feerate transactions, {A, B, C, …}. She also creates (but does not broadcast) a minimal-size, zero-fee transaction that conflicts with all her previous transactions. She includes the conflicting transaction in her block templates. She eventually mines a block containing it but does not immediately broadcast that block. Instead, she immediately broadcasts her large original transactions, waits a few seconds, and then broadcasts her block. Users receive the transactions first, increase their feerate estimates, and some of those users in those few seconds broadcast high-feerate transactions that remain valid even after Mallory’s block propagates. The entry of those user’s high feerate transactions into the other node mempools potentially results in later users choosing high feerates, magnifying the effect.
This is a variant on a Finney attack. It’s a contrived example at present as it requires Mallory risk losing an entire block reward, of which the subsidy currently dominates. But in the future when fees dominate, it may be worth it for moderately large (but non-majority) miners to risk a small chance of losing a block reward for the opportunity to increase fees by a significant percentage. A longer-range version of this attack would use selfish mining.
More generally, I think we need to be aware of the feedback loop between current fees, fee estimates, and future fees. An algorithm that lowers feerates too aggressively will receive negative feedback from the transactions it produces not getting mined. For anyone who can fee bump their transactions without too much inconvenience, that’s probably ok. An algorithm that raises feerates too aggressively may receive positive feedback from seeing its high feerate transactions getting mined, resulting in it returning even higher and higher feerate estimates until it hits the external limit of many people being unwilling to send transactions with such high feerates. That’s less ok, both because people can’t practically lower their feerates if it becomes apparent that the market is overbid and because any miner who can trigger overbidding may be able to profit.
I’m not saying that we should never use mempool information to raise feerate estimates, just that I think it’s lot easier to make the case that lowering feerate estimates based on mempool information is safe for people who can easily and cheaply fee bump.
Thank you, @harding, for guiding me through the scenario. I contemplated only considering a transaction for fee estimation after a certain period of broadcasting t that will make the attacker risk loosing money to other miners, but it seems that even this approach could be susceptible to the selfish mining variant.
Implementing a mempool-based estimate with the threshold of CBlockPolicyEstimator would mitigate this risk of the attack you mentioned, and reduce overestimation a lot, and I rightly believe is an improvement to current status quo.
However, in cases of underestimation, fee bumping may not offer the best user experience. But, the tradeoff seems justified by the threat posed of this attack vector.
When a transaction has been unconfirmed for a while and it seems fee bumping is necessary, with the proposed design if you estimate fees it might still be underestimated because of the threshold. Presently, users often rely on external services to assess the state of the mempool which is more risky in terms of being artificially manipulated to inflate fee rate estimates.
Could we introduce a verbose option to this that allows users to view the mempool state of their node? Users can use this data for decisions when fee bumping and then integrate the mempool-based fee estimate with the CBlockPolicyEstimator threshold into wallet operations?
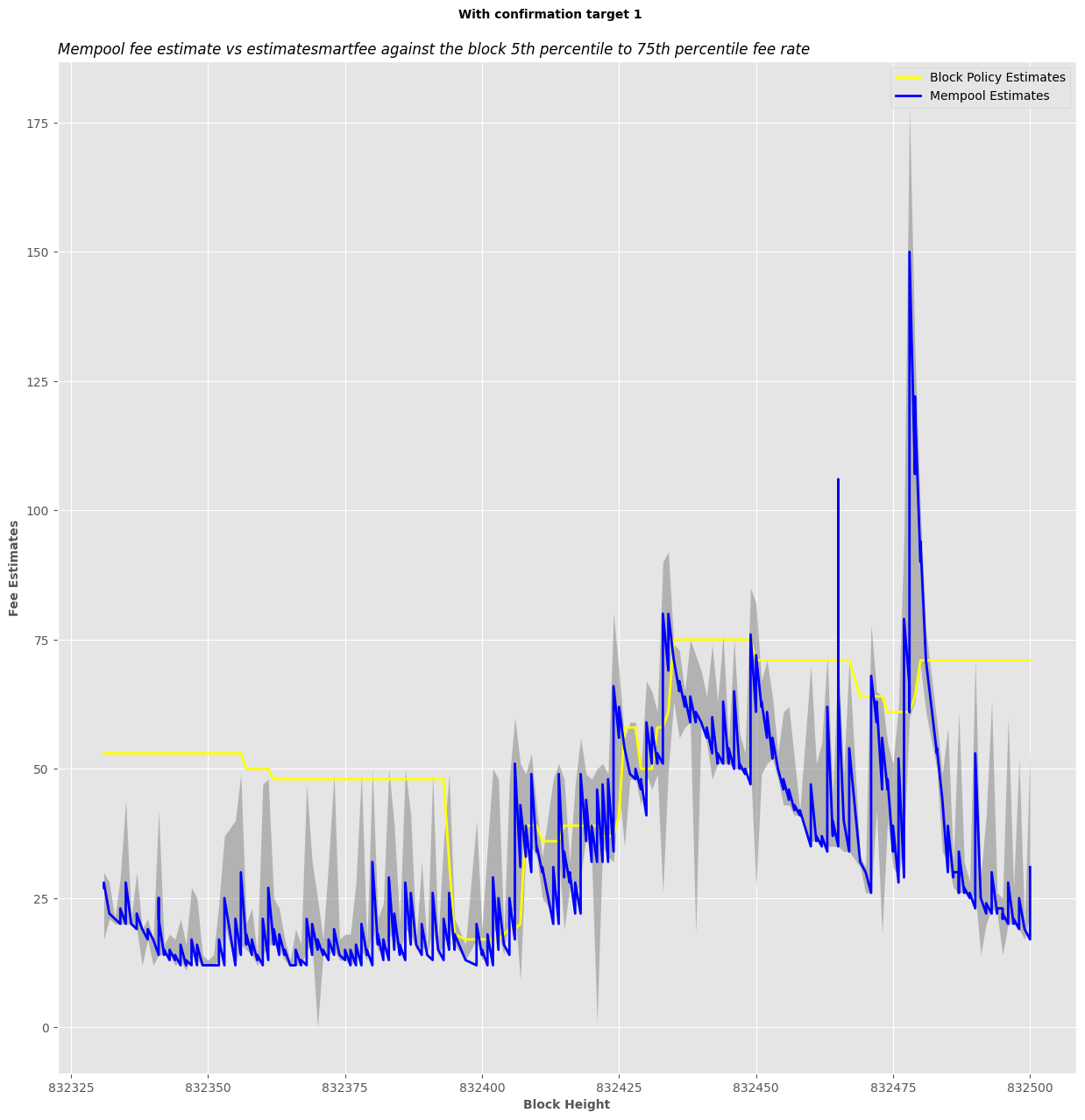
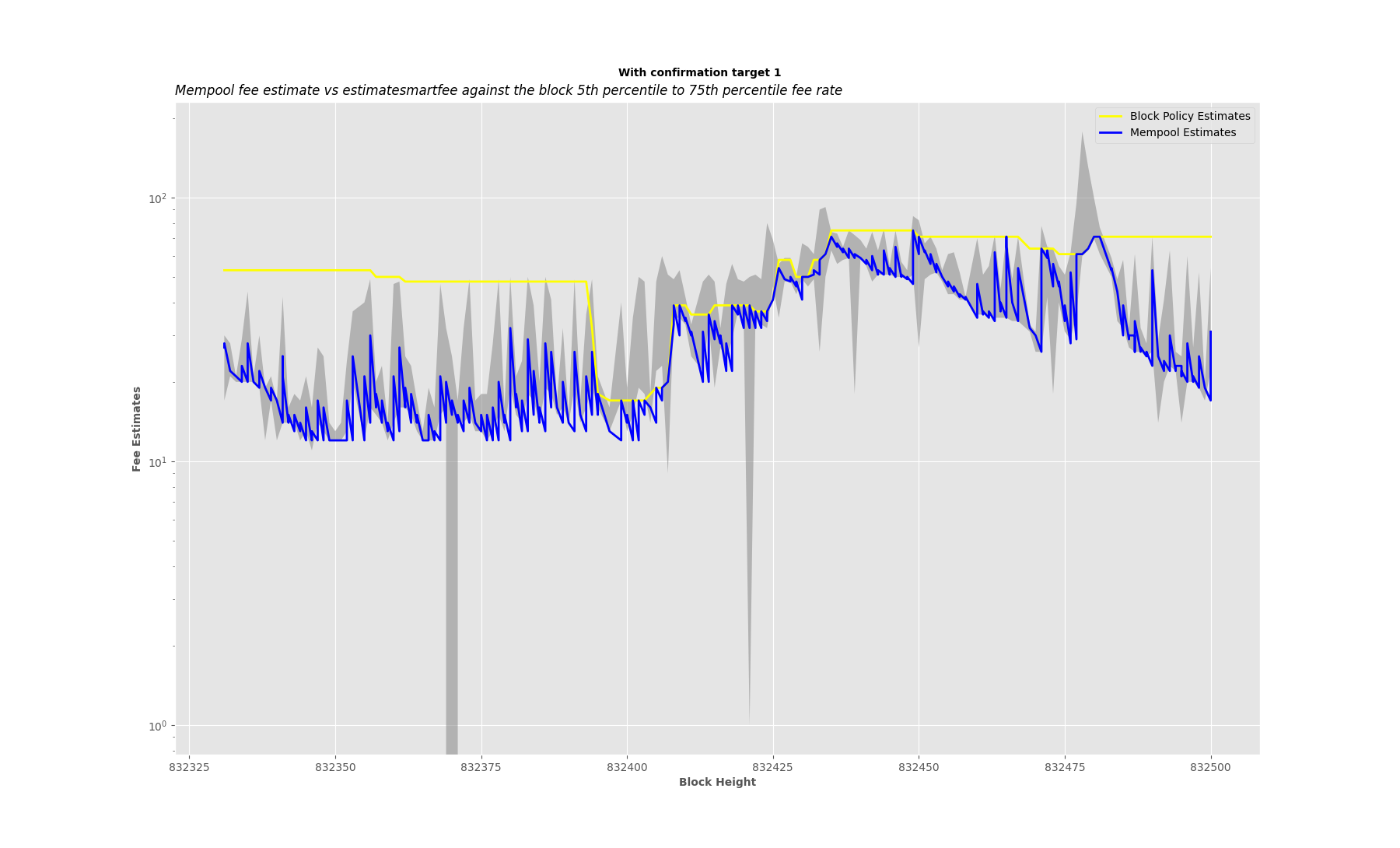
I’ve updated to a format that is more interesting to look at.
Thanks to additional data from @ClaraShk , I’ve filled between the 5th percentile fee rate to the 75th percentile fee rate.
Overall, based on my observations, using the threshold is not as much of an underestimation as I thought it would be. For most cases, estimates fall within the target block fee rate 5th percentile to 75th percentile range.
And I also calculated the summary of my observation:
Total of 19,154 estimates were made from 2024-02-28 01:57:56 to 2024-03-12 13:23:05 (Block 832330 to Block 834362)
CBlockPolicyEstimator::estimatesmartfee (economic mode) with confirmation target 1
5,643 estimates overpaid, accounting for 29.46% of the total estimates
2,114 estimates underpaid, accounting for 11.04% of the total estimates
11,397 estimates fall within the range, accounting for 59.50% of the total estimates
Mempool based estimate for next block (Without Threshold)
10 estimates overpaid, constituting 0.05% of the total estimates
3,637 estimates underpaid, constituting 18.99% of the total estimates
15,507 estimates fall within the range, constituting 80.96% of the total estimates
Mempool estimate for next block (With threshold of CBlockPolicyEstimator::estimatesmartfee (economic mode) confirmation target 1)
6 estimates overpaid, constituting 0.03% of the total estimates
5,070 estimates underpaid, constituting 26.47% of the total estimates
14,078 estimates fall within the range, constituting 73.50% of the total estimates
Using 5th percentile as the low end and 75th Percentile as the high end.
You can view it on Collab and edit the block ranges; it has a range threshold of 200 blocks:
This sounds like potential great savings for an active user that is willing to RBF should the initial estimate be short, but underestimating in over a quarter of the cases would sounds a bit painful for a user that wants to only submit an initial attempt.
Should probably be a log scale for the y-axis – you probably want to know when you’re paying twice as much as you should, rather than 25sats more. In particular an estimate of 150 sat/vb vs 75 sat/vb (the blue spike at the end) is probably about equally bad as a 50 sat/vb vs 25 sat/vb (the yellow overestimate for a while at the beginning).
but underestimating in over a quarter of the cases would sounds a bit painful for a user that wants to only submit an initial attempt.
The times when fee rate estimates did not make it are mostly when (the time of block discovery - the time of estimate) is > 10 minutes.
As I observed, the spikes are mostly due to congestion periods.
In most cases, when the blue estimates where overestimating, it’s within the block range. However, yes, paying a lower fee rate might get the transaction in, but with high likelihood of getting bumped out.
In particular an estimate of 150 sat/vb vs 75 sat/vb (the blue spike at the end) is probably about equally bad as a 50 sat/vb vs 25 sat/vb (the yellow overestimate for a while at the beginning).
The estimate of 150 sat/vB (50th Percentile fee rate of expected block) you indicated is for block 832478.
The block 832478 after its Confirmed has 50th Percentile fee rate of 150 sat/vB, which means this estimate was accurate.
The block’s high end used to plot the point in the graph is the 75th Percentile, which is 178 sat/vB.
The block’s low end (5th Percentile) is 60 sat/vB.
The block has average fee rate of ~170 sat/vB.
We could reduce the percentile we do estimate to maybe the 25th percentile, which is 130 sat/vB in this case, but there is a likelihood of getting bumped out if the time it takes the block to confirm after we make estimate is > 10 minutes, and the weight of transactions with a mining score > 130 sat/vB that entered the mempool after we made our estimate are also > 25th Percentile of 4,000,000.
The choice of the 50th percentile is to reduce the chances of getting bumped out.
In the case of the yellow overestimations at the beginning, it is unlike the blue once because what you are paying is beyond the block fee rate ranges. (i.e you will pay for the block space more that other people are paying)
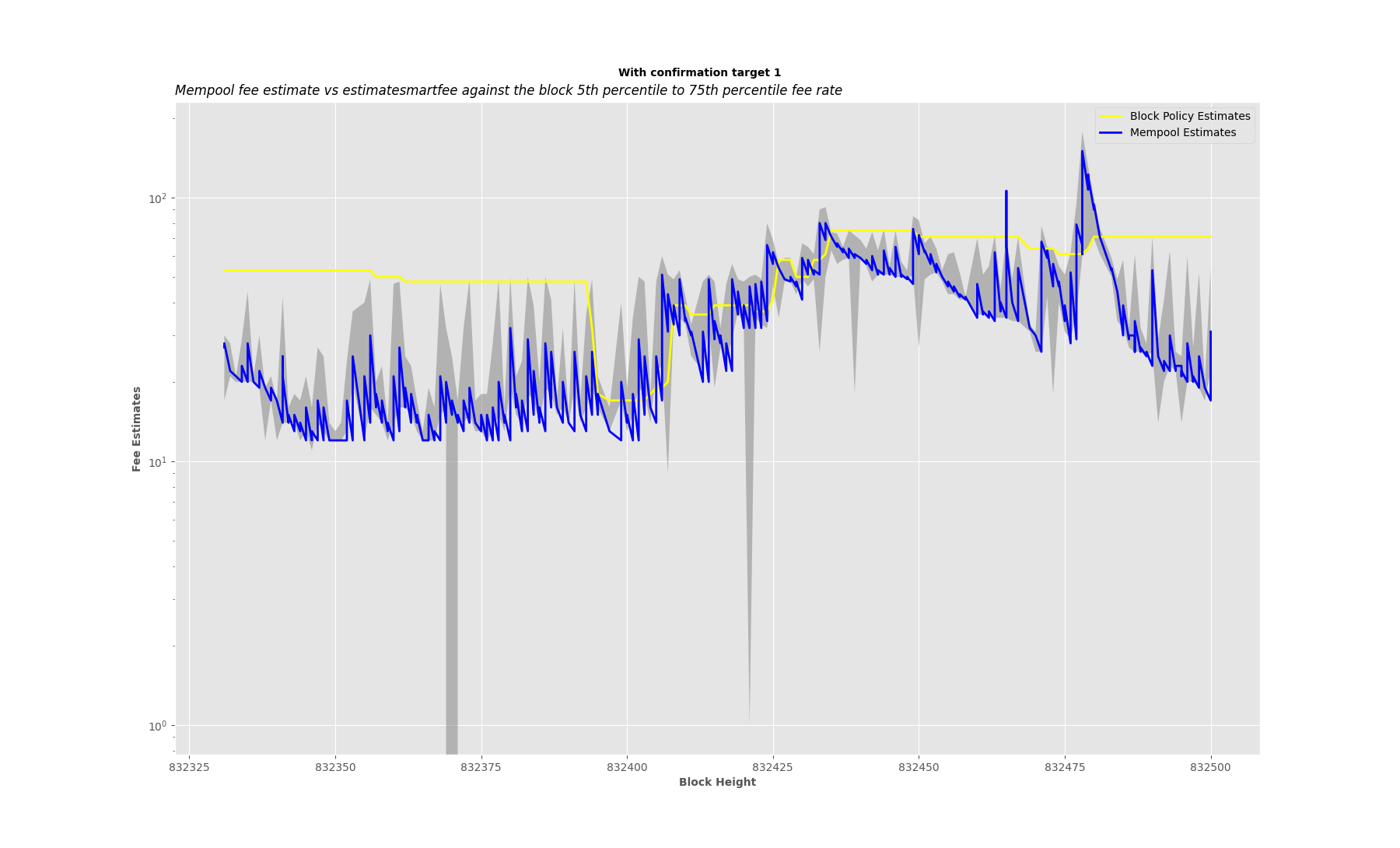
I have modified the plotting. It can now return both linear and log scales for the y-axis.
Here is how it looks now without the threshold:
plot_estimates(832331, 832500, data, logscale_yaxis=True)
Sorry for jumping in a bit late! Until February I have supervised and interacted quite a bit with a student to study fee estimation via mempool (unfortunately in German language). I wanted to open an issue on github with a summary of our findings but didn’t have the time. Yet I have the feeling this thread may be the right place to add a few thoughts. Apologies if this is not a 100% direct reply to the discussion. If too off-topic, I could move the post to a new thread.
Before I start I want to emphasize that I really like the direction of this work as I believed that using statistics on the mempool would be good. However the way I interpret Oscar’s results I tend to believe that the problem is much more complicated.
Bitcoin core tends to overestimate fees after spikes
First I wanted to share a diagram that show that bitcoin core’s fee estimater tends to overestimate fees for quite some time especially after a spike in fees occured:
With respect to @ismaelsadeeq choosing the median fee as a feature: We had been discussing this quite a bit. Initially we also thought that the median would be a great and obvious statistic to use. However as we have CPFP we could technically have more than 50% of tx and blockspace with really cheap transactions and one child paying for all of them. (Think of a Lightning Network node that force closes all its channels and the txs are bumped via anchors). At the same time miners tend to maximize the total fees in the block. Thus we came to the conclusion that against our own intuition the average fee per byte seems more indicative as a feature to use as it correlates with the total fees of the block.
Mempool resting times of tx before confirmation as a feature
We identified the distribution of mempool resting times of tx that made it to the current block an useful feature to predict weather we are in a rising or falling fee market. The philosophy is that transactions in the latest block that are longer in the mempool than the block time indicate that not much demand has been happening and older TX are being confirmed. Assuming no sudden demand change this means that the fees would be declining.
Best predictive feature not applicable
The best feature that we were able to extract on historic mempool data was the block time. This makes sense. If a block is found very quickly it is very likely that it includes a large amount of tx that have been resting in the Mempool longer than the blocktime which indicates that fees should decline. On the other hand if a block is not found quickly it is rather likely that users start to push fees up. Obviously we don’t know the next blocktime and cannot use that feature.
What about using option pricing via Black Scholes
Oscar’s work was handed in for a student competition. While the Jury acknowledged the technical depth and awarded a second price they had the criticism that the problem of fee estimation cannot and should not be studied without looking at the behavior of the other participants in the network.
Changing the fee estimator in bitcoin core might work well for a single node but if all nodes upgrade this may not be reasonable anymore. While we haven’t done so yet the Jury suggest to understand the problem of fee estimation as an option pricing model where one pays fees to have the option to be included in the next block. Consequently the suggested that we should have used Black-Scholes Equation to derive a price for such an option instead of just looking at statistics in the current mempool.
Could you share a few more details about the suggested fee estimation?
Is it the latest median \times 0.9 or 1.1, depending on whether the fees are expected to decrease or increase?
How often does it miss the next block or overpays?
The downside of both is that it might be too high of a goal, leading to overpaying. In an ideal world, you want to be the last transaction in the block.
Have you considered the average of the lower half, or something like that?
Were you able to quantify the decline/increase?
Black-Scholes is a very interesting idea, but doesn’t it need the stock to have a fixed expiration time? If we are willing to assume 10 minutes, we could also use it in a simpler model of time from the previous block.