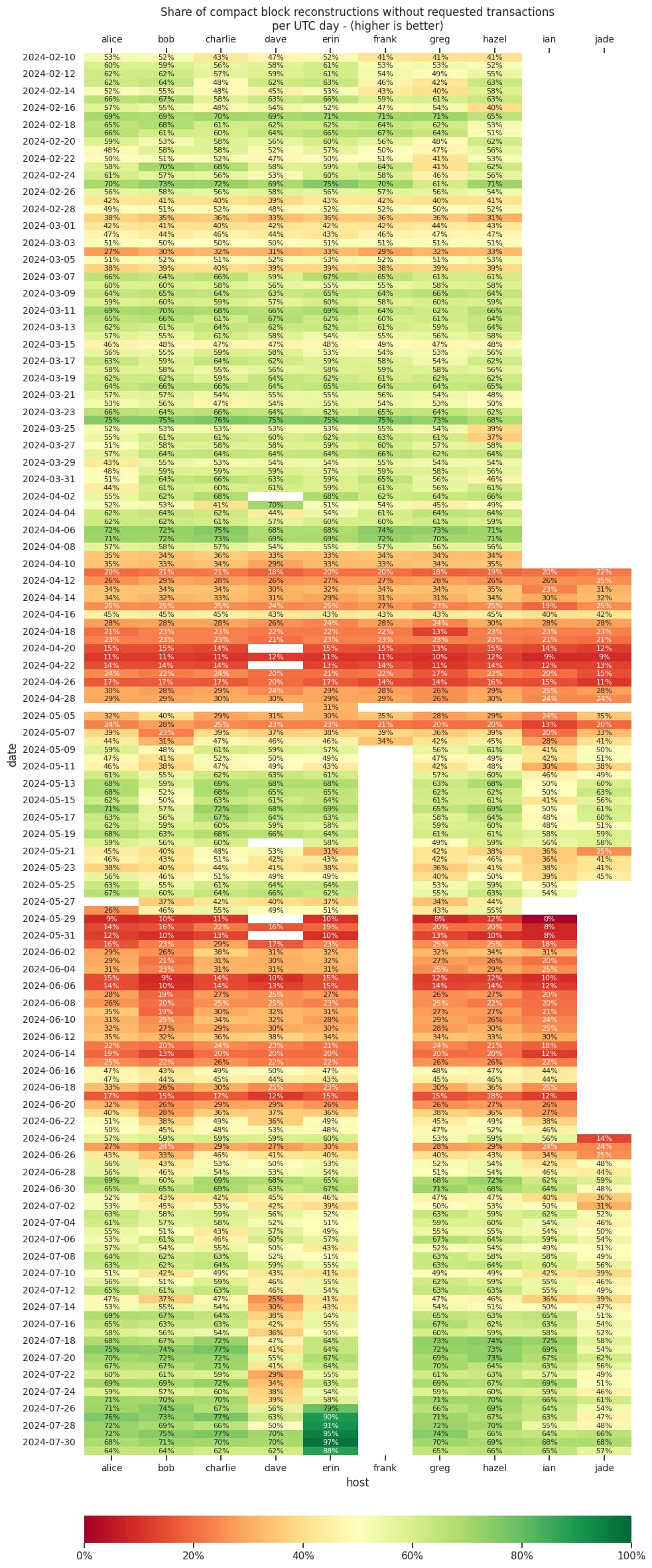
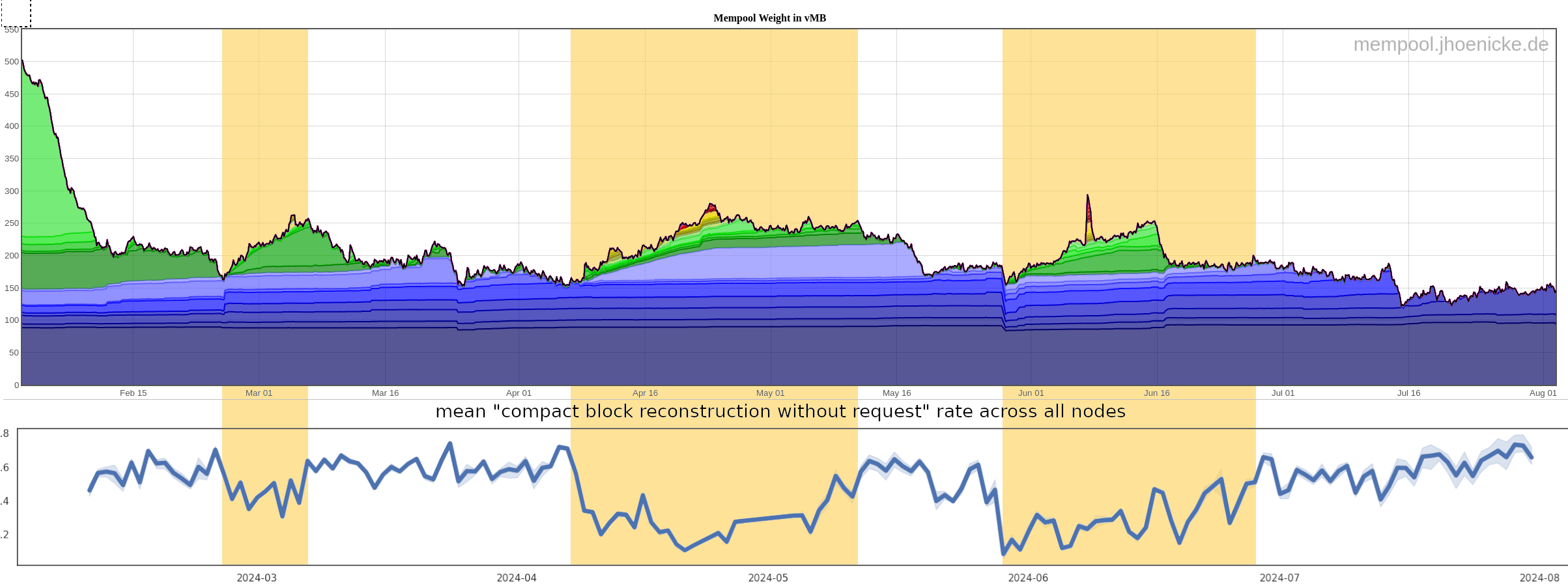
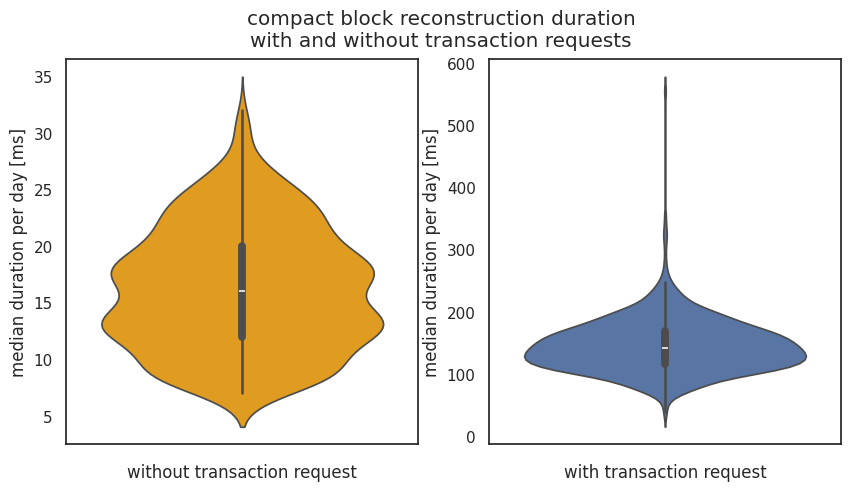
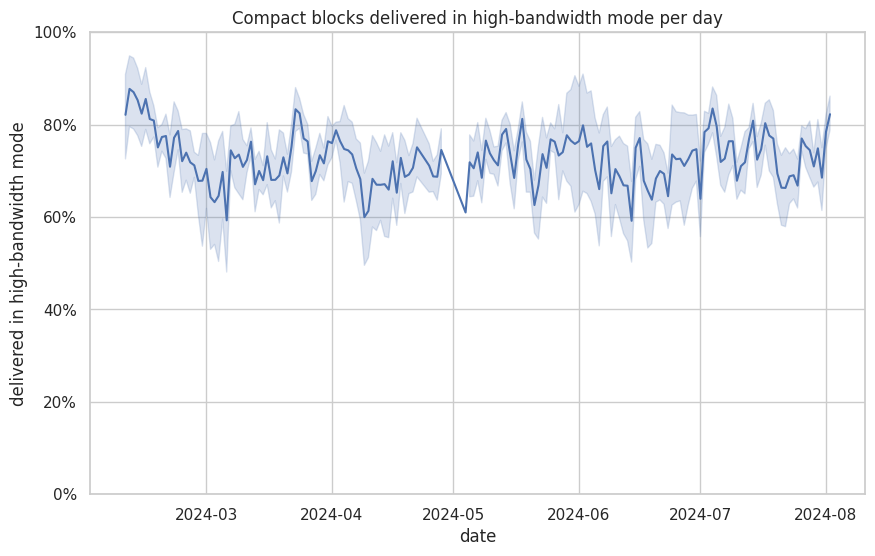
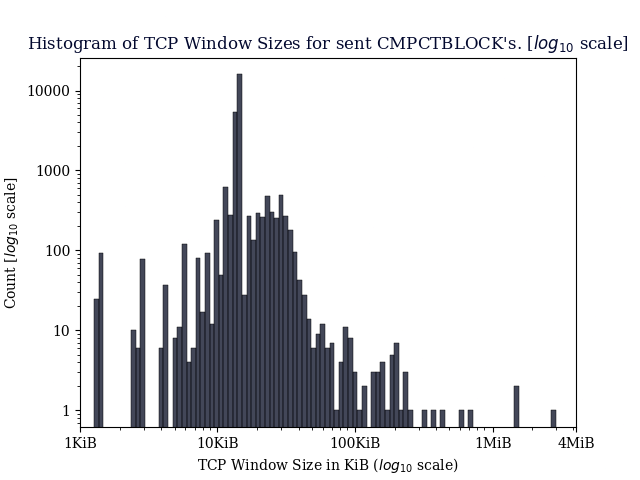
I’ve recently looked at compact block reconstruction statistics from the debug.log’s of my monitoring nodes. Particularly, at how many blocks require an extra getblocktxn → blocktxn round-trip as the node does not know about transactions during block reconstruction. I thought I’d share my data and a few observations here.
My nodes have debug=cmpctblock logging enabled. This allows me to grep for compact block reconstructions. The log output contains information on the number of transactions pre-filled in the compact block (here 1, the coinbase transaction), how many transactions the node could use from its mempool (3986), how many transactions were used from the extra pool (9) and how many were requested (6).
[cmpctblock] Successfully reconstructed block 000000000019d6689c085ae165831e934ff763ae46a2a6c172b3f1b60a8ce26f with 1 txn prefilled, 3986 txn from mempool (incl at least 9 from extra pool) and 6 txn requested
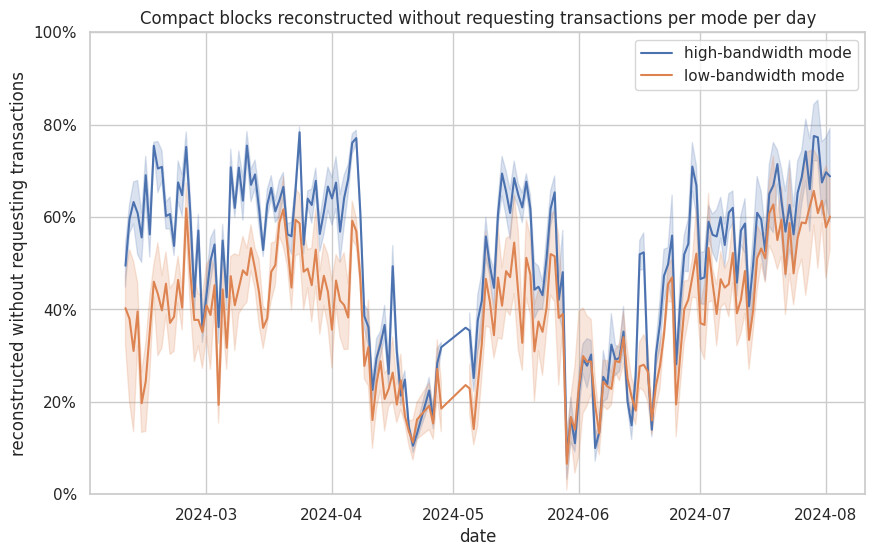
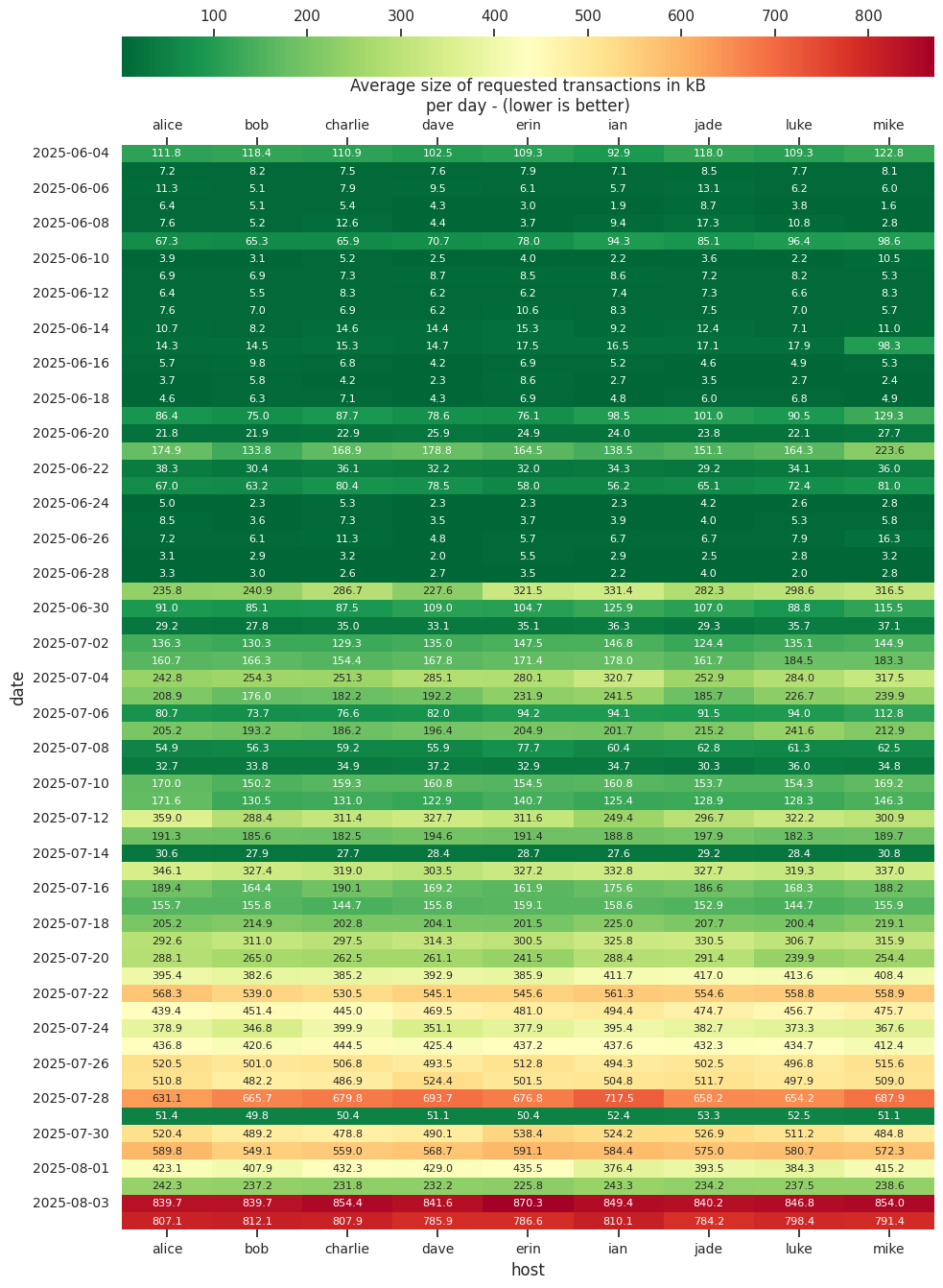
While the monitoring nodes have slight differences in their node configuration, they mostly use Bitcoin Core defaults. All monitoring nodes accept inbound connections and the default inbound slots are usually full. I set maxconnections=1000 on node dave - it usually has about 400+ inbound connections. On 2024-05-08, I switched node frank to blocksonly=1, which means it won’t do block reconstructions anymore. I switched erin to mempoolfullrbf=1 on 2024-07-26.
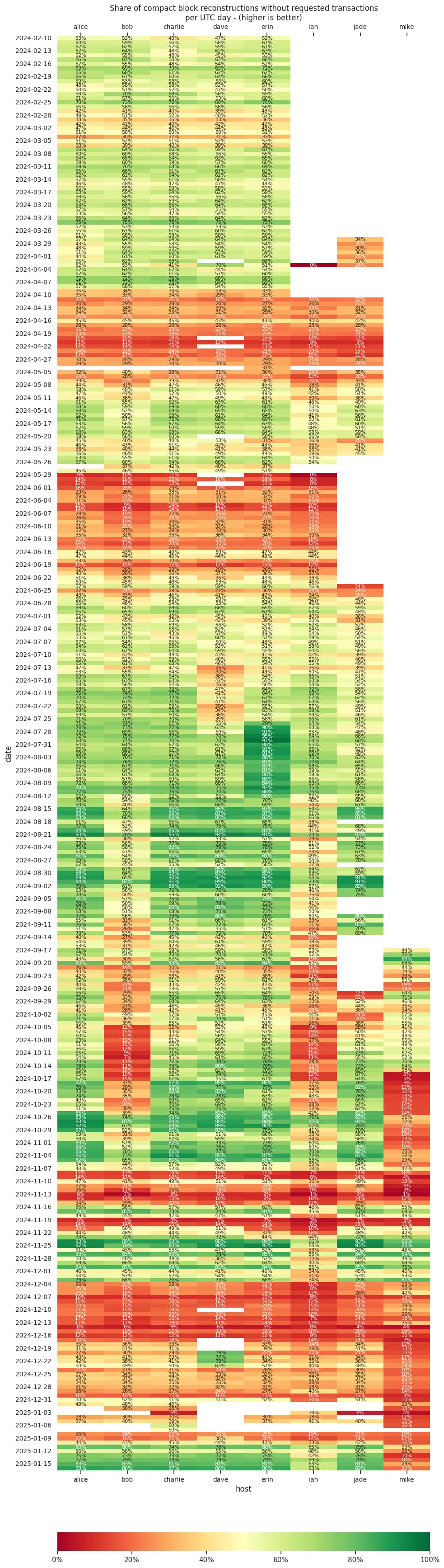
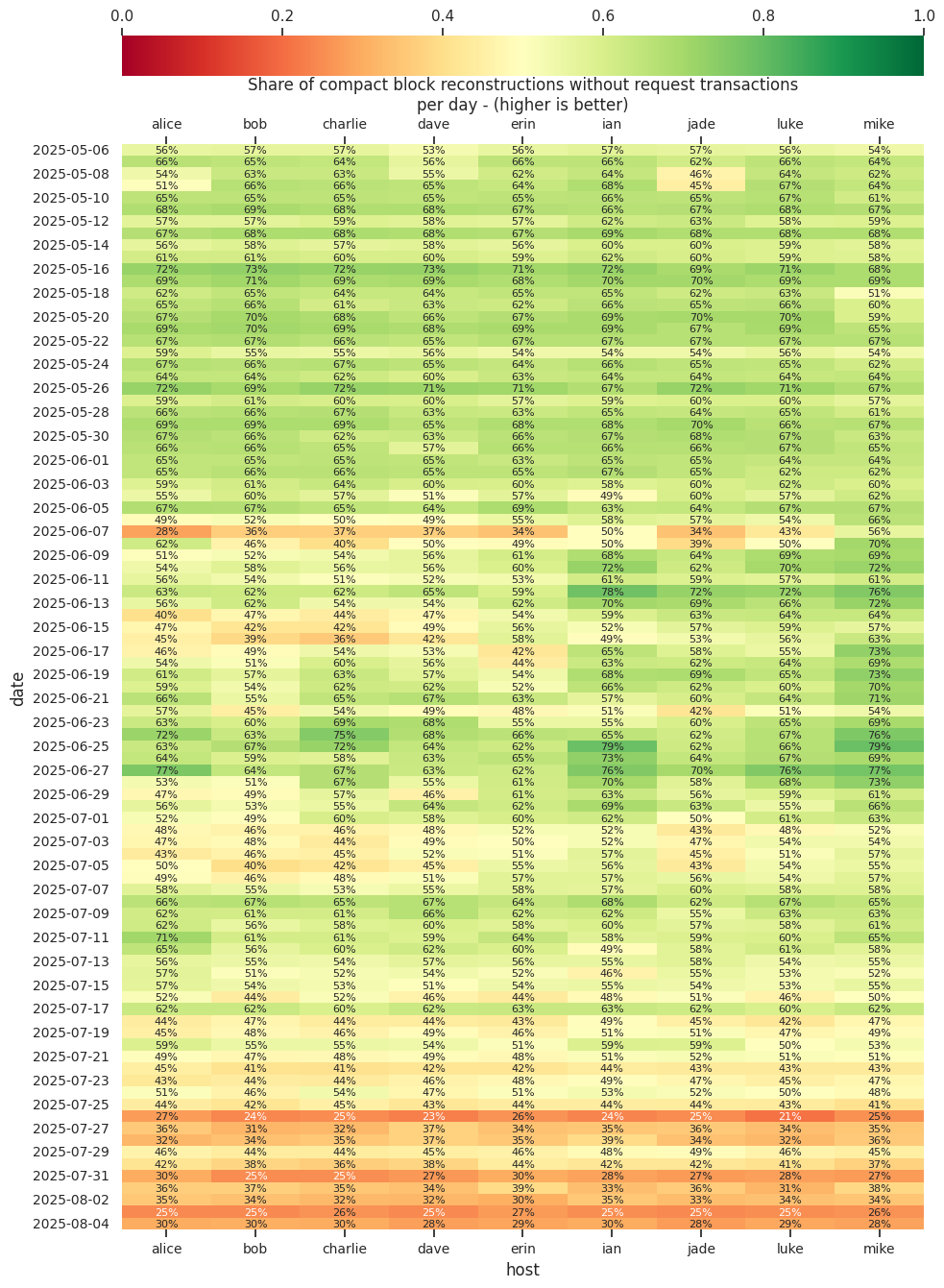
The following shows the share of block reconstructions that didn’t need to request transactions - higher is better.
Node dave under performing between 2024-07-10 and 2024-07-27 correlates with it rising from about 320 to nearly 500 inbound connections. It was restarted on 2024-07-27 and inbound connections were reset.
During other periods were dave had similar numbers of inbound connections, it didn’t seem to have had an impact on block reconstruction.
As noted in my review on policy: enable full-rbf by default, enabling mempoolfullrbf=1 on node erin significantly reduced the compact block reconstructions where the node had to request transactions. This seems to indicate that most pools now have policy different from the default Bitcoin Core policy. Turning on mempoolfullrbf by default could improve block reconstruction and thus reduce block propagation time across the network.
block reconstruction duration
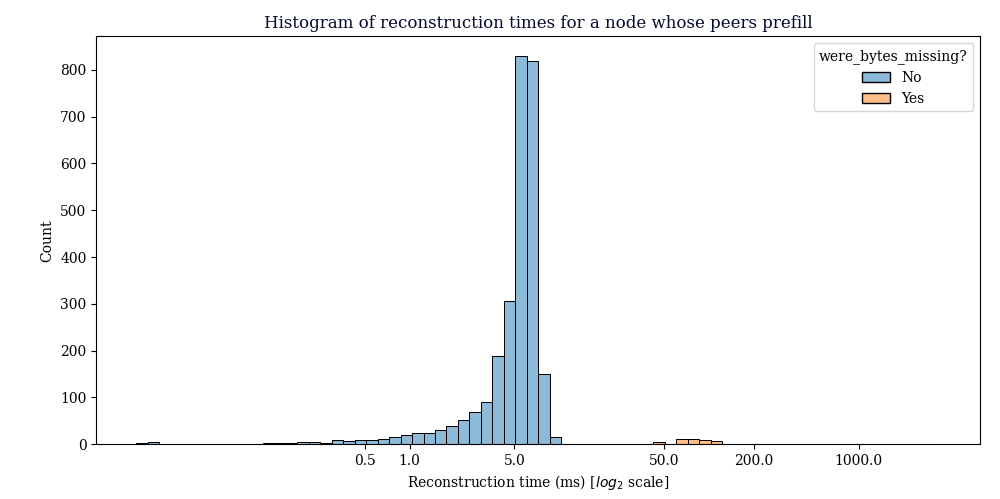
I was curious how long it takes to reconstruct a block when we have to request transactions and when we don’t have to. Note that these nodes are located in well connected data centers with reasonably good hardware, YMMV.
I looked at the timings of block reconstructions in high-bandwidth mode. In low-bandwidth mode, Bitcoin Core does not lognew cmpctblock header. I took the new cmpctblock header log timestamp (with logtimemicros=1) as start time and the Successfully reconstructed block timestamp as end time.
When no transactions need to be requested, median block reconstruction time on my hardware is usually around 15ms and about 130ms when transactions need to be requested.
I had the impression that low-bandwidth block reconstructions more often needed to request extra transactions compared to high-bandwidth reconstructions. I’m not sure if that would be expected. I think I have the data to look into it. Additionally, the share of low- vs high-bandwidth reconstructions over time would be interesting.
How do different extra pool sizes affect block reconstruction? How was the block reconstruction performance before miners started to enable full-rbf? Does anyone have historic debug=cmpctblock debug.logs for analysis? Also, all my (current) nodes have inbound connections. Looking at an outbound-only node in comparison could also be interesting.
About 75% of compact blocks are delivered in high-bandwidth mode (peer sends us a cmpctblock message before they have validated the block). The remaining ~25% are delivered in low-bandwidth mode (peer sends us a inv/headers and we request with a getdata(compactblock)).
Compact blocks received via high-bandwidth mode request transactions less often than (which is better) than compact blocks received in low-bandwidth mode.
I’ve noticed that nearly all compact blocks received have only a single transaction (the coinbase) pre-filled. As far as I understand, compact blocks delivered in low-bandwidth mode are fully validated before being announced (via inv/headers) and sender could pre-fill the transactions it didn’t know about itself. This might reduce the number of low-bandwidth compact blocks that require a transaction request. I’ve yet to check the Bitcoin Core implementation and see if there’s a reason why isn’t currently being done.
It might be good to recheck these numbers once Bitcoin Core v28.0 (with full-RBF by default, if merged) is being adopted by the network. If by then, the low-bandwidth mode still has similarly performance, it might make sense to spend some time on implementing this.
By this do you mean the extra transactions we keep around for compact block reconstruction or do you mean differing mempool sizes? If it’s the latter, it might be worth it to track your peers’ feefilter as that can give some indication of how large their pool size is. Note that it’s not precise because of the way the filter is calculated with a half-life, and because certain mempool maps might differ in memory usage. There is also some rounding in the result as well for privacy reasons.
I specifically mean the extra pool Bitcoin Core keeps for compact block reconstruction. Different node mempool sizes and different peer mempool sizes might have an effect too, but I feel this is better simulated with e.g. Warnet than measured on mainnet.
$ man bitcoind | grep blockreconstructionextratxn -A 2
-blockreconstructionextratxn=<n>
Extra transactions to keep in memory for compact block reconstructions (default: 100)
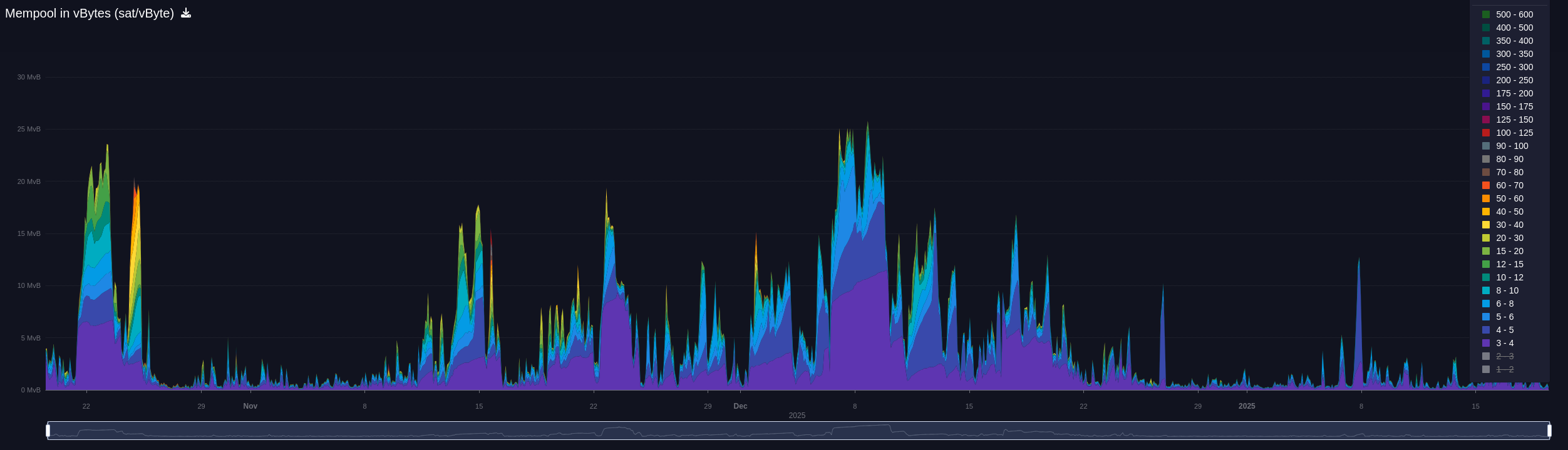
When the mempool grows (below shows everything above 3 sat/vByte), we usually need to request transactions for more block reconstructions. A few examples are:
One possible way to get this insight is to target blocks with low numbers to check how many of the requested transactions are non-standard. If they are much in all blocks with low numbers, it is most likely due to out-of-band prioritized transactions causing the issue; otherwise, it maybe inconsistent eviction.
Don’t really have an idea yet how to automatically determine why my node didn’t know about these transactions yet/anymore, but it probably makes sense to look at:
Doing a better job of requesting parents of orphan txs from other peers that offered us the orphan tx might help here too? See https://github.com/bitcoin/bitcoin/pull/31397 merged in master a couple of days ago.
I am curious if we considered not deleting transactions from the pool of received transactions? In other words, back the mempool with a db store.
As transactions get pushed out from the mempool by better fees transactions, we eject them from the mempool and store them to disk/db instead. Later we can fetch them from the db when required instead of reaching out to a peer.
This might also help with the problems that we are trying to solve using package relay of transactions. Not sure about this, but it could have an impact.
I think libbitcoin does not delete any received transactions, ever. Which avoids problems like trying to fetch them over the network if they are later required. There is no mempool there and instead the same transactions table holds all received transactions, spent or unspent. As long as they are unspent they can be used to construct next block.
In Core, the problem will be to delete txs from the mempool backup store when txs are spent. This will have a performance penalty. Maybe the libbitcoin solution of a single txs table is worth looking into again? One store, for all rcvd txs, spent or unspent and never delete them.
Regarding spam txs, we need the same defences we use against spam when protecting mempool.
This opens up some barn-door sized DoS vectors that graduate bandwidth waste to disk filling. If you’re ever out of step with miner’s policies, or someone partitions miner’s mempools with pins, you’ll fill your disk for free. And you’d still be taking round-trips for those blocks.
It also makes the amount of disk required per time period only bounded by gossip rate limiting.
Yes. The assumption in that decision is that disk is cheap. I suppose you can occasionally clean up older transactions in a manner similar to how we prune right now.
We can use a pruning policy that is similar policies for tx eviction from mempool, but much more forgiving as we have a much larger store available.
I was just curious if such a line of thinking has been debated before.
For the purposes of avoiding round trips on block relay, I think you could probably restrict that pretty easily – only keep txs that were in the mempool within the last 20 minutes, only keep the most recent 20MB of txs. If you also limited it to txs that were near the top of the mempool (either accurately via cluster mempool, or approximately by estimating a top of mempool feerate and comparing that to ancestor feerate and keeping their ancestors) I think that could work pretty okay, and probably just be done in memory, without being persisted to disk.
(Using vextra as short for vExtraTxnForCompact) It seems very reasonable for vextra to be larger, or for it to only contain non-orphan transactions, and then InitData can look through the orphanage as well (the orphans in vextra are kind of “free” memory-wise compared to the others).
In addition to running with a larger -blockreconstructionextratxn, I wonder if we can try to analyze how well we use vextra. Broadly we have (1) replaced transactions (2) orphans (3) transactions that fail validation, you could have a patch that turns the buffer into pairs of <CTransactionRef, OriginEnum>. I wonder if one or two of these types of vextra transactions is usually more useful than the others. (More granular, are there certain TxValidationResults that are particularly helpful/unhelpful? I think TX_CONSENSUS is skippable. I expect this is inconsequential though.)
If most of the reconstructions are orphans, then perhaps we should consider iterating through the whole orphanage in addition to the vextra buffer. fwiw I’m also currently working on a PR to that would make the number of transactions in orphanage potentially much larger, though (in the tens of thousands). So that might be a consideration if we’re thinking about doing this.
Didn’t immediately realize why we need to iterate through whole thing so saying it out loud in case others weren’t aware: it’s because the short IDs aren’t known until one gets the compact block itself, so it cannot be precomputed.
I’m not sure if adding orphans would do much to help avoid round trips – you’re missing the parent and the parent will need to be in the block, after all.
One thing that could be worth looking into is doing a better job of populating prefilledtxns – ie, “I’m pretty sure my peers don’t know about these txs in the block, so I’ll send them straight away”. Though maybe it would be more useful to just spend that time on bringing the FIBRE patch set up to date, and having some public servers running again.
This was the end conclusion of my offline discussion with a few folks back when I was thinking harder about this. I just saw so many different reasons for misses that I felt anything that isn’t a relatively simple improvement wouldn’t be worth the lift. Second look at a p2p version of FIBRE?
The FIBRE code is AGPL licensed so would presumably need a rewrite/relicense to be included in bitcoin p2p.
Not sure what it would look like in a decentralised model; maybe just the ability to select some peer(s) as ultra-high-bandwidth compact block relay, and have them stream an FEC-encoded version of the block contents at you immediately after the compact block announcement? Not sure if it would make sense to have that open to random peers, or just restricted to whitelisted peers.
I’ve started recording the contents of inbound and outbound getblocktxn messages a week ago. This should allow for some insights into “are peers often missing the same transactions?” and “can we pre-fill the transactions we had to request our self?”. I haven’t taken a closer look at the data yet.
Also, I’ve changed one of my nodes to run with blockreconstructionextratxn=10000 and updated two nodes to a master that includes p2p: track and use all potential peers for orphan resolution #31397. Probably need to wait until the mempool fills up again to see the effects of this.
One other thing is that FIBRE is designed for UDP transmission to avoid delays due to retransmits; so redoing it over TCP via the existing p2p network would be a pretty big loss…
⚠ post #23 missing (not fetched, or removed/moderated on the source site)
I’ve changed node alice to run with blockreconstructionextratxn=10000 early February. This had a noticeable effect the following days with slightly higher scores starting 2025-02-06. During the increased mempool activity between 2025-02-21 and 2025-03-06 it performed significantly better than my other nodes.
Node ian was running Bitcoin Core v26.1 until I switched all nodes to run v29.0rc1 release candidate. ian clearly performed worse than the other nodes before the update, which is expected as e.g. mempoolfullrbf wasn’t default in v26.1.
Node mike doesn’t allow inbound connections (while the other nodes do and usually have full inbound slots). This is noticeable in the reconstruction performance. Only having eight peers that inform mike about transactions is probably likely worse than having close to 100 peers that inform you about new transactions.
The stats from alice, charlie, and erin could indicate that orphans aren’t the problem, but conflicts, replacements, and policy invalid transactions (i.e. extra pool txns) cause low performance during high mempool activity. Although, I’m not sure if these three moths of data are enough to be certain yet.
I’ve started to look at the data I’ve been recording. It seems that many of my peers I announced a compact block to end up requesting very different sets of transactions (and usually larger sets) than I request from my peers. I assume many of them might be non-listening nodes like mike or run with a non-default configuration. This needs more work, but I hope to post more stats on requested transactions here at some point.
I’ve also noticed that my listening nodes running with the default configuration often independently request similar sets of transactions. This seems promising in regards to predictably prefilling transactions in our compact block announcements. My assumption would be that if we prefill:
transactions we had to request
transactions we took from our extra pool
and prefilled transactions we didn’t have in our mempool (i.e. prefilled txns that were announced to use and ended up being useful)
we can improve the propagation time among nodes that accept inbound connections and use a “Bitcoin Core” default policy. This in turn should improve block propagation time of the complete network as now more nodes know about the block earlier. Additionally, useful prefilled transactions don’t end up wasting bandwidth, only transactions that a peer already knew about would waste bandwidth. These improvements would probably be most noticeable during high mempool activity: the (main) goal wouldn’t be to bring the days with 93% (of reconstructions not needing to request a transaction) to 98% but rather the days with 45% to something like 90% for well-connected nodes.
Since Bitcoin Core only high-bandwidth/fast announces compact blocks to peers that specifically requested it from us (because we quickly gave them new blocks in the past), non-listening nodes that are badly connected won’t start sending wasteful announcements with many prefilled, well-known transactions to their peers.
limit the prefill amount to something like 10kB worth of transactions as per BIP152 implementation note #5. I think this is useful to avoid wasting too much bandwidth if a node does a high-bandwidth announcement but, for some reason, prefills a lot of well-known transactions in the announcement
cmpctblock debug logging on wasted bandwidth: log the number of bytes of transactions we already knew about when receiving a prefilled compact block. This can be tracked/monitored to determine if were wasting too much bandwidth by prefilling
since the positive effect on the network is only measurable with a wide(r) deployment of the prefilling patch, it’s probably worthwhile to do some Warnet simulations on this and test the improvement under different scenarios.
I’m not sure I understand why we would want to also prefill txs from our extra pool. The logic for extra pool inclusion would be the same for all nodes. So if we consider that our peers would have the same txs in their mempool then logically we would consider that our peers would have the same txs in their extra pool, no?
Yeah, good question. I don’t have data on this yet, but I think it makes sense to look at the extra_pools of nodes and see if they are similar or different. My assumption is that they aren’t too similar.
So if we consider that our peers would have the same txs in their mempool then logically we would consider that our peers would have the same txs in their extra pool, no?
A few arguments against extra pool similarity are:
the extra pool is quite small with only 100 transactions in it by default
mempool transactions are relayed with the hope that mempools converge, extra pool transactions are stopped at their first hop and aren’t relayed
you might have peer that is sending a lot of transactions you’ll reject and put into your extra pool, but I might not have a connection to this peer - our extra pools will be quite different
RBF replaced txs are put into the extra pool, and the replacing tx is still relayed. So they should converge. If we are going to search the orphanage anyways, we can stop putting orphans into the extra pool.
Would it be likely a miner will mine these rejected txs though? Not sure.
One point brought up by sipa here in a semi-related thread ([WIP] p2p: Add random txn's from mempool to GETBLOCKTXN by davidgumberg · Pull Request #27086 · bitcoin/bitcoin · GitHub) is that the number of TCP packets sent over could increase if we’re making the CMPCTBLOCK message larger with prefilledtxns. I think that is maybe one downside to prefilling transactions. Perhaps it’s possible to prefill transactions up to a certain total message size limit specifically for compact blocks?
EDIT: His point was actually about the GETBLOCKTXN causing more round trips, but the same thing applies.
since the positive effect on the network is only measurable with a wide(r) deployment of the prefilling patch, it’s probably worthwhile to do some Warnet simulations on this and test the improvement under different scenarios.
I think one low effort way to perform a limited test of this patch on mainnet is to run a second node which only listens to CMPCTBLOCK announcements from manually-connected peers, and is manually connected to a 0xB10C/2025-03-prefill-compactblocks node. I’ve created a branch to try this: davidgumberg/5-20-25-cmpct-manual-only, I’ll try to run an experiment soon with two nodes.
My assumption would be that if we prefill:
transactions we had to request
transactions we took from our extra pool
prefilled transactions we didn’t have in our mempool (i.e. prefilled txns that were announced to use and ended up being useful)
I think the privacy concerns raised in bitcoin/bitcoin#27086, are relevant here, how can a node avoid:
Providing a unique fingerprint by revealing its exact mempool policy in CMPCTBLOCK announcements.
Revealing all of the non-standard transactions that belong to it by failing to include them in it’s prefill.
2. is more severe, and may be part of a class of problems (mempool’s special treatment of it’s own transactions) that is susceptible to a general fix outside of the scope of compact block prefill. Even if it’s impossible or infeasible to close all leaks of what’s in your mempool, it would be good to solve this.
One way of fixing this might be to add another instantation of the mempool data structure (CTxMempool), maybe called m_user_pool. Most of the code could go unchanged except for where it is desirable to give special treatment to user transactions, and these cases could be handled explicitly.
To solve 1., I wonder if there is a reasonably performant way to shift the prefills in the direction of prefilled transactions the node wouldn’t have included according to default mempool policy. This is not just for privacy, as I imagine this is the ideal set of transactions to include, strict mempools prefilling too much, and loose mempools prefilling too little.[1] If this would be too expensive to compute on CMPCTBLOCK receipt, maybe a variation of m_user_pool is possible, where a node maintains another CTxMempool instance for all the transactions which default mempool policy would have excluded, but user supplied arguments have permitted. Or maybe the extra state is too expensive/complicated, and instead just performing an extra standardness check with the default policy on tx receipt and setting a flag on the tx (or keeping a map of flagged tx’es) is enough.
Maybe all of this is too complicated to implement proportional to its value here, but these could also be steps toward solving mempool fingerprinting more generally.[2]
the number of TCP packets sent over could increase if we’re making the CMPCTBLOCK message larger with prefilledtxns.
I am not very knowledgeable about TCP, but as I understand RFC 5681, the issue is not a message growing to a size where it has to be split across multiple packets/segments, but a message that grows too big to fit in the receiver-advertised message window (rwnd) and the RFC 5681 (or other congestion control algorithm) specified congestion window. (cwnd). The smallest of these two (cwnd and rwnd) is the largest amount of data that can be transmitted in a single TCP round trip, it should be possible to get the relevant metrics for this from the tcp_info structure on *nix systems[3] doing something like:
And the announcer could pack the prefill until it hits this limit. I am not sure how likely it is that that constraining messages to this size would deter a second round trip from taking place, but it seems like a reasonable starting point.
For better or for worse, such an approach would disadvantage nodes with stricter-than-default mempools in compact block reconstruction. ↩︎
But maybe no general solution to mempool fingerprinting is possible, and nodes with non-default mempools shouldn’t have any expectation that they can’t be fingerprinted. ↩︎
Prefilling is just a flawed part of the design, it was kinda tossed in because it was very easy to add and harmless if not used. After compact blocks were deployed I did a bunch of testing and was unable to make it do anything but harm.
The issues it has are several fold: it’s part of the compact block message so it blocks reception of the compact block in cases where it wasn’t needed. Peers also get compact blocks from multiple sources and so if they all use prefill then you waste N fold the bandwidth (or N-1 if one was indeed helpful). And then of course the extra data stuffs you further back into needing RTTs, thanks to window issues.
Then of course you have the issue that many missed transactions are missed because they were too large, which makes all the above issues much worse.
Fiber being AGPL is a non-issue, parts could be re-licensed if needed. It has in it solutions to every one of the issues raised above-- including the ability for extra data to be sent that helps even if the prediction of what was missed wasn’t accurate, allowing data from multiple peers to all contribute, and so on.
The use of UDP however, needed get around the TCP window issues, would probably be challenging for widespread deployment due to the need for hole punching.
A lot of thing have happened since then, core has minisketch merged (though unused), and using that kind of tool I was able to get blocks in consistently 800-ish bytes before. A big reduction in compact block size would leave a lot of room for data to fill in missing transactions.
But if miners are regularly including hundreds of kilobytes that were never relayed I’m a bit dubious that any scheme is going to result in particularly good performance except between peers with extremely high dedicated bandwidth that can do manual congestion management (e.g. a fiber like deployment of geographically dispersed data center nodes). Though the fact that it can help even if just some nodes run something faster is helpful-- it makes development of stuff more interesting even if there isn’t a serious deployment story.
The issues it has are several fold: it’s part of the compact block message so it blocks reception of the compact block in cases where it wasn’t needed. Peers also get compact blocks from multiple sources and so if they all use prefill then you waste N fold the bandwidth (or N-1 if one was indeed helpful). And then of course the extra data stuffs you further back into needing RTTs, thanks to window issues.
Then of course you have the issue that many missed transactions are missed because they were too large, which makes all the above issues much worse.
I agree that in the extreme case, prefilling will not be helpful. But I’m optimistic that prefilling up to the TCP congestion window (no extra RTT) is not harmful. It seems reasonable to presume that, in general, a node’s operating system’s congestion control algorithm will reliably predict the maximum message that can be sent to a peer without incurring an extra round trip, and nodes with slow connections will tend to also have small windows, mitigating the redundant prefill cost. If it works as I understand, it seems like using the cwnd will scale nicely up and down with connection speeds, and offloads the engineering burden of this problem to kernel developers and the IETF.
It seems worth measuring what the typical sizes of compact block BLOCKTXN fulfillments are. I’ve made a branch that might help with this: (log: Additional compact block logging by davidgumberg · Pull Request #32582 · bitcoin/bitcoin · GitHub). It would also be useful to have some data on bitcoin node congestion windows sizes, and if these are close to each other in size, compact block reconstruction failures don’t go away, but conservatively prefilling might make them less frequent while incurring little additional cost.
A lot of thing have happened since then, core has minisketch merged (though unused), and using that kind of tool I was able to get blocks in consistently 800-ish bytes before. A big reduction in compact block size would leave a lot of room for data to fill in missing transactions.
Great idea, I see that on my node compact block messages hover around ~20kB, 800 bytes would leave a lot more overhead for prefills!
I am not sure whether the comment in PR 27086 I linked is referring to congestion issues or IPv4 fragmentation issues. I don’t have hard data, but I believe both contribute to latency issues here and sending data >> MTU (~1500 bytes) is going to lead to lots of fragmentation. Two links if you have the time:
There is no IP fragmentation involved in TCP transmissions (well, assuming PMTUD did its thing)… indeed, you’re conflating IP reassembly with TCP reassembly.
I connected two Bitcoin Core nodes running on mainnet, one prefilling transactions to a node that only received CMPCTBLOCK announcements from its prefilling peer. Even though the intended effects of prefilling transactions are network-wide, and it would be nice to have some more complicated topologies and scenarios tested in e.g. Warnet, this basic setup can be used to validate some of the basic assumptions of the effects of prefilling:
Does prefilling work to prevent failed block reconstructions that otherwise require GETBLOCKTXN->BLOCKTXN roundtrips, irrespective of the cost of prefilling?
Does prefilling result in a net reduction on block propagation times?
The results indicate that the answer to 1. is definitively yes. The metric used by 0xB10C/2025-03-prefill-compactblocks of prefilling the transactions we were missing from our mempool when performing block reconstruction resulted in an observed reconstruction rate of 98.25% for a node receiving prefilled CMPCTBLOCK announcements when both the prefilling node and the prefill-receiving node are running similar builds of Bitcoin Core, compared to the observed reconstruction rate on a node not receiving prefilled blocks of of 61.81%. Some of those prefills, as pointed out by @Crypt-iQ and @gmaxwell above, exceeded the TCP window, and likely resulted in an additional round-trip, negating the benefit of prefilling. But, in my measurements, 85.78% of the prefills would have fit in the partially occupied TCP window a prefilling node sent the CMPCTBLOCK’s in. Projecting out, these measurements indicate that if all Bitcoin Core nodes had been prefilling during the period which I measured data, the reconstruction rate would have been 93.07% and we can likely do better taking advantage of the fact, pointed out by @andrewtothabove that similar peers will likely have similar vExtraTxn.
Within DoS limits (maybe a limit of 4 MiB per valid header), temporarily store a per-block cache of prefilled transactions you hear about, increasing the chances that you successfully reconstruct without having to wait for an RTT.
If the send window can’t fit all of the prefill candidates, prefill a random selection of candidates, always prefilling transactions not in vExtraTxn first.
Future investigations should:
Use prefill-receiving nodes to measure the amount of duplicate / redundant data in the prefill.
Use two peers with stable and high (maybe artificial?) latencies to easily estimate the number of round-trips that messages take to pass between them, there is also probably external tooling that can measure this.
Measure / reason about effects of prefilling at a distance of more than one hop.
Measure data about the GETBLOCKTXN messages that a prefilling node receives from random peers.
Latency and Bandwidth
Feel free to skip the math in this section or to skip reading this section entirely.
Taking a simplified view, the latency for a receiver to hear an unsolicited message (the scenario we care about in block relay) consists of
transmission delay plus propagation delay:
Any time compact block reconstruction fails because the receiver was missing transactions, an additional round-trip-time (RTT) of requesting missing transactions and receiving them (GETBLOCKTXN->BLOCKTXN) must be paid in order to complete reconstruction, but at this point the amount of data that needs to be transmitted for reconstruction to succeed does not change. Where f is the probability for a block to fail reconstruction:
\text{Latency} \approx \frac{\text{Data}}{\text{Bandwidth}} + \sim{\frac{1}{2}}\text{RTT} + f * \text{RTT}
If we had perfect information about the transactions our peer will be missing, we should always send these along with the block announcements since we will pay basically the same transmission delay, minus the unnecessary round-trip. If we don’t have perfect information, then the worst we can do is send transactions which our peer already knew about, while not sending them transactions they didn’t know about, incurring the RTT anyways, plus the transmission time of the redundant data. Let’s say we send p extra prefill bytes, with each byte having a probability n of being redundant and prefilling p bytes gets us a reconstruction failure probability of f_{p}, then:
If latency while prefilling is less than or equal to latency without prefilling, where b is bandwidth, r is the RTT, d is the size of the CMPCTBLOCK without prefill, p is the size of the prefill, and f_p is the reconstruction failure rate at a given prefill size p:
But, the use of TCP in the Bitcoin P2P protocol complicates this, because a sender will not send data exceeding the TCP window size in a single round-trip. Instead, they will send up to the window size in data, wait for an ACK from the receiver, and then send up to window bytes after the data which was ACKed. That means that if we exceed a single TCP window, we will have to pay an additional RTT in propagation latency (and a little bit of transmission latency for the overhead). And for each additional window we overflow, we will pay another RTT:
Doing a similar dance as above, where p is the prefill size and f_p is the probability of reconstruction failure at prefill size p, and n is the probability of a prefill byte being redundant:
The “TCP window” is the smaller of two values: the receiver advertised window (rwnd) and the sender-calculated congestion window (cwnd).
Overflowing current TCP window is always worse than doing nothing
The above formula establishes as a rule something which might have been intuited, that if the prefill causes us to exceed the current TCP window, then we will always do worse than if we hadn’t prefilled, since:
f_0 - f_p \leq 1 since the smallest number f_0 can be is 0, and the largest number f_p can be is 1.
\lfloor{\frac{\text{Data}}{\text{Window Size}}}\rfloor - \lfloor{\frac{\text{Data}+p}{\text{Window Size}}}\rfloor \leq -1 if the prefill overflows the current partially filled TCP window.
If a \leq 1 and b \leq -1, then a + b \leq 0, so the right hand side of the formula is \leq 0.
The left hand side of the equation will always be \geq 0, since none of the variables on the left side can ever be negative.
If lhs \geq 0 and 0 \geq rhs, then lhs \geq rhs, so the left hand side will never be less than the right hand side, therefore prefilling will never be beneficial.
But, if we bound our prefill p so that we never increase the number of TCP windows used, i.e.: \lfloor{\frac{\text{Data}}{\text{Window Size}}}\rfloor - \lfloor{\frac{\text{Data}+p}{\text{Window Size}}}\rfloor = 0 which, I believe is easy to do, we can use the exact same formula as above to decide whether or not prefilling is effective:
So far, I have assumed perfectly reliable networks and this isn’t always the case, packets get lost, and in TCP that means waiting for a timeout, and then retransmitting. But, I believe the problem above I’ve described in relation to prefilling is very similar to the problem that the designers of TCP had in selecting a static window size, and later, dynamic window sizes through congestion control algorithms like those described in RFC 5681 and RFC 9438. Instead of the probability that a block reconstruction will fail, they deal with the probability that a packet will not arrive, in both cases, the consequence is an additional round-trip, and a core question is whether the marginal value of potentially saving a round-trip by packing in more data is worth the risk that retransmission will be necessary anyways. The analogy is imperfect, as there are many more concerns that TCP congestion control algorithms deal with, but I argue that the node can outsource the question: “How large of a message can we send and reasonably expect everything to arrive?” to its operating system’s congestion control implementation.
Complication: Cost of Bandwidth
In all of the above, I have assumed the cost of using bandwidth is 0 outside of the latency cost. I’ve done this because I believe the cost of the redundant transactions sent in compact block prefills is negligible, the data I measured below suggests that prefills will be on the order of ~20KiB, so worst case monthly bandwidth usage of prefilling, assuming every byte is redundant and did not need to be sent, and that you always receive a prefilled CMPCTBLOCK from three HB peers, is ~300 MiB. (3 HB Peers * 20 KiB * 6 * 24 * 31)
Takeaways
I don’t think proving that the above inequality being satisfied is necessary for a prefilling solution, what I think it’s useful for is building an intuition of the problem, and setting theoretical boundaries on how effective prefilling needs to be to be worth it.
Nodes are likelier to suffer rather than benefit from prefilling that have smaller Bandwidth * RTT (See Bandwidth-delay product (BDP)) connections: e.g. nodes with low bandwidth and low ping. And nodes that have connections with large BDP’s are likelier to benefit, e.g. high-bandwidth, high-latency connections(“Long Fat Networks” as described in RFC 7323)
If the redundant broadcast probability n is zero, prefilling is always worth it.
The node receiving not prefilled blocks had a reconstruction rate of 61.81%, the node receiving prefilled blocks had a reconstruction rate of 98.25%, but only 85.78% of those would have fit in the current TCP window of the CMPCTBLOCK being announced, so projecting from those two figures, 93.07% of blocks could have been reconstructed without an additional TCP round trip. The vast majority of TCP windows observed were around ~15KiB. For a lot of the data around prefills, the averages are massive because of a few extreme outliers, but the vast majority of the time, a very small amount of prefill data is needed to prevent a GETBLOCKTXN->BLOCKTXN round trip, 65% of blocks observed needed 1KiB or less of prefill.
Prefill-Receiving Node: stats on CMPCTBLOCK’s received
This data was gathered from a node configured so that it would only receive CMPCTBLOCK announcements from our prefilling node, the main thing to see here is that reconstruction generally succeeds, the average reconstruction time metric is misleading, since we don’t count extra RTT’s that happen in the TCP layer in reconstruction time, just the time we receive the CMPCTBLOCK until the time we have reconstructed it.
49 out of 2793 blocks received failed reconstruction. (1.75%)
Reconstruction rate was 98.25%
Avg size of received block: 55851.93 bytes
Avg bytes missing from received blocks: 603.40 bytes
Avg bytes missing from blocks that failed reconstruction: 34393.55 bytes
Avg reconstruction time: 7.821697ms
This data was gathered from the node that sends prefilled compact blocks to its peers. Because this node is otherwise unmodified, we can use its measurements on the receiving side as a baseline for block reconstruction on nodes today.
1101 out of 2883 blocks received failed reconstruction. (38.19%)
Reconstruction rate was 61.81%
Avg size of received block: 15957.20 bytes
Avg bytes missing from received blocks: 47849.36 bytes
Avg bytes missing from blocks that failed reconstruction: 125294.91 bytes
Avg reconstruction time: 25.741588ms
There is a flaw in the window available bytes metric I have used, pointed out to me by @hodlinator, which is that I only did window_size - cmpctblock_size, and did not factor existing bytes queued to send to peers in vSendMsg. I anticipate this will have a small effect, but a branch which prefills up to the TCP window limit should take this into account.
Edit:
@andrewtoth has pointed out more complications in the available bytes metric: it will also have to take into account the current in-flight segments to the peer. On Linux, for example, this is tcpi_unacked (Multiplied by tcpi_snd_mss to get size in bytes). It will also have to account for bytes that are in the operating system’s send queue (tcpi_notsent_bytes). But I believe that because Bitcoin Core usesTCP_NODELAY the OS send buffer should generally be empty. On Linux, the sum of these two values can be obtained with SIOCOUTQ[1]:
int bytes_inflight_and_unsent, err;
err = ioctl(socket, SIOCOUTQ, &bytes_inflight_and_unsent)
The average CMPCTBLOCK we sent was 65732.80 bytes.
The average prefilled CMPCTBLOCK we sent was 91614.48 bytes.
The average not-prefilled CMPCTBLOCK we sent was 14483.78 bytes.
17536/26392 blocks were sent with prefills. (66.44%)
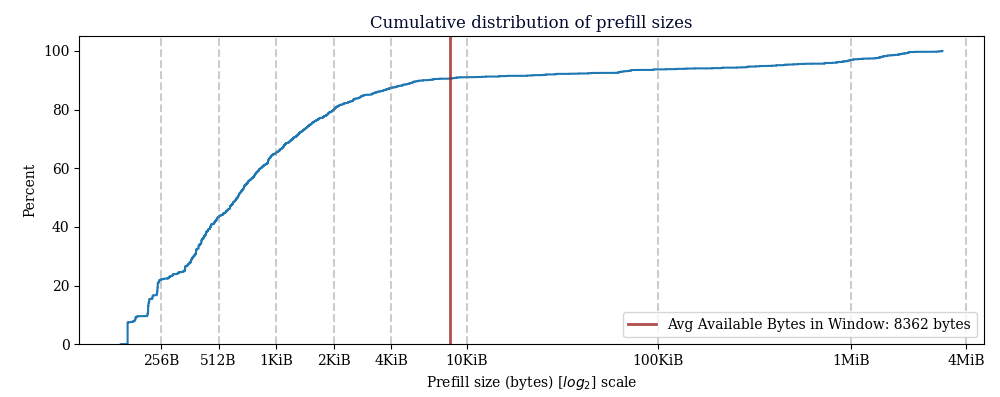
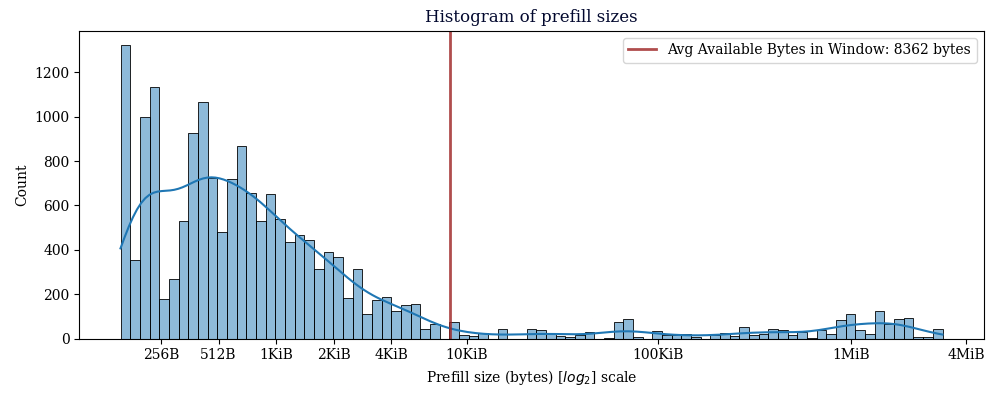
Avg available prefill bytes for all CMPCTBLOCK's we sent: 8679.14 bytes
Avg available prefill bytes for prefilled CMPCTBLOCK's we sent: 8362.04 bytes
Avg total prefill size for CMPCTBLOCK's we prefilled: 74593.04 bytes
15042/17536 prefilled blocks sent fit in the available bytes. (85.78%)
The average prefill size is notably large, but this is a consequence of some outlier blocks.
But, we can probably do even better, since the above statistics are for prefilling with all of the transactions in vExtraTxnForCompactBlock, and as I understand, it is very likely for peers running the same branch of Bitcoin Core to have a similar vExtraTxnForCompactBlock’s to one another. So it is likely that reconstruction will often succeed even without these transactions, so they should be the first candidates for not being included in the prefill. Unfortunately, their size is not something that Bitcoin Core logs, although I tried to compute it with a heuristic: prefill_size - missing_txns_we_requested_size, but it turned out this was very incorrect.
Overflowing window before pre-fill.
Interestingly, some compact blocks were already so large before prefilling that they required more than one TCP round-trip to be sent, while this circumstance is not ideal, prefilling performs better by taking advantage of this.
1432/26392 CMPCTBLOCK's sent were already over the window for a single RTT before prefilling. (5.43%)
Avg. available bytes for prefill in blocks that were already over a single RTT: 8555.57 bytes
1432/1432 excessively large blocks had prefills that fit. (100.00%)
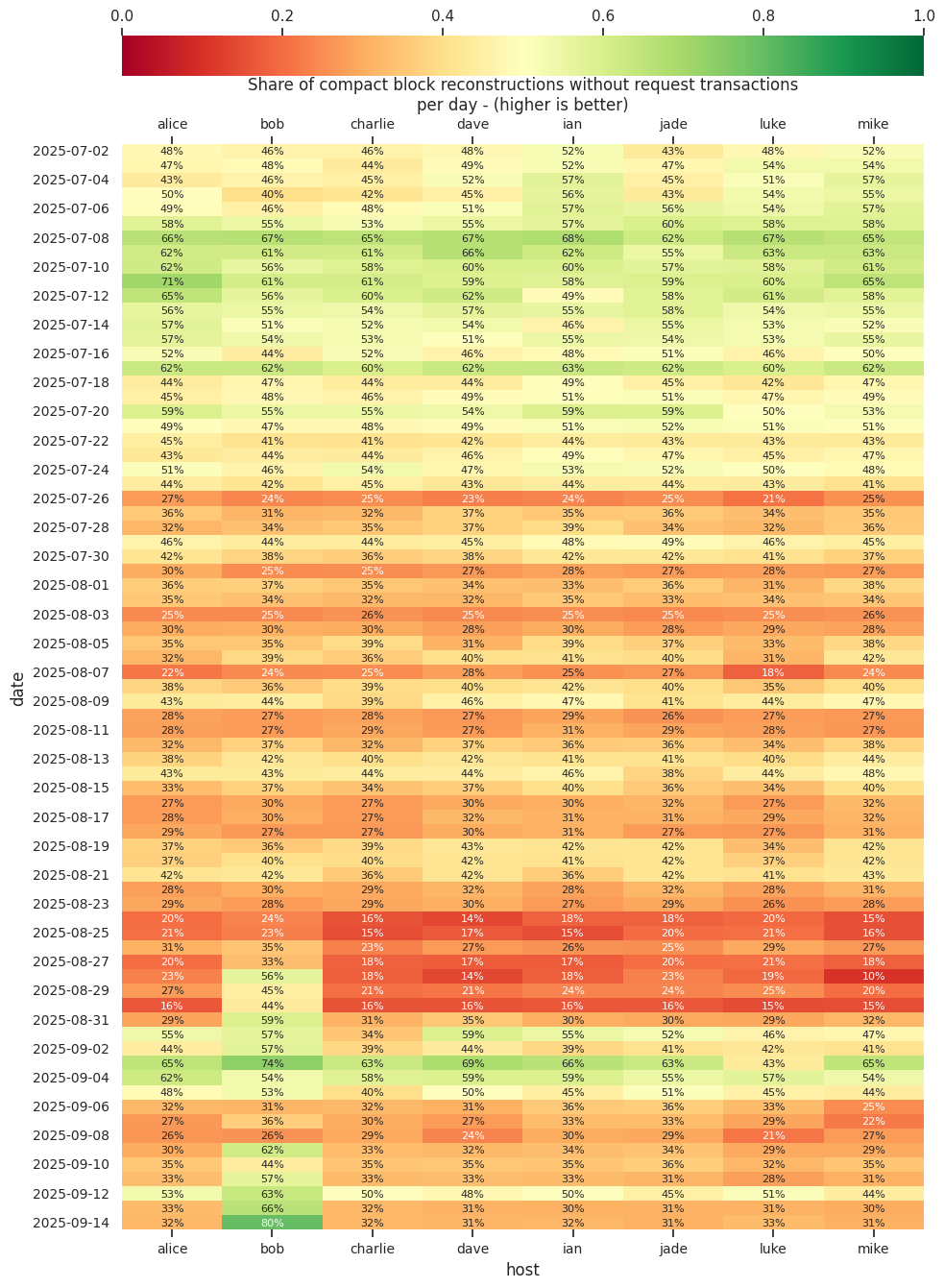
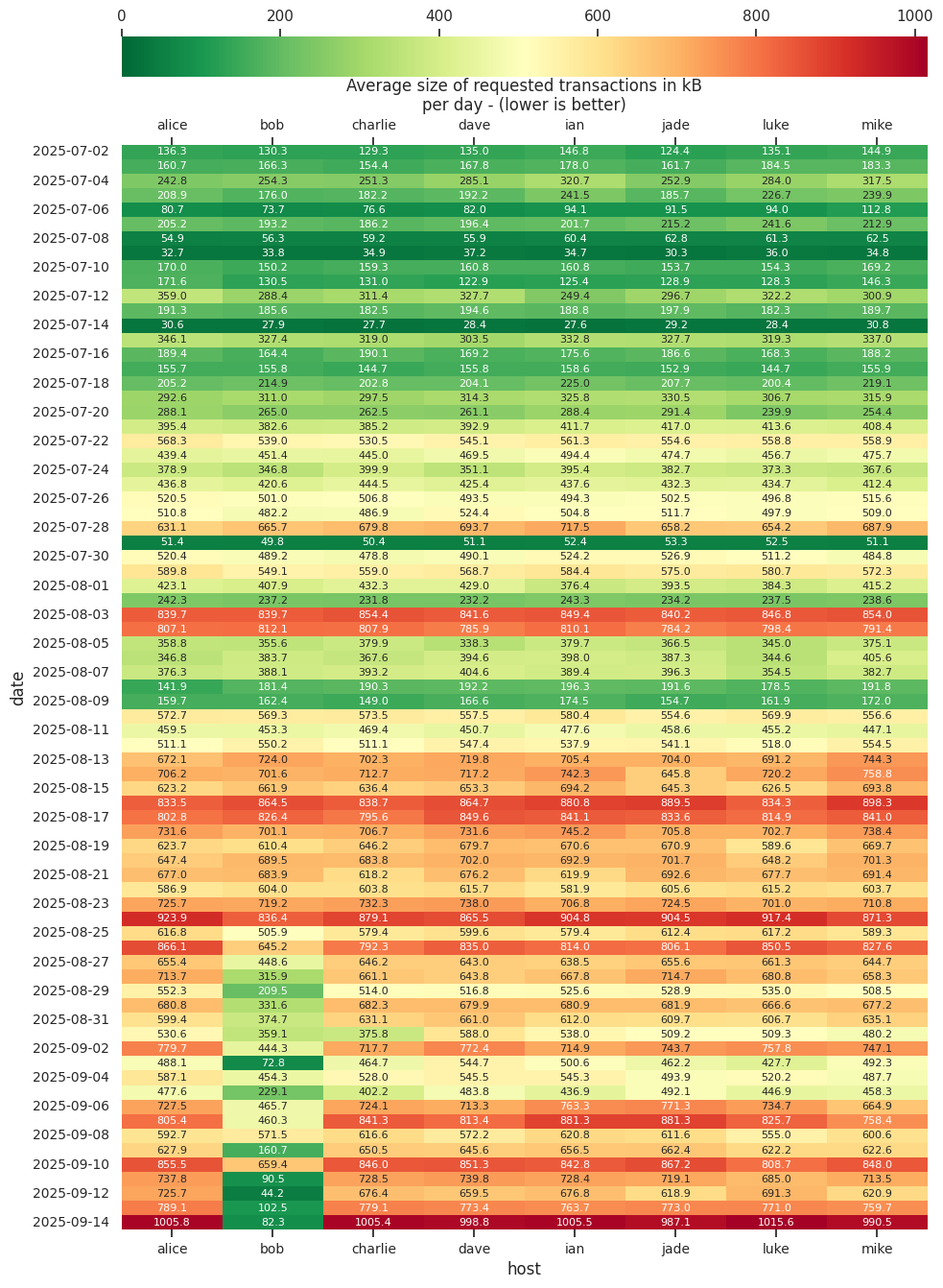
In early June we were requesting less than 10kB per block were we needed to request something (about 40-50% of blocks) on average. Currently, we are requesting close to 800kB of transactions on average for 70% (30% of the blocks need no requests) of the blocks.
Nice work on this @davidgumberg, this is very helpful. I have a few questions.
Within DoS limits (maybe a limit of 4 MiB per valid header), temporarily store a per-block cache of prefilled transactions you hear about, increasing the chances that you successfully reconstruct without having to wait for an RTT.
Is this because we have 3 HB peers and we want to combine prefills across them to try and reconstruct?
So far, I have assumed perfectly reliable networks and this isn’t always the case, packets get lost, and in TCP that means waiting for a timeout, and then retransmitting
I think it would be helpful to run this experiment where one of the nodes is on the other side of the world (maybe China?) to see what packet loss looks like and how that affects reconstruction times with/without prefilling.
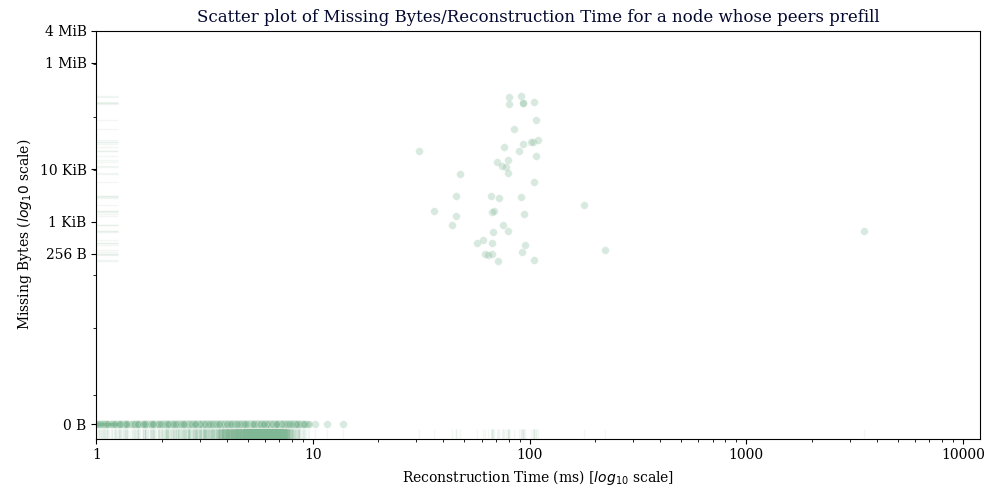
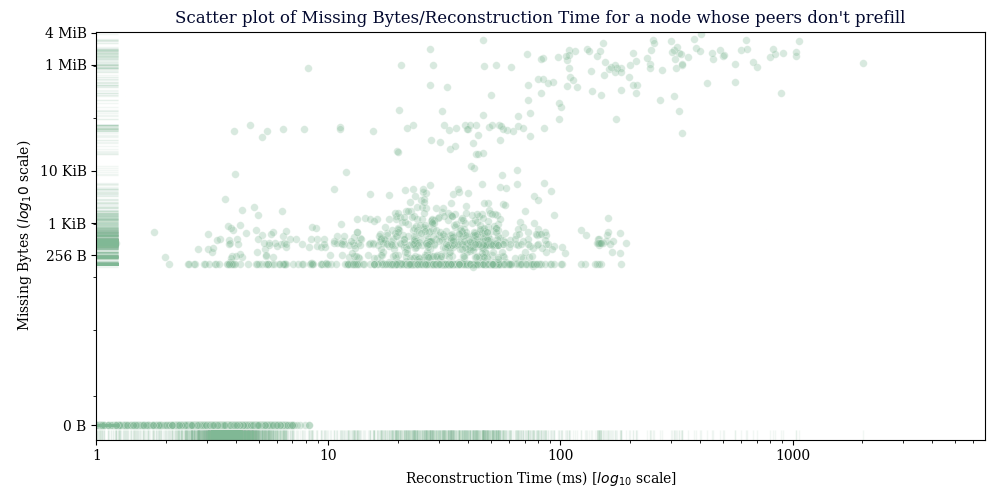
For the “Scatter plot of Missing Bytes/Reconstruction Time for a node whose peers don’t prefill”, some of the points have > 1 MiB missing and have reconstruction times at ~100ms. Do you know if these points are with peers with large window sizes? I would think that if that much data has to be sent across and the window sizes are ~14480, reconstruction times would be a bit higher… I’m wondering if you have any ideas on why the reconstruction times are low in those cases?
Edit: For the latency formulas, should they include the cost of transmitted data needed to reconstruct in the failure case? I know they are just to form an intuition, but I was also curious about that.
In this case, my goal wasn’t to test the PR (which had already been merged for over a week at the time I updated bob).
The goal is more: How does this change perform against what’s currently released and deployed on the network. While having another one or two nodes with this setup would have been nice for a bit more confidence in the data, running it on all other nodes would have made it impossible to compare old vs new.
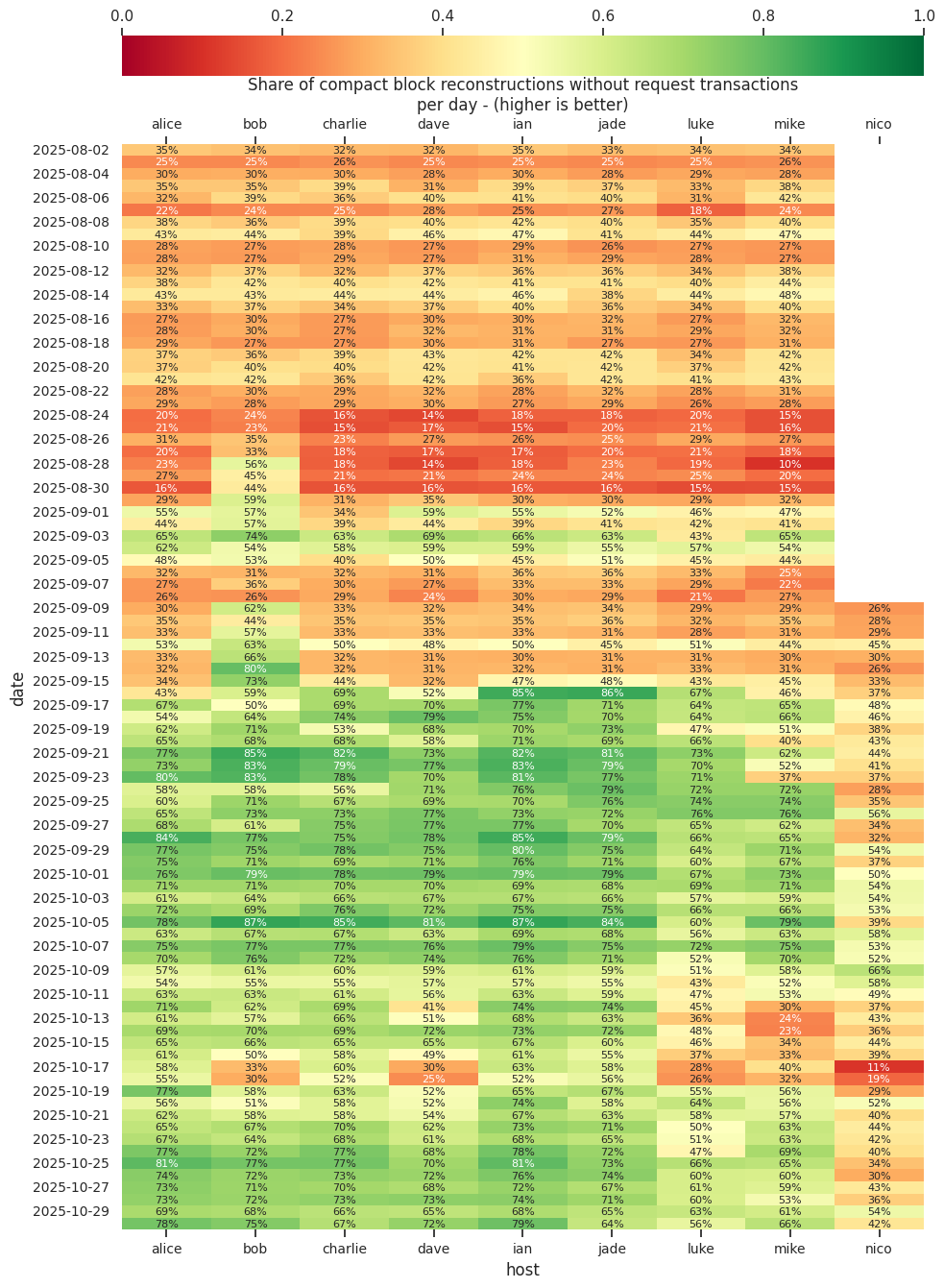
As part of my 30.0rc1 testing, the nodes now all run with the defaults decreased by 33106.
nico node is running knots in which blockreconstructionextratxnsize is added in v29.1 with 10 MB default and blockreconstructionextratxn limit is increased to 32768 transactions.
There may be other reasons for changes in compact block relay stats that I am unaware of.
Looking at recent block reconstruction, I’m seeing a fair few blocks that need between 100-4000 bytes of tx data. Including perhaps 5 FEC chunks at 1152 bytes each seems like it could catch most of those blocks without a round trip, and if you don’t try to merge chunks from different peers, there’s no complexity about dealing with mixed honest/adversarial inputs. I guess it depends on how scattered the missing transactions are on whether that actually works – six missings txs could easily only be 1000B but still hit 6 different FEC chunks.
As mentioned above, on 2025-09-17, I switched the nodes to run with a lowered minrelayfee. That’s also visible in both the reconstruction rate getting better and having to request a lot less data from peers for the cases where we can’t reconstruct. Bob was running with lowered a lowered minrelayfee since 2025-08-22. In hindsight, it would probably have been better to not update all nodes and keep a few on v29 to see how big the difference is (but these nodes aren’t solely for measuring block reconstruction, also for testing release candidates, which I felt was more important).
I’ve also been running a v29.1 Bitcoin Knots node nico with the default configuration. This node doesn’t include the logging added in https://github.com/bitcoin/bitcoin/pull/32582, so no data on requested transaction size.
I haven’t looked into what could caused the low reconstruction rates on bob, dave, luke and nico on 2025-10-18. (edit: LaurentMT suggested: “It was caused by transactions with dust outputs.”).
For the “Scatter plot of Missing Bytes/Reconstruction Time for a node whose peers don’t prefill”, some of the points have > 1 MiB missing and have reconstruction times at ~100ms. Do you know if these points are with peers with large window sizes? I would think that if that much data has to be sent across and the window sizes are ~14480, reconstruction times would be a bit higher… I’m wondering if you have any ideas on why the reconstruction times are low in those cases?
Unfortunately congestion windows are computed by the sender of a TCP datagram. I think it’s possible for the receiver to estimate the window size by looking at how many bytes are received before the sender stalls until a little bit after sender fires an ack. This would be good data to have for the next measurement, along with your other suggestion about locating the test nodes far apart from one another.
Edit: For the latency formulas, should they include the cost of transmitted data needed to reconstruct in the failure case? I know they are just to form an intuition, but I was also curious about that.
Definitely, thank you for catching this. Though, I don’t think this would affect the criterion since I think the the term would appear in both the prefilling case and the not prefilling case, so it would cancel, but I have to think more about this.
Within DoS limits (maybe a limit of 4 MiB per valid header), temporarily store a per-block cache of prefilled transactions you hear about, increasing the chances that you successfully reconstruct without having to wait for an RTT.
Is this because we have 3 HB peers and we want to combine prefills across them to try and reconstruct?
That’s what I had in mind, my hypothesis is that in the scenario that reconstruction fails on the first announcement, you are likely to receive a second CMPCTBLOCK announcement from another peer before you complete a GETBLOCKTXN roundtrip with the first HB peer, so it would be nice if we could leverage this to increase our chances of reconstruction without a roundtrip.
Random strategy
I originally imagined that each node would prefill a random selection from their prefill set when they can’t fit everything. But, assuming for simplicity that everyone has the same mempool, the probability of reconstructing from multiple prefills will be extremely low, where d is the number of draws (prefilled CMPCTBLOCKS received), n is the total number of missing transactions and k is the number of randomly prefilled transactions drawn in each CMPCTBLOCK, the probability of reconstruction is
This formula, and every other formula in this post makes the following simplifying assumptions, all of which are false in practice, but I suspect that none of the conclusions here change once they are removed: All transactions are equal in size, all nodes will have the same prefill candidate set, all nodes will have the same prefill size.
Derivation
Probability of missing a particular set of transactions
To calculate the probability of M_i, the event where a given transaction with index i is missing after drawing k many transactions from a pool of n transactions we want to know the proportion of ways to choose k from n that exclude 1 transaction from n, and the number of ways to choose k from n that excludes some member of n is equal to the number of ways to choose k from n-1, so:
P(M_i) = \frac{\binom{n-1}{k}}{\binom{n}{k}}
Likewise if you want to know the probability that two given transactions, i, j, are excluded:
Probability of missing any set of transactions of a given size
In our case, all sets of single transactions are just as likely to be missing, and all sets of two transactions are just as likely to be missing, and so on.
We can formulate the count of combinations where any 1 transaction is excluded (\sum _{i=1}^{n}|M_{i}|) as the number of unique sets of one transaction, times the count of combinations where a given set of one is excluded:
The count of combinations where any 2 transactions are excluded (\sum _{1\leqslant i<j\leqslant n}|M_{i}\cap M_{j}|) is the number of unique sets of two transactions multiplied by the count of combinations where a given set of two is excluded:
Probability of missing any set of transactions of any size
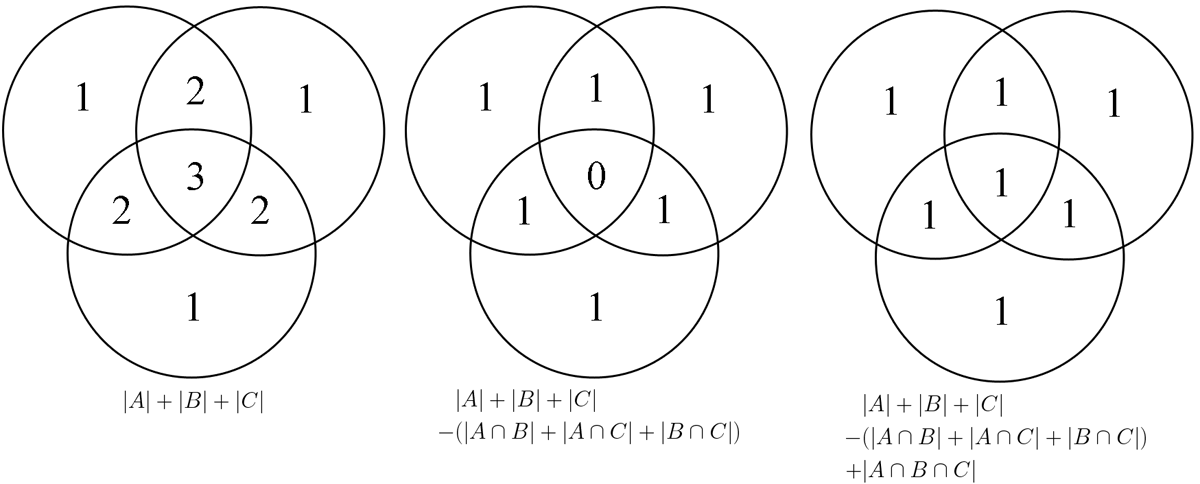
The probability of missing any set of any size is equivalent to the sum of probabilities of missing sets of each size, minus the overlaps, since in some of the events where we’re missing one transaction we’ll also miss two or more, and etc. For a formula for this we can use the Inclusion-exclusion principle:
This explanation and the graphic below are equivalent.
In plain speech, the count of events in A or B or C is the count of events in A, plus the count of events B, plus the count of events in C, so…
|A|+|B|+|C|
¡But!, this overcounts, since any event that is in both AandB (A \cap B) is counted twice, similarly with A \cap C and B \cap C, let’s deal with the intersections of two…
|A|+|B|+|C| - (|A\cap B|+|A\cap C|+|B\cap C|)
But, we undercounted, since |A|+|B|+|C| counts the events in A\cap B\cap C three times, but |A\cap B|+|A\cap C|+|B\cap C| also counts them three times since any event in all three is in any two, so we have to add them back…
Plugging in an example, if n = 100, k = 80 and d = 2:
P(\text{reconstruction}) = 0.66\%
Script for calculating
import math
# missing transactions needed for reconstruction
n = 100
# prefills per cmpctblock
k = 80
# number of cmpctblock messages received
d = 2
def p_one_or_more_missing(n, k, d):
assert k > 0 and n > 0 and d > 0 and k < n
# the greatest m for which n - m >= k
m_max = n - k
return sum(
(-1)**(m + 1) * math.comb(n, m) * (math.comb(n - m, k) / math.comb(n, k))**d
for m in range(1, m_max + 1)
)
p_reconstruction = 1 - p_one_or_more_missing(n, k, d)
print(f"P(reconstruction) = {p_reconstruction * 100:.4f}%")
Sliding window strategy
A better strategy was suggested in an offline discussion by @hodlinator which the following is a variation of:
Each prefiller selects a random offset i from the start of their prefill set, and prefills up to the window limit, looping around if they reach the end.
When d = 2
Assuming that all peers have the same prefill set N, for d=2, the probability of reconstruction is:
(Where m_1 = n-k, the size of the missing transaction set after one draw.)
Since we continue from the beginning (N_1) of the missing transaction set N when we reach the last transaction N_n: All subscripts i in N_i are i \mod{n} as in N_{(i \mod{n})}. So N_n might also be written N_0.
Note that if we start at some index N_i and take x transactions, we’ll get up to N_{i+x-1} and not N_{i+x} since we have to count taking N_i.
The “missing set” is the transactions that a node is still missing after one or more prefills. If n (|N| or size of the prefill candidate set or number of transactions in the block missing from mempool) is greater than k (the prefill size measured in transactions), than the missing set has a size m=n-k.
At any time, the missing set will be a continuous sequence of transactions from the prefill candidate set N uninterrupted by any prefilled transactions, as long as no prefiller’s k is less than any other prefiller’s m=n-k, since after the first draw the missing set is continuous, and the only way to create a gap in the continuous missing transaction sequence is to pick a transaction in the missing sequence, but not reach the end of the missing sequence, which is not possible if k > m. This is fine to assume for now, since for this formula we are assuming that every node has the same k and the same n.
As long as the missing set is continuous, and k < n (if not, success is inevitable) and k \geq m (if not, success is impossible) the size of the set S of initial transactions for our prefill that will succeed:
|S| = k - m + 1
Since:
Beginning with the case when k, the prefill set size, and m, the missing set size, are equal, there is only one way to succeed (|S| = 1), by starting the prefill at the first member of the missing set (N_i = M_1): No other value of i will work as long as k < n, since if we advance i one forward, we will miss the first member of the missing set (M_1). If we didn’t miss the first member of the missing set, then we have just reached N_i-1 starting from N_i and advancing to N_{i+k-1}, meaning that:
i + k - 1 \geq n + i - 1
so
k \geq n
But, we said that k < n, so this is absurd.
Likewise, if we retreat i one back, we will miss the last member of the missing set M_m
M_1 = N_i
thus
M_m = N_{i+m-1}
If we start at N_{i-1} and draw k == m as supposed:
N_{i-1+k-1} = N_{i+k-2} = N_{i+m+2}
We will only reach N_{i+m-2} = M_{m-1}.
Likewise, if k = m + 1, we still can not advance the starting transaction even one forward from N_i = M_m, for the same argument as put forth above, summarized: as long as k < n (in which circumstance the prefill would succeed anyways), we will not reach the transaction just before the one we started with, so we will fail.
But, we can now advance one further back, starting at N_{i-1} where N_{i} = M_1, since:
If we start at N_{i-1} and draw k many transactions:
N_{i-1+k-1} = N_{i+k-2}
But, since:
k = m + 1
It follows that:
N_{i+k-2} = N_{i+m+1-2} = N_{i+m-1}
But,
M_m = N_{i+m-1}
So we reached M_m starting at N_{i-1} with k = m + 1.
\text{QED}
For the same reasons, if we made k = m + 2, there would be one more way, (totalling three) to succeed.
Since starting at k=m, |S| = 1, and for each increment k grows by 1, |S| grows by 1:
|S| = k - m +1
And since the probability of success P_{\text{reconstruction}} = \frac{|S|}{n}:
And simplifying the bounds for this formula, for two draws, if k < m on the second draw, then n \leq 2k, so k < m whenever:
k < n \leq 2k
Also:
|S|=k - m + 1
where m is the number of transactions missing after the previous prefills.
From this we also know the size of the set of transaction indexes that result in failure F:
|F| = n - (k - m + 1)
End derivation
Taking the same example as above, where n = 100, k = 80, d = 2:
P_{\text{reconstruction}} = 61.00\%
When d = 3
For d = 3 (we receive a CMPCTBLOCK from all 3 of our HB peers), the formula is different:
Not very rigorous, but this is my argument, you probably need to read the derivation for d=2 to follow,
Looking up to what we proved in derivation of the previous formula:
|S|=k - m + 1
so
|F| = n - (k - m +1) = n - k + m - 1 = m + m - 1 = 2m -1
On the third draw, m varies depending on what was selected for the second draw. In the worst case, if the same i is selected as the starting index in the first prefill and the second, m=n-k. Similarly |F| is unchanged, the second draw has not reduced the number of ways to fail. But every other possible i on the 2nd prefill will remove some transactions from the missing set M, and F will shrink as a result, since |F|=n - k + m - 1. So, when M loses a member, F loses a member, and vice versa.
Also note that after one draw, |F| = 2m-1, so |F| will always be an odd number after one draw.
Let’s take an example, n = 10, k=7, if the first prefill chooses i=1, then M = \{8, 9, 10\} will be missing, the set of i for which reconstruction will fail on the second draw are F = \{1, 2, 3, 9, 10\} (|F|=2(3)-1=5). If the second draw is the same as the first (i=1), the situation doesn’t change, the missing set is unchanged, M = \{8, 9, 10\}.
But, if the second draw was e.g. i=2, 8 is removed from M, so 9 (and only 9) is removed from the failure set. Likewise, if the second draw was 10, 3 would no longer be a failure condition. In both of these cases one transaction is removed from M, so |F| shrinks by 1.
Similarly, for both i=3 and i=9, two members of the missing set are removed (\{8, 9\} and \{9, 10\} respectively) so in each case, there are two fewer ways to fail.
I think this could be made more rigorous, but I make the argument in a soft and squishy way:
As argued above, the missing set will always be continuous. And if m \geq 2 there will be two ways to remove exactly 1 member from the missing set. Since, you can either start at the last missing transaction M_m and remove that transaction, or you pick some other index i which ends on the first transaction of the missing set N_{i + k -1} = M_1. Any other i will either remove more members from M than 1 or fail to remove 1. If m = 2, then there are |S| as given above ways to remove 2 members.
Likewise for m \geq 3 there are exactly two N_i in N that will remove two members from M, and so on.
This is all with the notable exception stated above, that there is one way for the missing set to remain unchanged on the second draw if n \leq 2k, which is to pick the same index as before.
Please note, I am using m_1 as shorthand for n-k OR m after 1 draw in the following formulas, this is because m is varying.
And so, to count the total number of ways to fail that are removed (r) if the 2nd draw was favorable, there are two ways for it to be lesser by one, two ways for it to be less by two, and so on until m-1:
r = \sum_{i=1}^{i=m_1-1}{2i}
If we assumed that the number of ways to fail was always maximally bad after the 2nd draw, no matter what it was, the number of ways to fail on the 3rd draw would be (2m_1-1)^2. But, if we take into account the fact that some ways to fail are removed:
|F| = (2m_1-1)^2 - r = (2m_1-1)^2 - \sum_{i=1}^{i=m_1-1}{2i}
And this can be simplified since r is the sum of an arithmetic series:
r = \sum_{i=1}^{i=m_1-1}{2i} = 2\sum_{i=1}^{i=m_1-1}{i} = 2\frac{m_1(m_1-1)}{2} = m_1(m_1-1)
Why not just tell your peer “offset=[0,1,2]” when selecting it as HB? Should work fine if the peer is honest, and a dishonest peer can just give you a bad prefill anyway.
I agree, with a protocol change where you give your HB peers a hint about which index to start at, you could definitely do better, this was the best I could think of if you can’t coordinate.
I’ve been logging from block 918234 to block 924597 (~6 weeks) transactions rejected by my mempool that were requested later during block reconstruction.
The log messages I am taking into account for this are:
#2025-08-28T23:01:08Z [mempoolrej] d92185c34f804047a9b58d5279ef0009f3bf06a4c9b32ef19544f7698498a8d7 (wtxid=d92185c34f804047a9b58d5279ef0009f3bf06a4c9b32ef19544f7698498a8d7) from peer=6 was not accepted: bad-txns-inputs-missingorspent
Note that code has been modified to log all requested transactions for block reconstruction. By default core only logs them if we miss less than 5 transactions.
The node runs a fork of master on top of commit “084fd68fda2c604a873f0f54c0c3723850509019”. Where the new min feerate policy was already applied.
It runs only on clearnet and has everything by default.
The results I have are:
First block in log: 000000000000000000002edea05decf1f5a1254b997b8e71a603d7c8a35248e3
Last block in log: 0000000000000000000047d48ba177fefa4ef2cd2bff814c82381bb34ff3571d
----------------------------------------
--- Transaction Reason Counts (Grouped) ---
bad-txns-inputs-missingorspent: 1376
insufficient fee: 1130
txn-same-nonwitness-data-in-mempool: 54
non-BIP68-final: 49
min relay fee not met: 20
too-long-mempool-chain: 12
replacement-adds-unconfirmed: 9
too many potential replacements: 9
dust, tx with dust output must be 0-fee: 3
txn-already-known: 2
Note that insufficient fee means insufficient fee for replacement.
I checked a few of those txs randomly and they are in the orphanage until the block reconstruction happens, but they are not used for it. We are re-requesting transactions that we already have.
I am not really familiar on how the orphanage and extrapool interact between them but seems that it could be interesting to not store orphanages in the extrapool and iterate the orphanage also on blockreconstruction?
Log example for one transaction
2025-10-21T17:20:32Z [net] got inv: tx 78f62ba425eaf69f0195f155beef4cf009a3c3674c8a63abbf49b1097bbadce8 new peer=46406
2025-10-21T17:20:33Z [net] got inv: wtx 8e1072d4bd2eb852407776ea5facf631f005e28bb7d93f4628e6ae14eabad3fe new peer=47613
2025-10-21T17:20:35Z [net] Requesting wtx 8e1072d4bd2eb852407776ea5facf631f005e28bb7d93f4628e6ae14eabad3fe peer=47613
2025-10-21T17:20:35Z [mempoolrej] 78f62ba425eaf69f0195f155beef4cf009a3c3674c8a63abbf49b1097bbadce8 (wtxid=8e1072d4bd2eb852407776ea5facf631f005e28bb7d93f4628e6ae14eabad3fe) from peer=47613 was not accepted: bad-txns-inputs-missingorspent
2025-10-21T17:20:35Z [txpackages] added peer=47613 as a candidate for resolving orphan 8e1072d4bd2eb852407776ea5facf631f005e28bb7d93f4628e6ae14eabad3fe
2025-10-21T17:20:35Z [txpackages] stored orphan tx 78f62ba425eaf69f0195f155beef4cf009a3c3674c8a63abbf49b1097bbadce8 (wtxid=8e1072d4bd2eb852407776ea5facf631f005e28bb7d93f4628e6ae14eabad3fe), weight: 558 (mapsz 1508 outsz 336)
2025-10-21T17:20:35Z [txpackages] added peer=46406 as a candidate for resolving orphan 8e1072d4bd2eb852407776ea5facf631f005e28bb7d93f4628e6ae14eabad3fe
2025-10-21T17:20:35Z [txpackages] added peer=46406 as announcer of orphan tx 78f62ba425eaf69f0195f155beef4cf009a3c3674c8a63abbf49b1097bbadce8 (wtxid=8e1072d4bd2eb852407776ea5facf631f005e28bb7d93f4628e6ae14eabad3fe)
2025-10-21T17:20:37Z [txpackages] added peer=29197 as a candidate for resolving orphan 8e1072d4bd2eb852407776ea5facf631f005e28bb7d93f4628e6ae14eabad3fe
2025-10-21T17:20:37Z [txpackages] added peer=29197 as announcer of orphan tx 78f62ba425eaf69f0195f155beef4cf009a3c3674c8a63abbf49b1097bbadce8 (wtxid=8e1072d4bd2eb852407776ea5facf631f005e28bb7d93f4628e6ae14eabad3fe)
2025-10-21T17:20:37Z [net] got inv: wtx 8e1072d4bd2eb852407776ea5facf631f005e28bb7d93f4628e6ae14eabad3fe have peer=29197
2025-10-21T17:20:39Z [net] Requesting tx 78f62ba425eaf69f0195f155beef4cf009a3c3674c8a63abbf49b1097bbadce8 peer=46406
2025-10-21T17:20:39Z [net] Requesting tx 78f62ba425eaf69f0195f155beef4cf009a3c3674c8a63abbf49b1097bbadce8 peer=47613
2025-10-21T17:20:41Z [net] Requesting tx 78f62ba425eaf69f0195f155beef4cf009a3c3674c8a63abbf49b1097bbadce8 peer=29197
2025-10-21T17:20:50Z [txpackages] added peer=47326 as a candidate for resolving orphan 8e1072d4bd2eb852407776ea5facf631f005e28bb7d93f4628e6ae14eabad3fe
2025-10-21T17:20:50Z [txpackages] added peer=47326 as announcer of orphan tx 78f62ba425eaf69f0195f155beef4cf009a3c3674c8a63abbf49b1097bbadce8 (wtxid=8e1072d4bd2eb852407776ea5facf631f005e28bb7d93f4628e6ae14eabad3fe)
2025-10-21T17:20:50Z [net] got inv: wtx 8e1072d4bd2eb852407776ea5facf631f005e28bb7d93f4628e6ae14eabad3fe have peer=47326
2025-10-21T17:20:52Z [net] Requesting tx 78f62ba425eaf69f0195f155beef4cf009a3c3674c8a63abbf49b1097bbadce8 peer=47326
2025-10-21T17:21:00Z [txpackages] added peer=29051 as a candidate for resolving orphan 8e1072d4bd2eb852407776ea5facf631f005e28bb7d93f4628e6ae14eabad3fe
2025-10-21T17:21:00Z [txpackages] added peer=29051 as announcer of orphan tx 78f62ba425eaf69f0195f155beef4cf009a3c3674c8a63abbf49b1097bbadce8 (wtxid=8e1072d4bd2eb852407776ea5facf631f005e28bb7d93f4628e6ae14eabad3fe)
2025-10-21T17:21:00Z [net] got inv: wtx 8e1072d4bd2eb852407776ea5facf631f005e28bb7d93f4628e6ae14eabad3fe have peer=29051
2025-10-21T17:21:06Z [net] Requesting tx 78f62ba425eaf69f0195f155beef4cf009a3c3674c8a63abbf49b1097bbadce8 peer=29051
2025-10-21T17:32:07Z [cmpctblock] Reconstructed block 0000000000000000000005d578e2ed197675684b0e9d57e19081b18879179804 required tx 8e1072d4bd2eb852407776ea5facf631f005e28bb7d93f4628e6ae14eabad3fe
2025-10-21T17:32:08Z [txpackages] removed orphan tx 78f62ba425eaf69f0195f155beef4cf009a3c3674c8a63abbf49b1097bbadce8 (wtxid=8e1072d4bd2eb852407776ea5facf631f005e28bb7d93f4628e6ae14eabad3fe) (5 announcements)
If they’re in the orphanage, then that means we don’t have its parent. If it’s also in a block, that means the parent is in the block, and since we don’t have it, a round-trip is necessary anyway. You might get a small reduction in bandwidth by not getting an additional copy of the orphan, but likely don’t save much actual time.
(Unless there’s a bug in the orphanage, and we do have the parent; or perhaps the parent was also recently replaced but is still in extra txns, so available for block reconstruction but not orphan resolution)
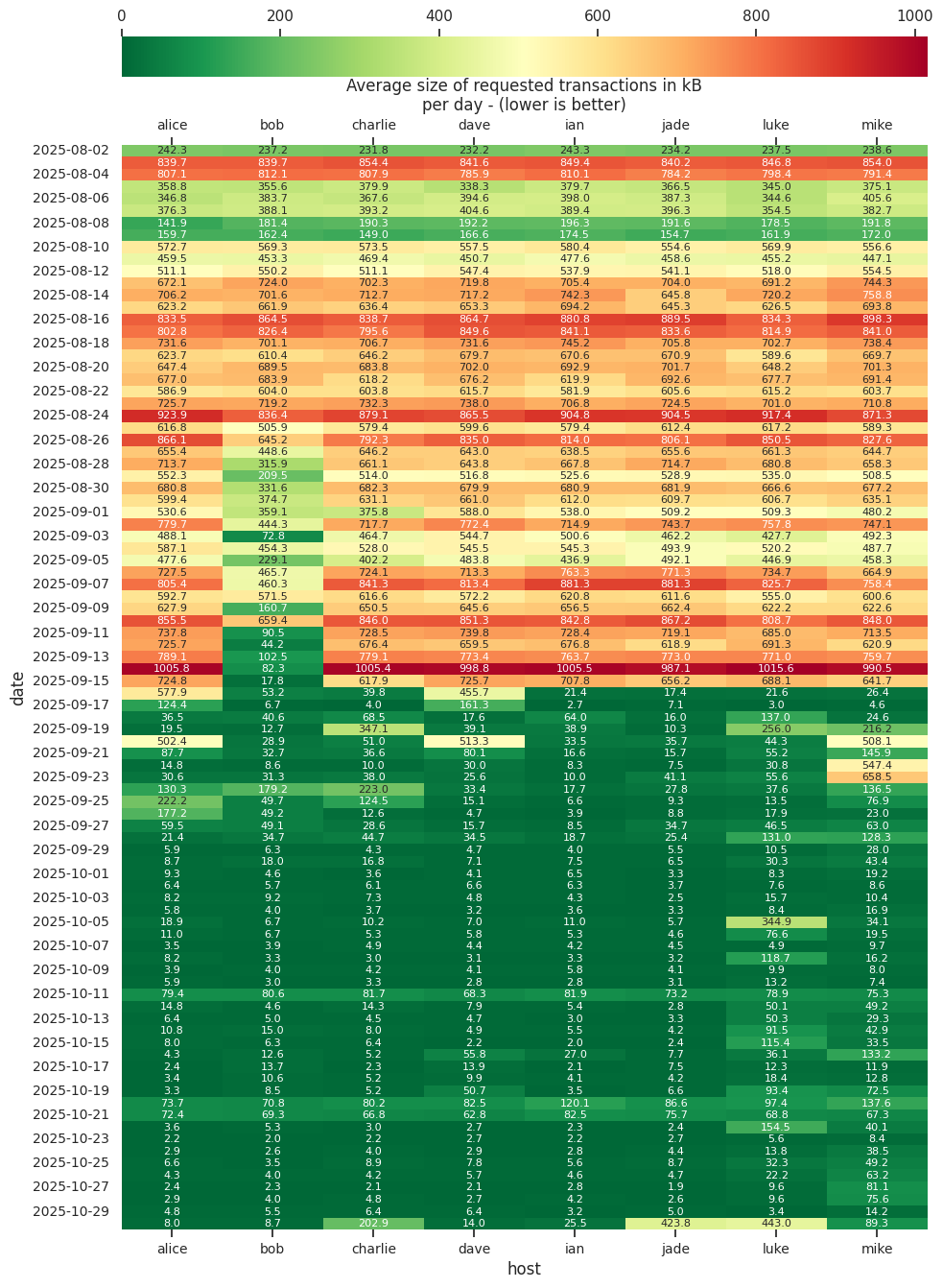
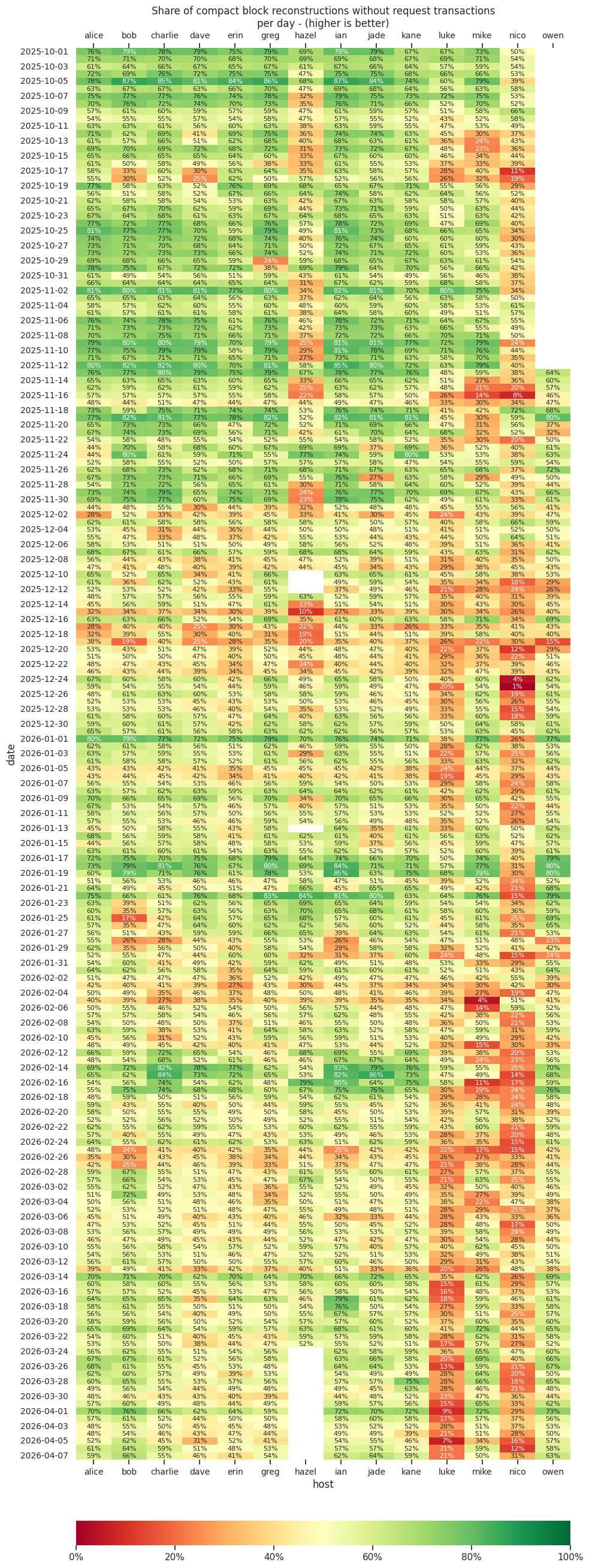
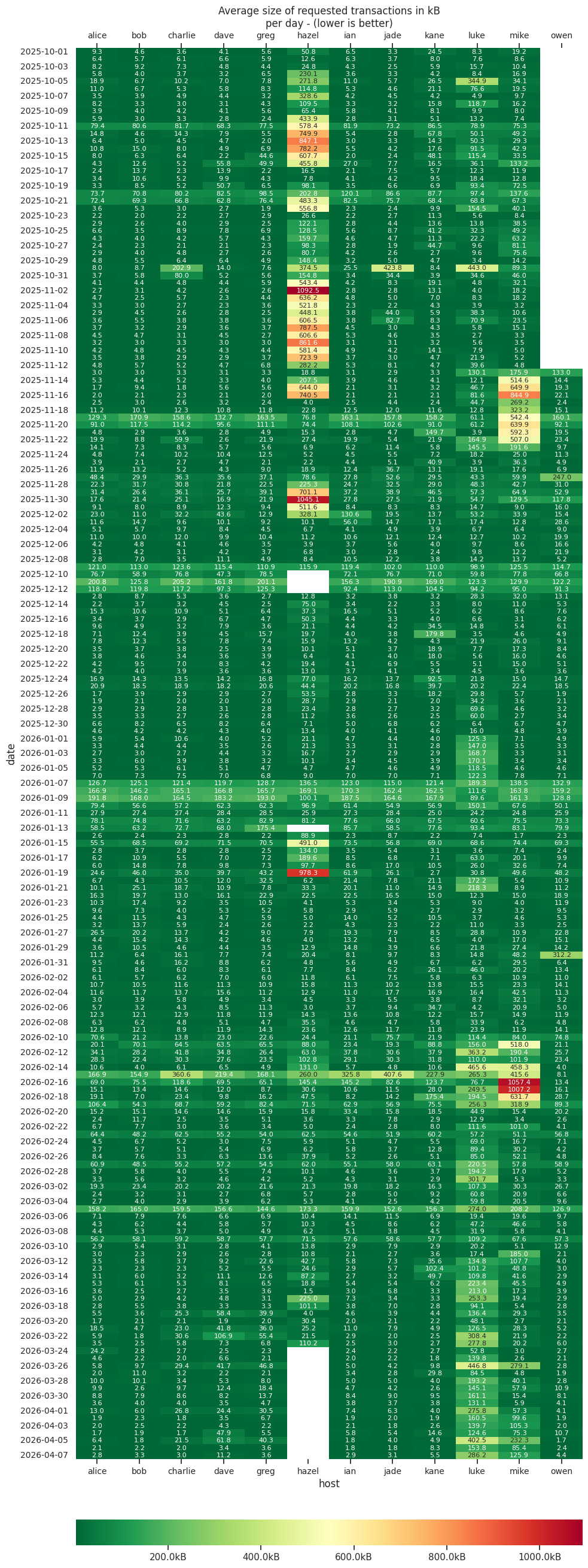
It’s been a while! I generated some stats again from my debug.logs. Reconstruction rates are far from perfect, but also not horrible. For the most part, we’re requesting tens of kB worth of transactions on average.
Notes:
The binary on host luke has sanitizers enabled and is struggling a bit with high CPU usage.
The host nico is running Knots (yeah, I known, why isn’t this one called luke…?)