I’m sketching up an sv2 extension, that allow miners to verify pool’s payouts when miners are allowed to select transaction hence mining jobs with different fees.
The extension is based on a system proposed here this system is build on top of PPLNS.
In a time where the Bitmain FPPS debt-slavery cartel is pushing Bitcoin towards dangerous levels of mining centralization, this post is extremely relevant and I would love to see more engagement from mining players here.
The ideas presented on the paper titled PPLNS with Job Declaration are academically sound and it’s refreshing to see that Demand Pool has some talented minds proposing a tangible path out of the dark situation Bitcoin is currently under.
Remember that while SV2 allows for hashers to choose their own templates via Job Declaration (JD), the protocol itself is inherently agnostic to:
share accounting
reward distribution
So when a pool decides what kind of algorithms to employ to solve those two specific problems, their design space is limited to:
hashers blindly trusting the pool is fair
feeding back information to hashers to minimize trust
And if they choose the second path, they will inevitably need protocol extensions.
Now, SV2 decentralizes via JD!
Which means hashers have the right to be paid for hashing on templates that could be economically suboptimal with regards to fee revenue… that could happen for different reasons:
maybe the hasher’s Template Providing (TP) node is suboptimally connected (remote location, poor internet, plebhashers) and the “mempool” they see is suboptimal.
maybe they are ideologically driven and see some categories of consensus-valid transactions as spam (which is a subjective term, albeit introduced by Satoshi and ingrained into protocol primitives).
maybe they want to do MEVil and prioritize transactions under some specific meta-protocol.
maybe they want to filter out consensus-valid transactions that would hurt low-end nodes (see GCC for more).
So an economically rational pool needs a mechanism to still allow for jobs with low-revenue templates, while rewarding them fairly with regards to jobs with more economically optimal templates, which is work that deserves to be rewarded more.
And in order for hashers to be willing to put some level of trust on the pool, they need to be fed back some info to give them reassurance about how their templates are being rewarded fairly in proportion to other hashers. That is exactly what this new SV2 protocol extension proposes, and I’m happy it’s built on top of PPLNS, rather than FPPS.
I’m looking forward to following this Discussion on SRI repo, where Braiins, Demand, and SRI engineers are shaping up the implementation details for the first ever SV2 protocol extension.
As a pleb advocate, I’m particularly curious how the proposed SV2 extension would affect transactions described under GCC, which would essentially penalize low-end nodes, even if they:
pay high fees
are consensus-valid
are available in the so called “Standard/Canonical/Platonic” mempool
Let’s call these transactions as GCC vectors.
How should a SV2-JD-enabled Pool take that into account? I see three options:
A. reject all jobs that include GCC vectors in the proposed templates (as a JD policy)
B. impose economical penalties to jobs that include GCC vectors in their template (as a reward policy)
C. ignore GCC vectors
The proposed extension is not really relevant for option A, since the basic SV2 primitives already allow for that.
Option B does have some relevance here, and I’m curious as to whether this is being taken into account in the design of the proposed extension.
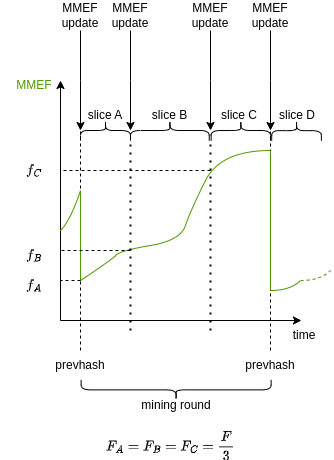
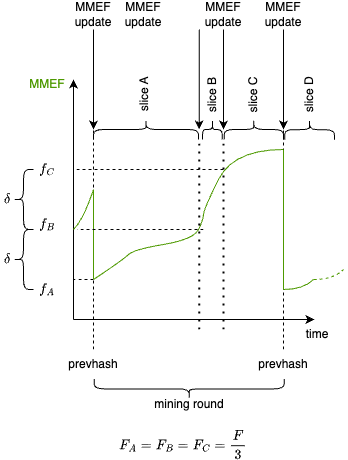
We only look at total fee payed by the mined[1] job, respect to the jobs in the same slice. So we will not penalize anything we can say that pool take an agnostic approach.
But that is fully understandable, since it shouldn’t be up to pools nor hashers to act as “benevolent guardians” of low-end nodes. Ideally, this is something to be addressed at the consensus level, not mining.
What prevents a pool from diluting shares within a slice/window?
I think this protocol makes sense but still suffers from the same issue that pools suffer from now, all of the validation data being used by miners is given out by the pool.
I think there’s a way forward with blinded signatures here that makes each proposal more robust. I’m not sure what that looks like yet but will post when I have someothing on the topic.
The client gives the server a list of id’s (how is this list of IDs determined?) of shares they want to validate, I understand this piece. There is just no guarantee that the pool is providing accurate information. This is the same as using an API to query for shares.
What stops a pool from providing inaccurate or misleading share data? or omitting shares when requested?
Edit: Inaccurate or misleading shares would fail the Merkle inclusion validation piece. but omission remains un answered.
this is not needed cause when you get the actual share you can verify that the is the share at position x in the slice, so is the one that you required
A miner can solve this issue by asking the pool a bunch of consecutive shares, containing some produced by the miner itself. Since a miner knows the position in the slice of the shares he produced, becomes very difficult to perform the trick you said.
BTW I cannot see the incentive for doing so. I think the most likely scenario is when the pool is a miner and produces fake shares. Recall also that this issue affects also standard PPLNS and has nothing to do with job declaration.
we can add the index in the merkle root I think that would be better
You could use the share index to determine Merkle tree ordering for the slice, this would prevent the scenario I outlined above. IIUC, this would also give the client some idea as the what the Merkle path should look like for a given share.
yep cause index depend on window, so slice root would be different based on the window on which belong. I have to look better into it, but it seems feasible.
There is a typo. There should be 0=k_0<k_1<\dots < k_t = N, where N is the number of shares in the PPLNS window such that the m-slice contains the shares s_{k_{m-1}+1}, \dots , s_{k_{m}}. Recall that, by Remark 5 in Section 3.2, if S is a slice, we have that
\sum_{s \in S} score_f(s) =1.
Hence
Remove merkle_path from the share, the field is redundant cause we can derive it from the transactions in the job, later in the verification procedure.
Add share_index: the index of the share in the slice. This solve the issue raised above by @marathon-gary (there is no way for a miner the check if the share sent by the pool are the ones required)
Is the delta for determining a new slice dynamic or static? I suppose that’s left up to the pool or implementer of the payout schema, but am curious about that.
@plebhash I think I was wrong in our discussion about this.
Hi!
Just to mention that a new version of the article is available. I would like to thank @plebhash and @marathon-gary, that reviewed the article and made a lot of useful suggestions/corrections
Update ext spec, add PHash data type, needed by the miner to verify the share’s work
The PHash message includes the previous hash and the starting index of the slices that use it. This message is sent within the GetWindowSuccess response, enabling the miner to identify which slices correspond to which previous hash, and thereby determine the previous hash for each share. This information is essential for verifying the work of each share.
I’m a bit worried about miners proposing fake block templates with absurdly high fees, thereby enjoying a relatively large payout.
This seems worse than block withholding, because such a miner could run a way with ~100% of the block reward with ~0% of the PoW.
The obvious counter measure is for the pool (or separate Job Declarator server entity, JDS) to verify every template. But this a non-trivial task, since the JDS node mempool could be very different. It may need to replace transactions its mempool with that of the template to check that it doesn’t contain a big fee transaction that’s actually unspendable.
Absurdly high fees would always trigger a new slice, so you can at least prioritize its verification.
For coinbase-only templates the JDS doesn’t know the transactions and can’t verify anything.
It’s also unclear how, in the random sample verification protocol, you would distinguish a malicious miner from a malicious pool making such templates for themselves (and ‘accidentally’ approving them).
Perhaps a simpler solution is to cap the fees for all slices to whatever fees were in the found block. The fake templates, if not caught, would then have their fees reduced to a level that at least in principle they could have found. Then it’s not much worse than regular block witholding.
This also creates a disincentive to produce high value templates with ‘secret’ transactions. Template providers will want everyone else to have the good stuff in their mempool too.
This seems worse than block withholding, because such a miner could run a way with ~100% of the block reward with ~0% of the PoW.
If a miner is providing ~0% of the PoW, then he would get ~0% of blocks subsidy and ~0% of the block fees, because the fee-based score is calculated on top of the difficulty based score. Suppose that a slice contains the shares from ther k_1-th to the k_2-th. Suppose also that the fee and the difficulty score of the i-th share are f_i and \bar d_i. Then
score_f(i) = \frac{\bar d_i f_i}{\sum_{j=k_1}^{k_2}\bar d_j f_j}. If \bar d_i \approx 0 then this score_f(i) \approx 0.
The easiest architecture is that each pool run its JDS. In this case, the JDS validates each share. In the SRI, the JDS runs a light mempool just for faster recognition of the transactions. If there is some unknown transaction during validating the shares, then it will be asked to the miner through “PovideMissingTransactions” message, as for Sv2 protocol.
For coinbase-only templates the JDS doesn’t know the transactions and can’t verify anything.
I understand that “coinbase-only templates” is a share with just the coinbase transaction, so it is an “empty weak block”. But then you refer at the transactions, so there is more than one. I do not understand, can you explain?
Perhaps a simpler solution is to cap the fees for all slices to whatever fees were in the found block.
This reflects the state of the mempool when the blocks is found. If a share is produced in a moment in which the MMEF (mempool maximum extractible fees) is much less then the fee found in the block, then the share is devalued, even though the miner is very good at maximizing fees. This is not fair IMO.
It’s also unclear how, in the random sample verification protocol, you would distinguish a malicious miner from a malicious pool making such templates for themselves (and ‘accidentally’ approving them).
I don’t quite understand what you mean. Perhaps is worth pointing out that one of the main concerns is when the pool is also a miner, so there are some incentives for the pool to pay more for the fees it produced. Since a shares are public and those which are not valid can be spotted easily, one possible way the pool can cheat is by reordering shares by putting them in a slice with reference job that a a lower fee. But it is not trivial, because the job of the share must be compatible with the reference job, and fixing it involves timestamps or pointers, but this is outside the scope of the article.
If the JDS is an independent service, then we must take into account the fact that can service for different pools. In this setting, I think that each pool must communicate the JDS the coinbase outputs and each miner must communicate the pool that it is working for. Apart from this, seems to work exactly as it currently working in the SRI.
I assume you mean each proposed template (DeclareMiningJob), not each share?
If there is some unknown transaction during validating the shares, then it will be asked to the miner through “PovideMissingTransactions” message, as for Sv2 protocol.
This takes time and bandwidth. And in order to verify if the new transaction is actually valid the JDS has to insert it into its mempool. And in order to do that it may need to evict other conflicting transactions first. Doing this for every DeclareMiningJob may not scale very well.
I’m referring to a recent proposal that allows a DeclareMiningJob message with just a merkle proof for the coinbase transaction, without revealing which transactions are in the block.
I can’t find the link to the actual propososal, just a reference to in from the SRI call minutes: Discord
coinbase_only Mode and DeclareMiningJob
Optionality for DeclareMiningJob : Its usage depends on the mode.
Flag Renaming: The flag REQUIRES_ASYNC_JOB_MINING in
AllocateMiningJobToken.Success will be renamed to better reflect its purpose.
Dropping Synchronous Case: Only two modes will remain:
coinbase_only JD Mode: No DeclareMiningJob is sent.
I think there is a misunderstanding here. The pool is supposed to verify all the shares/jobs, the miners only a random subset. So this attack is not possible.
No, I understand that’s the intention of your proposal. I just don’t think verifying all jobs is realistic.
SRI doesn’t implement it yet, it only checks that all transactions are present. If the checks are incomplete there will always be some exploit. And if the checks are complete, it may be too easy to DoS the JDS.
You could send infinitely many block proposals to it that each take a long time validate. See Great Consensus Cleanup Revival
The blocks can be invalid, so it’s a free attack.
Fortunately there’s at least two mitigations for this attack:
Don’t validate anything until you have received some threshold worth of shares
Don’t allow non-standard transactions in the template
Simply checking if all transactions are in the JDS mempool is not enough. There might be an unknown transaction. Those are fetched via an sv2 message, but the transactions that obtained this way could all be slow to validate. And in order to check them, e.g. to make sure they’re not spending high value fake coins, you need to insert them into the JDS mempool. But maybe there’s conflict in the pool, so you have to evict some other transactions.
The best way to fully check if the proposed block is valid is by having the node verify it just like any other block, but without checking the PoW. There’s currently no RPC method to do this, e.g. submitblock requires proof-of-work. It may be useful to introduce such a method though.
I’m assuming that you can do it faster. At demand we rebuilt the mempool. Another assumption is that user are authenticated (otherwise there are other ways to DoS the pool), so I can at least detect who is building unusual block. For unknown txs we check if the tx is spendable and do not have conflict with other txs in the proposed block this is enough.
about solution (1) a pool can implement it outside of this proposal, for example the pool can send some work (so we are sure that work is valid) and activate the job declaration protocol and this extension only after that downstream sent some shares.
solution (2) is as well an implementation details, in this proposal we are not saying if pool can or can not deny some txs, and which should be denied.
Here’s a proof-of-concept implantation of a checkblock RPC for Bitcoin Core:
It can be used with block templates, which don’t have any proof-of-work. But it also has multiplier argument that can be used to raise the target for weak blocks, inspired by @instagibbs work in Second Look at Weak Blocks (though a different use case).
committing the share_index and also return it to the miner is a nightmare to implement right and efficiently. If the only reason to have it is to avoid the pool to lie about share indexes in slice (when challenged) we can remove it since the path is enough to know the index of a leaf and the pool already have to provide the path.