Since darknet-only nodes cannot use DNS seeds[1] to learn about addresses of Bitcoin nodes to connect to, I wanted to get a feel on how such nodes fare on hardcoded-seed data. To this end, I created some statistics on hardcoded seed nodes[2] to investigate how fast the number of reachable seeds decreases over time.
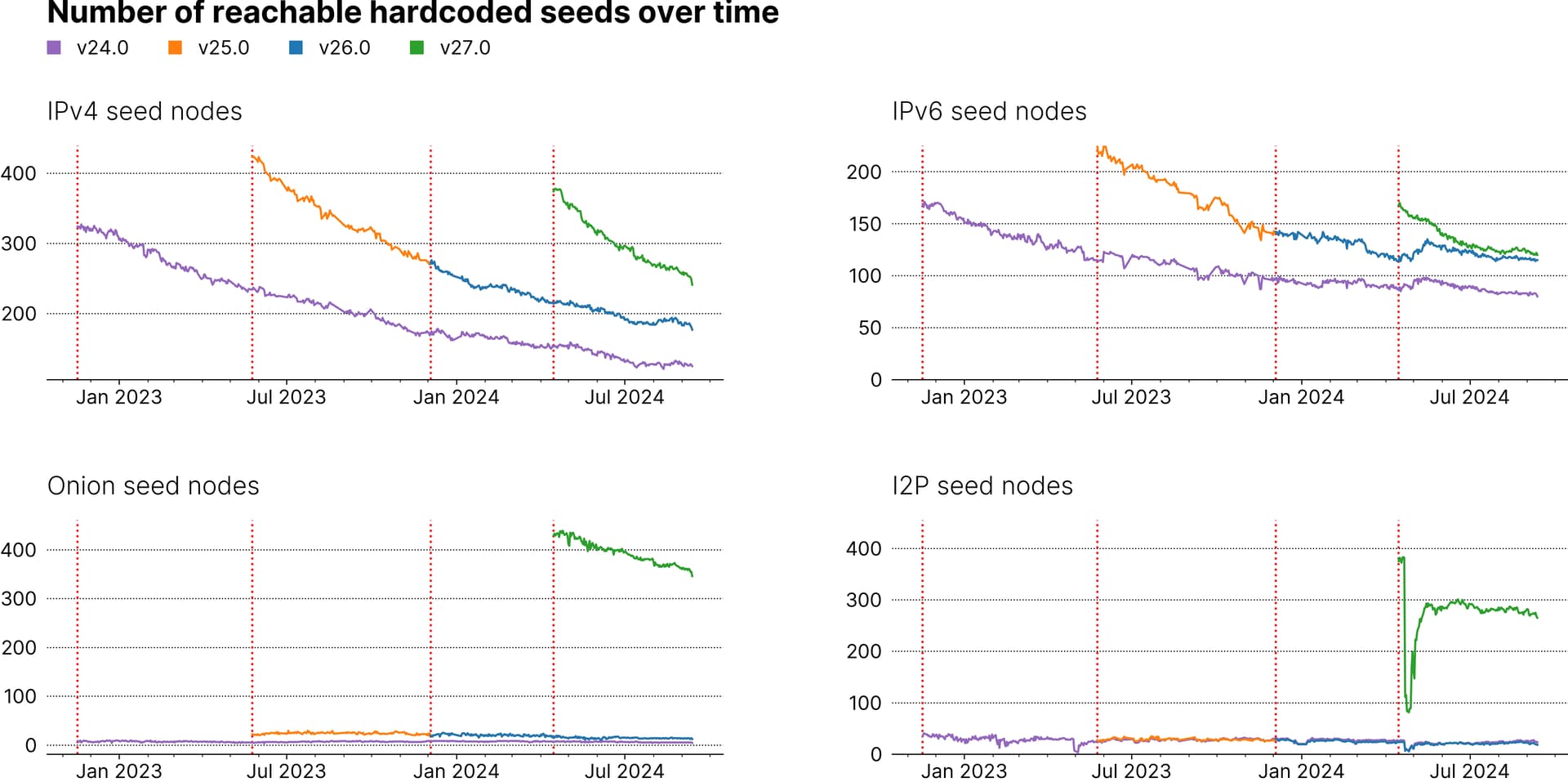
Each chart shows the number of reachable hardcoded seeds over time for a particular network type (I excluded Cjdns because I’ve only been collecting this data for a couple of weeks) and includes data for the last four Bitcoin Core releases (red lines correspond to release dates).
Some observations:
Despite IPv4 appearing to be the most “short-lived” network type, of the seed nodes hardcoded around 21 months ago into v24 still ~50 are reachable.
I2P nodes seem to be the most “long-lived” ones (the sharp drop shortly after v27 release in April 24 was due to a DoS attack on the I2P network).
It looks like there was an oversight during the v26 release to include new seed nodes.
Before v27, the number of Onion and I2P seed nodes was rather low (nodes for these networks were manually curated up until recently, and the number of nodes included depended on the data source).
To answer my original question about darknet-only nodes: they should be doing fine. Still I wondered, why they’re excluded from taking advantage of the DNS seed-mechanism, which has several advantages: for one, DNS seeds provide more up-to-date on reachable nodes, increasing the probability of quickly finding a reachable address; for another, they might improve privacy by advertising from a larger pool of nodes, thus reducing the likelihood of a hardcoded seed collecting statistics about bootstrapping nodes; etc.
In an old GitHub comment I read that darknet addresses are too large for seeding, it would be unnecessary and it’s not practical to access DNS over these networks. I’d like to address the first and last points with a PoC darknet seeder I wrote which is capable of serving Onion, I2P and Cjdns addresses using a BIP155-like encoding and is reachable via IPv4 and Cjdns (DNS/UDP) as well as Onion and I2P (DNS/TCP).
The point about necessity is one I don’t feel qualified to answer. If most people are running mixed clearnet-darknet nodes, there’s no necessity. For darknet-only nodes, it might be worth the effort (~100 loc to create custom DNS NULL queries in Bitcoin Core since right now we conveniently use getaddrinfo which does not require any low-level DNS functionality). Happy about feedback before taking this any further!
For those who don’t know, DNS seeds are used by a new Bitcoin node as the default way to learn about Bitcoin nodes it can connect to. The node sends a DNS query to one or more of the DNS seeds whose addresses are hardcoded into the binary, and receive a DNS reply containing a number of IPv4 and IPv6 addresses of nodes believed to be reachable. The node then connects to one or more of these addresses, sends a getaddr message to the node it connected to and (ideally) receives an addr reply from the node containing around 1000 addresses of other Bitcoin nodes. ↩︎
For those in need of a refresher, hardcoded seeds are used as a fallback when a new node who doesn’t know about any peers fails to solicit peer addresses via DNS seeds; for such instances, the Bitcoin Core binary contains a number of hardcoded addresses which the node can connect to and ask for other nodes’ addresses by sending a getaddr message. ↩︎
I think it should be the other way around. We should completely remove the dependency on DNS, and DNS seeds should be replaced with the IP addresses of nodes run by those developers. These nodes can respond to getaddr for bootstrapping.
As far as I know getaddrinfo will only return A and AAAA records.
I understand we don’t want to add some dependency library for this. But since we only need to send a particular query I don’t think that’s necessary. From what I learned writing the seeder, DNS is refreshingly straightforward. Here’s some C++ to send and receive a NULL query to demonstrate.
Concerning TXT records, I actually tried them first because I thought there might be an advantage to having “human-readable” data in the record. I used a base85 encoding to represent the 256-bit keys/hashes of Onion/Tor address. But using human-readable letters doesn’t make the data human interpretable, so I went with NULL records which are more efficient because they allow for binary data.
Good point about the lack of support for caching in the comment though. I’ll look into to. But given the 60-second TTL used by most DNS seeds, I highly doubt more than a handful of bootstrapping nodes ever used cached DNS data.
All else being equal, we’d certainly prefer not needing a dependency or ad-hoc DNS implementation to do DNS seed queries, but that on itself isn’t the main point here IMHO.
The reasons for wanting DNS-based seeding in the first place over more obvious alternatives (e.g., make a P2P connection to the seeder and send them a GETADDR request…) is the worldwide caching infrastructure and the ubiquitous access through ~every operating system for it. The caching makes it cheap to operate, and adds some notion of privacy: when you’re using your ISP’s recursive resolver, the DNS seed operator doesn’t see exactly what IPs are running Bitcoin nodes there, or exactly how many are present.
Not using the OS’s resolver and configuration means losing some of these advantages. A dependency or ad-hoc DNS resolver implementation means complexity to make it work on all supported platforms. Making such an approach find the system’s configured DNS server adds to that, or alternatively when sending the query directly to the seed, loses the caching/privacy benefits. So does switching to non-A/AAA records unless they’re reliably cached too.
In my view, if we’re going to be losing these advantages anyway, it’s simpler to switch to P2P-style seeding (already used when running on Tor, FWIW).
Although not exhaustive, I’ve looked at various public nameservers (Google, Control D, Quad9, OpenDNS Home, Cloudflare, AdGuard, CleanBrowsing, Alternate DNS), and they all seem to cache TXT and NULL records if the authoritative server’s answer matches certain criteria.
If the inclusion of a custom DNS lookup is a blocker though, I’ll not pursue the TXT/NULL record approach any further.
Something that just came to mind but I haven’t fully thought through: One could encode the data inside AAAA records (with a reserved prefix perhaps, to avoid confusing them with actual IPv6 addresses). In this case, the lookup in Bitcoin Core would remain unchanged (ie, getaddrinfo); there’d just have to be some extra decoding logic triggered by the reserved prefix.
This is interesting and I have never thought about it before.
Onion v3 and i2p addresses are 256 bits, while IPv6 addresses are 128 bits, so I’m not sure if encoding would help. However, it could be useful for sharing IP addresses with port numbers, for nodes using non-default ports.
Just implemented this to see if there might be any caveats.
The only con is the poor encoding efficiency of around 50%. NULL records can have an arbitrary length, so you’re paying the resource record overhead of ten bytes (2B for type, class and length each plus 4B for TTL) only once. With AAAA records, there’s ~12B of overhead (the ten-byte record overhead plus one or two bytes for a hardcoded restricted IPv6 prefix and the ordering information) for ~14B of payload.
On the upside, this approach works with getaddrinfo and does not interfere with server-side caching.
The demo implementation uses the ff00::/8 prefix to signal custom encoding and the next 8 bits for ordering (in theory, this could be reduced to just five bits, since you cannot fit more than 17 24-byte records into a 512B DNS message with a 12B header).
Note that regular IPv6 addresses are note affected: 2a02:4780:28:a4bb::1 and 2a01:4ff:1f0:8d5c::1 are regular AAAA records. Everything following that (ff00:..., ff01:..., ff02:...) is the new encoding. Overall, 11 AAAA records are required to encode two onion, two I2P and two CJDNS addresses.