Libbitcoin’s approach is very different from Bitcoin Core. This writeup intends to summarize how Libbitcoin functions for someone familiar with Bitcoin Core’s approach. This discusses the behaviour of upcoming, not yet released, version 4 of Libbitcoin.
Libbitcoin is event-based. It will kick-off multiple asynchronous tasks (it uses Boost ASIO). As you’ll see later it’s important as it enables it to take full advantage of its approach of splitting the various validation steps into checks which require strict, partial or no ordering.
Libbitcoin’s database is conceptually relational but the storage is abstracted out so different backends can be implemented. Conceptually the Libbitcoin node’s database has a table for headers, transactions, transaction inputs and transaction outputs. It maintains an index from confirmation height to header, header to transactions, transaction to header (only transactions confirmed in the best chain) and transaction output to its spending transaction.
To sync, Libbitcoin will spin up a hundred (by default) connections (more on how it handles connections later) and will redundantly request headers from all its peers. Once it gets a chain of headers which is “current”, as defined by being less than 1h older than the system time (by default), it will start querying blocks from its peers. Blocks queries are spread across all peers.
Libbitcoin breaks down block validation into steps which need partial ordering and those that require strict ordering. Some checks (for instance block size, or transaction nLockTime) don’t require any ordering. Checking scripts only require that you have seen the transactions that are being spent (partial ordering). Validating that the inputs actually exist requires that you went through all the blocks in order and checked the corresponding outputs were created and never spent (strict ordering). Libbitcoin will perform these checks, as well as the actual block downloading, concurrently.
When a block is downloaded, checks which don’t require ordering are performed and then the transactions are stored. Of course this is fine to do DoS-wise because it only considers transactions which are part of the chain with the most PoW. Concurrently the validation (see below for terminology) thread will perform for all new transactions the check which only require partial ordering. That is, all checks (including script) but whether inputs exist (and also relative timelocks, interestingly). The confirmability (see terminology below) thread will, still in parallel, check for a range of validated blocks whether all inputs spent by these transactions exist and are yet unspent. If they are it will for each transaction insert an entry in the transaction → header index, which conceptually “marks the block as confirmed”. So the steps are 1) download 2) validation 3) confirmability but those happen concurrently for different ranges of blocks.
Note that for blocks below the milestone (see below for terminology), Libbitcoin will skip validation and confirmability (see below for terminology) checks. Of course it will still check transactions were properly committed, i.e. no malleation of either transactions or witnesses. This is in my opinion a similar threat model to Bitcoin Core’s -assumevalid.
Reorg’ing is straightforward. To unconfirm a block the node just wipes the blocks’ transactions from the transaction → header index.
This means that pruning can technically be implemented by removing input and output data for historical spent outputs. In this case the node wouldn’t be able to reorg past the pruning point without requesting peers for missing transactions. However the store is at the moment append-only and supporting this is not a priority for the project as Eric does not consider pruning an important feature.
The transaction table is also used to persist unconfirmed transactions. They can occur by being announced by a peer or through a reorg. This is not implemented yet. When announced by a peer, the node would require a transaction has at a minimum feerate. For conflicts the node would require the transaction pays at least the minimum feerate for itself plus for the whole graph it conflicts with (i.e. all past conflicts and their descendants). In effect this requires the absolute fee paid to increase, pretty much like Core does.
Now peers/connections management. Libbitcoin will by default connect to a hundred outbound peers. They intend to make this number dynamic in the future (so it throttles back after IBD). When establishing a connection to a peer they try to establish 5 concurrently and only keep the one which finishes handshake first. For syncing headers they will redundantly request headers across all their connections. They do not monitor them for speed. Block requests are spread out across peers. The speed of responses to the block requests is monitored. Libbitcoin will compute a standard deviation across the set of download rate for each connection. Slow peers, as defined by a configurable negative deviation from the SD (default: 1.5x the SD), are dropped. Stalled peers are also dropped. DoS protection for requests made to the Libbitcoin node isn’t implemented yet, but Eric expects it’ll mainly consist of rate limiting requests.
Another important point when considering benchmarks between Core and Libbitcoin: it currently uses a 3 years old libsecp and does not have native SHA256 acceleration.
Terminology
Libbitcoin uses similar words for similar but different things as Bitcoin Core does. This intends to clarify the similarities and differences.
Milestone: equivalent to -assumevalid (but skips all checks, not only the script checks)
Checkpoint: equivalent to Core’s checkpoints
Validation: all verification (transactions scripts, amounts, timelocks, ..) except whether prevouts exist and are unspent
Confirmability: verification that transactions’ prevouts exist and are unspent
Candidate: most work chain which is not yet validated + confirmed
Transaction pool: equivalent to Core’s mempool but without the “mem” (it’s stored on disk)
Credits
Thanks to Eric Voskuil for patiently answering my questions and walking me through the inner working of Libbitcoin in more details. Obviously, all remaining mistakes are mine.
Thanks for this writeup! Sharing some thoughts below from private conversation.
For one, since there is no utxo set, prevouts are verified unspent by looking up the outpoint’s spending transaction and verifying that it does not exist. This to me would seem slower than looking up the prevout from a utxo set.
Based on insights from a private conversation, Libbitcoin will also skip checking confirmability if below the milestone. This means that transactions are written in order in the confirmability thread, but their inputs are assumed to exist and be yet unspent. Skipping this check is where the real speedup lies I believe, and was not clear to me on first read.
With that in mind, this approach seems more like a combination of assumevalid and assumeutxo, since the signature checks are skipped and the utxo set is assumed to be valid based on the block height.
Thanks for writing this! I found the bridging of the terminology particularly helpful. I was finding it difficult to conceptualise the Libbitcoin data model from your description, so I made an attempt at diagraming it, let me know if this is an accurate representation [1].
My understanding of Libbitcoin
erDiagram
Headers {
header_hash BYTES PK
}
ChainIndex {
block_height INT PK
header_hash BYTES FK
}
Transactions {
txid BYTES PK
header_hash BYTES FK
other_fields TEXT "Transaction data fields"
}
Outputs {
outpoint BYTES PK "txid + index"
txid BYTES FK
}
Inputs {
txid BYTES PK
index INT PK
outpoint BYTES FK "outpoint being spent"
}
ConfirmedTransactions {
txid BYTES PK
block_height INT FK
}
Headers ||--o{ Transactions : contains
ChainIndex ||--|| Headers : "best chain"
ChainIndex ||--o{ ConfirmedTransactions : "confirms at height"
Transactions ||--o{ Outputs : creates
Transactions ||--o{ Inputs : contains
Outputs ||--o{ Inputs : "spent by"
(also been awhile since I’ve written an ER diagram so likely contains mistakes ). To check my understanding against this data model (under the -assumevalid / milestone model):
Non-overlapping ranges of blocks (e.g., 1000 blocks at a time) are downloaded and and unordered checks are done in parallel across multiple ranges
The first range can also start confirmability checks (genesis to block 999), after which transactions from this range are committed to the Transactions table and the ConfirmationIndex is updated
Now that the first range has finished with it’s confirmability checks, the second range of blocks can start its confirmability checks, and so on
Conceptually, this seems close to a MapReduce algorithm, where unordered checks are mapped on to each range, and then the Reduce step requires sequential ordering of each range of blocks for the confirmability checks [2]. Clear separation between un-ordered and fully ordered checks is what makes this possible, from what I can tell. The partially ordered checks are not done under the -assumevalid / milestone model.
Before commenting on how this compares to Bitcoin Core, I want to say hats off to the Libbitcoin engineering team! If my understanding is correct, this is an elegantly designed event driven system, using MapReduce for data processing. My intuition is that the speedups are coming from the more aggressive peer utilisation during download, and the clear separation of unordered vs ordered checks to take advantage of parallelism.
Comparing to Bitcoin Core
While attempting to write the ER diagrams, it occurred to me Libbitcoin is using a Transaction based data model, as opposed to Core’s Block based data model. I know in other places this has been called a “UTXO set” data model, but it’s more helpful for me to think of it as Block based for this comparison. A few differences that jump out to me:
When a Libbitcoin node serves a block to a peer, it must reconstruct the block into its serialised representation, which will require some compute for each block request. Bitcoin Core, however, stores the blocks on disk in their serialised format and will simply read the block from disk and send it to the peer
When updating the chaintip, it seems Bitcoin Core will be faster at fully validating the new block (unordered, partially ordered, and fully ordered checks) and updating the chaintip, whereas Libbitcoin will be slower as most of its speed-ups rely on processing ranges of blocks under the milestone model
These are very high-level handwavey claims, and as its been mentioned already, Libbitcoin might be able to close this gap on fully validating new blocks after implementing libsecp / SHANI optimisations that are currently in Core. But I wanted to highlight the differences in data model because my intuition is a perfectly optimised Transaction based data model will always perform faster during IBD than a perfectly optimised Block based data model, and a perfectly optimised Block based data model will always perform faster than the Transaction model when it comes to processing new blocks and serving them to peers.
Closing thoughts
I don’t want to make claims (and hope I haven’t implied) in this post that one is better than the other. My personal view on the role of a Bitcoin node is that its primary purpose is to validate and propagate new blocks as quickly as possible, such that all nodes and miners on the network can quickly come to agreement on what the longest/heaviest PoW chain is. This is why I favour the Block based data model. However, it’s also clear that many other services / use cases need fast IBD and have more of a transaction based use case for bitcoin, namely any block explorer, wallet backend, payment processing, etc. It feels like there is likely some middleground between the Transaction based model and the Block based model that could serve both use cases.
I realise I’m mostly just rephrasing the original post in my own language. My hope is this is seen as useful and not a critique of the original post, which I found extremely helpful in understanding the differences between Core and Libbitcoin ↩︎
This is not quite MapReduce in that I don’t think classic MapReduce requires a strict sequential ordering, which the confirmability checks do. Still, I found it to be a helpful mental model for trying to better understand the Libbitcoin approach ↩︎
This also is not clear to me at all from this write up. Would be good to confirm this and perhaps amend the OP to reflect what Libbitcoin is actually doing.
Thanks for pointing out it’s worth underlining this in the writeup. Will edit OP.
I do also think this is what drives most of the IBD speedup there. And it is directly related to their architecture, doing it for Bitcoin Core wouldn’t bring much benefit since you still have to update the UTxO set (see also this #bitcoin-core-dev discussion discussion about this).
Yes although in the context of this specific benchmark it’s more about being able to skip a whole class of checks than parallelizing them, i think.
Even if they do, we can expect there still being an edge in using a UTxO set (as long as it doesn’t get enormous) as you check inputs against a much smaller index.
This isn’t so much block storage which makes a difference but how their content is indexed. In this case it would be clearer to make a distinction between a historical transactions index vs an unspent outputs index.
There are a few good observations here, but also several reasonable but incorrect assumptions. If anyone is interested in detailed discussion on libbitcoin’s node progress we invite you to join the libbitcoin Slack channel and/or attend our weekly dev meetings.
Awesome, thanks for the invite; just joined! In addition, if you’re able to respond here to which parts of my summary are incorrect, I think that would be of tremendous value. My intent in writing down my (likely incomplete) understanding was to give an opportunity for people to correct it here in the hopes of making this a more complete document on the differences between Libbitcoin and Core’s architectures. I’m also happy to try and translate my learnings from the slack channel back to this post, but it would be more efficient and correct to get it straight from the horses mouth.
I think this edit helps, but is still a bit confusing in that the term “transaction validation” is overloaded. Later in the post, you define “Validation” and “Confirmability” as two separate things, i.e., “Validation” is all verification checks except “Confirmability” and “Confirmability” is only verifying prevouts exist and are unspent. I think the OP would be more clear if it explicitly mentions that for blocks under the milestone, both “Validation” and “Confirmability” checks are skipped. I think this also makes it more clear where the differences with Core’s architecture are: while this is conceptually a similar threat model, Core does need to check that inputs exist and are unspent because this is necessary for maintaining a “UTXO set” (in that we must know what inputs are being spent so that they can be deleted from the UTXO set before continuing).
Has anyone (else) done this benchmark? A 15x performance difference, despite a native sha256 handicap, sounds too good to be true.
It’s also useful to investigate which machine properties (and settings) determine the difference. For example I have two machines than can do IBD in about 5 hours, in part thanks to a high -dbcache value and gigabit internet. Will libbitcoin do it in 20 minutes? (presumably not, if just because of disk speed limits)
But even a 3x difference on typical consumer hardware with typical internet bandwidth and only a few GB of RAM would be worth thoroughly investigating.
IIUC there’s only two things that Bitcoin Core does in parallel during IBD:
Block download
Script validation (I recently tried dropping the -par=16 limit, but -par=32 made no noticeable difference)
There certainly room to do more things in parallel, and it’s probably fine to spend a bit more CPU and I/O validating a chain that turns out to be invalid (but had the most PoW). Bitcoin Core currently tries to abort such validation as early as possible.
The benchmarks we’ve published are based on a 2.3Gbps (down, 40Mbps up, measured speed) Internet connection. It would not be possible to download to block 850k in 20 minutes in this case. The theoretical limit is around 40 minutes and we hit closer to 60. However with a 5 Gbps connection I suspect it would be close to 30 mins.
Disk speed isn’t the limiting factor, at least in these benchmarks. The store is append-only memory maps, so the only disk activity during IBD is periodic flushing to disk to free up more RAM. With sufficient RAM the disk is barely touched.
The Core parallel download is very limited, and really operates as just a read-ahead cache. Libbitcoin downloads, checks, stores, and indexes concurrently on all available (or configured) threads. The full chain can be concurrently downloading, though we generally narrow the window to 50k blocks or less to improve data locality and prevent extended gaps while validating. The store is fully write-concurrent and the overall design is lock-free (proactor pattern).
When fully validating, Libbitcoin also validates blocks concurrently on all available (or configured) threads - not just scripts, all accept/connect checks, and not limited to one block. A concurrent download window of about 50k blocks generally ensures that the validator threads are rarely starved.
On a low thread count machine this would be noticeable, but since CPU is not maxed out it is not a factor. We have noticed that this significantly affects Core, even though CPU is never close to max. This is an indication of how sequential is the operation.
FWIW we do have sse4 (4), avx2 (8), and avx512 (16 channel) Merkle tree and single/multiple block message scheduling vectorizations [though the benchmark hardware does not have avx512], are presently adding SHANI, and take advantage of several other SHA optimizations (e.g. cached whole block padding, function rewrites, vectorization-friendly array copies).
I’ll just add that Libbitcoin is doing a lot more useful work in this much shorter timeframe. We always index all transactions. Our Core benchmarks are with txindex disabled. We also always index all spenders - which input(s) spend a given output - which is a huge amount of information. All chain objects are stored relationally with full constant time bidirectional indexation.
We optionally can add the full Electrum style address index (e.g. ElectrumX) for an additional 30 minutes of sync time. It can take ElectrumX days to pull this same information out of a local Core node and index it in the same manner. Additionally the query response is orders of magnitude faster.
We’ve also noticed Core shutdown times of 10 minutes or more. BN shutdown time is generally less than a minute even after a full sync. We haven’t included that factor in our comparisons.
I’ll just note that when I was actively doing research into performance, there were a lot of architectural nudges that could unlock more perf in core’s architecture.
Comments above regarding where Libbitcoin achieves its performance advantage are not correct. The major performance advantage comes as a consequence of massive parallelism.
Milestone and assume valid are from a logical and security standpoint the exact same feature. Libbitcoin does not perform unnecessary checks under milestone. Core must build a utxo store even under assume valid, and this ordered building of the utxo set imposes strict ordering - preventing parallelism. It also operates as spend checks, but those unnecessary checks cannot be avoided due to the need to build the utxo set.
Regarding block serialization, it is true that Libbitcoin must compose outgoing blocks. However the store and composition are significantly faster than the network, and require very little CPU. Consequently response time is not impacted.
If one doubts this, consider that when downloading we deserialize a block off the wire, hash all txs (twice for segwits) and merkle hash (twice for segwits) perform block checks, and serialize the block to the store, with full indexation. When doing this on 64 threads concurrently (without shani) the store is still outpacing the 2.3Gbps network and completes in under an hour. Deserialization of blocks is not an issue.
Performance at the chain “tip” (we refer to “top”, since the linearizarion of the block tree is a stack) is a reasonable consideration. However this is really about compact blocks. Interestingly previous comments about block serialization work in reverse here.
Core stores whole confirmed blocks, so it must gather up all transactions from its memory pool, validate, and then serialize the block, and update the utxo store. This is an extra cost imposed by its data model, in a time-critical phase.
Libbitcoin does not have to construct or serialize a block, and does not have a utxo store to update. That alone gives it a large advantage.
But also, unconfirmed txs are validated and stored in the same table as block txs. So under compact blocks there is no need to validate or store any known txs. The block is constructed from unconfirmed tx metadata only, retained in memory. Validation of the block from this tx metadata is trivial. So this is likely to be significantly faster than Core, not despite the storage model, but because of it.
Finally, this data model effectively eliminates the “mempool” overflow issues with which Core continues to struggle.
Libbitcoin adds all block input points (actually references to points) to a hashmap while checking for existence on the emplace. Constant time per input. It’s done during block.check, so it’s coincident with download, which is fully concurrent.
I don’t understand why inputs are being fetched from a cache at all. Only one block at a time is being validated, and the block had to have just been parsed. Why not just enumerate the inputs and fire off the script validation jobs?
The block has been parsed, but we need to check whether all inputs are unspent. That cannot happen in parallel, since it depends on the order of transactions included in the block. The inputs of one transaction can spend outputs from a previous transaction included in the block. So, each transaction must lookup and remove each input’s prevout from the utxo set, failing if not found. Then each output must be inserted into the utxo set before the next transaction is checked.
These are two distinct block rules. (1) no forward references, (2) no double spends. Rule 1 is pointless, likely just an implementation artifact. Rule 2 is just a check for duplicate points within a block.
These are context free, they do not require a utxo store or any chain context. Rule 1 requires order, rule 2 does not. Libbitcoin splits these two rules and evaluates them independently. This allows the second to be evaluated using concurrency.
However, concurrency for such a fast algorithm with a bounded set size proved counterproductive - especially since it is part of block.check and is therefore evaluated concurrently across blocks.
Given the need to populate and depopulate a utxo store, these checks become tied to it. However you are referring to lookup of previous outputs, not inputs. I was asking why there is an input fetch.
I think you mean output (previous output of the input) here as well. If the prevout doesn’t exist then the input script will fail to validate. That’s just a query for the output during block.connect, which requires no order and is performed concurrently across blocks.
In other words, there are other checks: (1) no forward reference, (2) no [internal] double spend, (3) prevout exists and executes successfully. There is also (4) prevout is in the current or previously-confirmed block, (5) prevout is not spent in any previously-confirmed block [not double spent in current block is #2).
I don’t see how this requires no order though. If the transaction which contains the prevout has not been stored yet then this check will fail even if it does exist.
It only requires that the previous output has been downloaded. That’s a partial ordering requirement. That’s why #3 cannot be performed in block.check.
The important observation is that it does not require a total ordering by block. That constraint is only imposed by the need to populate a utxo store.
I should clarify that rules 4 and 5 (as described above) do require a total ordering by block. It’s just that validating scripts (input->output) does not, that’s a partial ordering (3). And the forward reference (1) and internal double spend (2) checks impose no ordering requirement.
The trick to obtaining maximal concurrency is factoring necessary constraints such that no unnecessary order is imposed.
Existence and spentness are all about block order, we call that “confirmability” and perform these checks in a “confirmation” phase. Checks such as script execution, and the related prevout queries, run concurrently across blocks in the “validation” phase. Anything that is block-context free (header context is always available) is performed in the “download” phase. The three phases run concurrently.
Yes, and I believe any check that requires total or partial order is skipped if below the milestone block. This is what allows a sync in an hour. So, I think it’s still accurate to say that not looking up input prevouts is where the main speedup is.
Looking at a flamegraph of Bitcoin Core IBD, the majority of time is spent looking up input prevouts. That’s why parallelizing that provides a nice speedup. Skipping it entirely though is not possible since we would not have a utxo set at the end, which is not a constraint that libbitcoin has.
I think a weaker equivalent of the partial-ordering idea can be implemented in an “explicit UTXO set” model, though only prior to the assumevalid point (or anywhere it’s known that script validation won’t happen).
If an input is encountered which doesn’t exist in the UTXO set, instead add a “negative UTXO” entry, reflecting the spend, but not the creation. When the UTXO is later added, they cancel out. If negative UTXOs remain at the end, the chain is invalid (but it would require proper care to assign these failures to the spending, not the creation). This would pretty much allow processing blocks in any order.
When script validation is enabled, this isn’t possible because the state required to run script validation is pretty much the entire spending transaction, not just a small piece of UTXO data.
The previous discussion is about full validation. Libbitcoin validates blocks (prevout lookup an script execution) concurrently, which is a significant performance advantage. However, in milestone runs there is no need to look up prevouts.
You might believe that it’s the lack of this lookup that saves the time, but it’s not. It’s the lack of a utxo store imposing a total order on block commitment. This allows us to download, check, store and index blocks concurrently across the entire chain.
I’m not sure I follow this explanation, but the conclusion is correct. The approach wouldn’t work under a candidate header branch above the milestone (assume valid block) because blocks above the block being validated are updating prevout existence and spentness. So existence in the utxo store no longer represents order. Under milestone, validity of the branch is assumed so this doesn’t matter, the objective is just to populate the utxo store up to the milestone.
A material cost of this approach (under milestone) is that the utxo store must not only be thread safe, but locks must persist across each output being searched, compared and written. Given that there are billions of outputs this is a non-trivial consideration.
Ultimately this can be resolved by just downloading the full utxo set under assumption as well, which is already implemented.
I’ve been trying to find a good way to show this with data. I think that our construction of the ElecrumX address index table along with our point compression is a pretty good proxy (both are optional). These are not ordered but in combination impose the same number and type of table reads/writes as a utxo store population would under assume valid.
The address index requires the mapping of the sha256 hash of every output to the surrogate key of the output. This is comparable to the write of the output to the utxo store (the surrogate key allows direct recovery of the corresponding output, with navigation to its spending input).
We don’t do deletes, but the spend of the output can be approximated by the search of each input in the point hash table, and write of an entry to that table in the case that it’s missing. This optional search compresses out redundant point hashes, saving about 50GB (making the fully-indexed store materially smaller than the Core store).
Point compression is neutral on total sync time, because the resulting table is so much smaller (similar to the reduction caused by removing spent outputs in a utxo table). The address index adds about 30 minutes to a 1 hour sync. This is on a machine that takes Core 15 hours to sync under assume valid.
I think this makes the case as closely as possible that lack of utxo store population (reads/writes) is not what powers milestone sync, it’s the lack of imposition of total block ordering by a utxo store.
However, one might also consider the extraordinary amount of non-optional indexing. BN always indexes all transactions by hash, all confirmed txs to their containing block, all outputs to their spending input(s), all inputs to their point hash (optionally compressible), all headers by hash, and all headers to their associated txs (if associated). Each of these is a hash table.
I think you can do the same optimisation even in that case, if you augment the spending block with its corresponding revNNN.dat data. You can’t authenticate the revNNN.dat, so still need to track negative entries, and in addition also need to check that the rev data was correct (compare it to the utxo when you find a match), and need to be able handle falling back to in-order processing (in case you’re given bad rev data which says a tx is invalid, you need to recheck when you get the actual utxo data, if it’s different).
(I was thinking of that technique in the context of taking an assumeutxo set and validating the chain both forwards and backwards simultaneously, to avoid the need to maintaining two utxo sets, provided you didn’t care about optimising for the case where the assumeutxo point was actually invalid)
Sure, but that’s cumulative to sync time. It’s not really a fix it just amortizes the cost.
Flush to disk and destruct of an object model is far more costly than flush from mmap. Not only is mmap flush simple but it is paged in the background. Even with 32GB of RAM fully loaded during/after a full sync (with no explicit/periodic flush during sync), flushing the RAM takes around 10 seconds at shutdown.
If not already implemented, it might help Core’s flush time to use a custom linear memory allocator. That effectively eliminates the destruct cost. This can be very high if the objects are passed between threads (another consideration if the cache was to become threadsafe).
The theoretical limit to download 850k blocks (582,391,632,423 bytes) over 2.3 Gbps Internet is 34 minutes. After integrating shani we are now achieving 40 minutes (plus up to a minute for store build, startup, header sync, and full shutdown) on the $350 benchmark machine.
The remaining 6 minutes is largely a consequence of mmap flushing and remapping the mmap as the files grow. A higher memory machine would eliminate most of that. Also hashing will be further reduced with an avx512 box, which I just ordered for our test bench ($421).
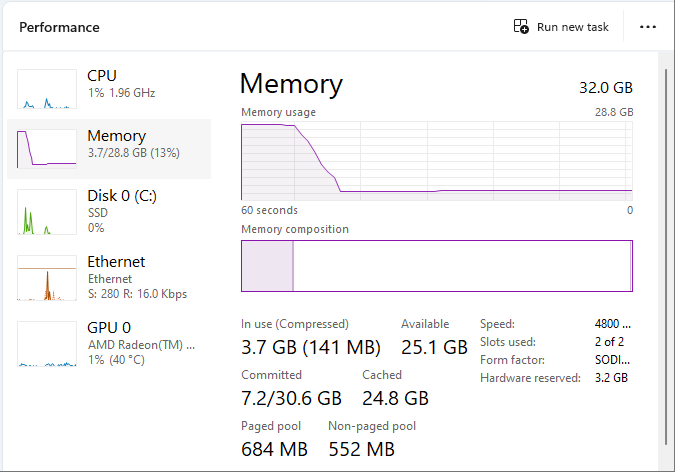
@sjors by the way I went out and bought the exact hardware @evoskuil used for his Windows benchmark (PELADN HA-4, 1TB SSD / 32GB RAM), and I have performed the same benchmark using a slightly newer version of bn.exe .
The sync took 7605 seconds, which is about 127 minutes or 2.11 hours.
My sync was slower than @evoskuil’s because my internet connection is about 800Mbps vs Eric’s >2Gbps.
So libbitcoin does indeed seem to sync very quickly. I should probably do a bitcoin core sync on the same box to set the baseline.
For the record, the hardware cost US$530 for me because of import duties, but 2 hours on a US$530 machine is still an amazing result IMO.