A few weeks ago @RubenSomsen proposed to speed up the IBD phase in Bitcoin Core by
reducing the chainstate operations with the aid of pre-generated hints. Right now, the main optimization
is to skip script verification up to the -assumevalid block (enabled by default, updated on each release), but all other block validation checks
are still active. In particular, UTXO set lookups and removals can be quite expensive and cause regular coins cache and expensive leveldb disk I/O operations.
The idea is to only ever add coins to the UTXO set if we know that they will still be
unspent at a certain block height N. All the other coins we don’t have to add or remove during IBD in the first place,
since we already know that they end up being spent on the way. The historical hints data consists of one boolean flag
for each transaction output ever created (up to including block N), signalling the answer to the question:
“Is this transaction output ending up in the UTXO set at block N?”.
If the answer is yes, we obviously add it (as we would also normally do), but if the answer is no,
we ignore it. Consequently, we don’t have to do any UTXO set lookups and removals during the IBD phase
anymore; the UTXO set only grows, and the order in which blocks are validated doesn’t matter anymore,
i.e. the block validation could be done in parallel. The obvious way to store the hints data is bit-encoded, leading to a rough
size of (number_of_outputs_created / 8) bytes, being in the hundreds of mega-bytes area for mainnet (e.g. ~348 MiB for block 850900).
As a rough overview, the following checks in ConnectBlock are done in each mode:
validation step
regular operation
assumevalid
IBD Booster
Consensus::CheckTxInputs
BIP68 lock checks
SigOp limit checks
input script checks
update UTXO set
grow-only, with MuHash check (see below)
block reward check
To give some assurance that the given hints data is correct, the state of the spent coins is tracked
in a MuHash instance, where elements can be add and deleted in any order. If we encounter a transaction
output where our hints data says “false” (meaning, it doesn’t end up in the final UTXO set at block N
and will be spent on the way there), we add its outpoint (txid+vout serialization) to the MuHash.
For any spend in a transaction, we then remove its outpoint (again txid+vout serialization)
from the MuHash. After block N, we can verify that indeed all the coins we didn’t add to the UTXO have been spent (implying that the given hints data was correct) by verifying that the MuHash represents
an empty set at this point (internally that can be checked by comparing that the numerator and denominator have the same value).
I’ve implemented a proof-of-concept of this proposal and called it “IBD Booster”, consisting of two parts:
A Bitcoin Core branch which supports reading in the hints file and use it for the optimization as described above with a -ibdboosterfile parameter: GitHub - theStack/bitcoin at ibd_booster_v0
Fetch the IBD Booster branch (contains the booster hints generation script in ./contrib)
$ git clone -b ibd_booster_v0 https://github.com/theStack/bitcoin
$ cd bitcoin
Create IBD Booster file containing hints bitmap
(first start might take a while as the py-bitcoinkernel dependency has to be built in the background first [1])
On a rented large-storage, low-performance VPS I observed a ~2,24x speed up (40h 54min vs. 18h 14min) for running on mainnet with `-reindex-chainstate` (up to block 850900 [2]):
$ time ./build/bin/bitcoind -datadir=./datadir -reindex-chainstate -server=0 -stopatheight=850901
real 2454m37.039s
user 9660m20.123s
sys 380m30.070s
$ time ./build/bin/bitcoind -datadir=./datadir -reindex-chainstate -server=0 -stopatheight=850901 -ibdboosterfile=./booster850900.bin
real 1094m31.100s
user 1132m53.000s
sys 46m45.212s
One major drawback of this proposal is that we can’t create undo data (the rev*.dat files) anymore, as we obviously don’t have the prevout
information available in the UTXO set during the IBD booster phase. So the node we end up is unfortunately limited in functionality, as some indexes (e.g.
coinstatsindex and blockfilterindex) and RPC calls (e.g. getblock for higher verbosity that shows prevout data) rely on these files for
creating/delivering the full data.
My hope is that this proof-of-concept still serves as a nice starting point for further research of simliar ideas, or maybe is useful
for projects like benchcoin.
Potential improvements:
investigate further speedups (e.g we don’t really need the full coin cache functionality up to the target block)
don’t load all hints data into RAM at once
refine file format to include metadata and magic bytes for easy detection
research about potential compression of the hints data (probably not worth the complexity imho, but an interesting topic for sure)
implement parallel block validation
investigate including the coin heights in the hints data to enable more checks (leads to significantly larger hints data though)
hints generation tool speedups?
…
Thanks go to @RubenSomsen, @davidgumberg, @fjahr and @l0rinc (sorry if I forgot anyone) for discussing this idea more intensely a few weeks ago, and to @stickies-v for providing the great py-bitcoinkernel project (I was considering to use rust-bitcoinkernel instead for performance reasons, but my knowledge of Rust is unfortunately still too bad).
Suggestions and feedback in any form, or more diverse benchmark results (or suggestions on how to benchmark this best) would be highly appreciated.
Cheers,
Sebastian
[1] Note that I only tried to run the script with uv so far, since it just worked flawlessly from the start without any headaches. Using other Python package management tools might also work to build and run this script, but I haven’t tested them.
[2] Block 850900 is way in the past of the current assumevalid block, but I had to stop there as I ran out of space on the benchmark machine.
Nice work! Really great to see such a large speedup already on the initial benchmark, especially considering this is without parallel block validation. Btw I now call this “SwiftSync” and I’ve been working on a full write-up. I’ll send you the unpublished draft, but I already published an initial overview here (along with the coredev session notes). I also gave a presentation on it at the recent Amsterdam bitdevs. Slides are here, though I’m not sure how clear they’ll be without context.
Without going too much into detail (I’ll leave that for the write-up), here are two important points:
First, assumevalid is not actually a prerequisite (though it does make for an easier first PoC). Perhaps that was my fault for emphasizing it too much - you weren’t the only one who got that impression. When processing the output you can add all the UTXO set data into the hash instead of just the outpoint. On the input side you’d then have to re-download the UTXOs that are being spent in each block (essentially the undo data, though we should encode it a bit more efficiently… maybe 10% more data) in order to remove it again. This allows you to do full validation without assumevalid (a few more steps are actually needed, but you’ll see the details in the draft).
Second, MuHash is not strictly required. We can use a regular hash function like sha256 and do modular arithmetic, provided we add a salt to prevent birthday attacks. So it’d be hash(utxo_data_A||salt) + hash(utxo_data_B||salt) - hash(utxo_data_C||salt) - hash(utxo_data_D||salt) == 0 (thus proving (A==C && B==D) || (A==D && B==C)). This should be faster than MuHash.
And one point of lesser importance, but it’s simple to implement so why not: you can encode the bit hints as the number of 0’s before each 1. So 00010000011001 would be encoded as 3,5,0,2. There is more you can do, but this should already save a ton of space.
I’ve looked at the current hints data format to think about how to best compress it, and I’ve spotted a flaw. It seems you’re storing the output count of each block as a 2-byte sequence, but that only goes up to 65,535. This is more than the current mainnet maximum of 26,908 outputs in a block, but since the smallest possible output only takes up 9 bytes, the theoretical maximum is well over 65,535 (demonstrated e.g. by this 100 kB transaction with 10,002 outputs).
This could be fixed by using a variable-length encoding for the output count, but do you even need it at all? The order of outputs as they are created is defined just as well without splitting them into blocks. (Also you’d avoid having to pad between blocks for a modest 0.4375 bytes saved per block on average, on top of the savings from removing the output counts.)
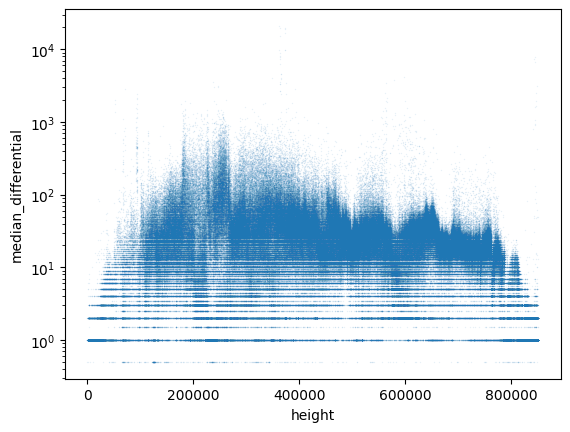
I remember thinking about this when first hearing about IBD booster / SwiftSync and just had a quick and dirty look at using delta / differential encoding together with CompactSize and VarInt’s in this notebook. This seems to half the size of the uncompressed data. Though, as the hints will likely be distributed compressed and the xz compressed data is about the same size for all combinations, I’m not sure if it’s worth to differentially encode it.
filename
size (bytes)
booster850900.bin
364964716
differential_compact_size.bin
188209875
differential_varint.bin
190098381
booster850900.bin.xz
87882052
differential_compact_size.bin.xz
81697540
differential_varint.bin.xz
81321492
Note that most of the median deltas are below 253 and encodable with a 1 byte CompactSize:
I don’t mean to be discouraging, but isn’t this more or less what we spent a bunch of time on assumeutxo to accomplish?
IBD booster requires (as far as I can tell) essentially trusted metadata – the hints – that were produced using some other, already synced node. It also requires modifications to very sensitive parts of the validation code in order to make use of the hints.
Assumeutxo snapshots, on the other hand, aren’t trusted in the same way that hints seem to be given that the snapshots are committed to with hashes in the source code.
IBD booster provides a ~2.24x speedup – which again is very cool – but assumeutxo provides a higher order of speedup (sync in an hour or two) given that we’re truncating the IBD process to the history between the snapshot base and the current network tip.
This is very interesting research, and I don’t mean to discourage. But I’m just wondering if it isn’t worth instead investing more effort to “deliver” assumeutxo in terms of making it usable with the GUI etc. rather than inventing and implementing yet another way to produce exogenous metadata, distribute it safely, and use it to speed up IBD.
Assumeutxo snapshots, on the other hand, aren’t trusted in the same way that hints seem to be given that the snapshots are committed to with hashes in the source code.
The exact same can apply to the hints - they could equally be committed in the source code.
Also note that unlike assumvalid/assumeutxo the hints cannot affect consensus since validation will fail if the hints aren’t correct rather than ending up on the wrong chain. This makes it much more conceivable to get them from a trusted third party and use them to validate all the way up to the tip (the worst they can do is waste your time).
isn’t this more or less what we spent a bunch of time on assumeutxo to accomplish
It’s actually completely orthogonal.
Today your options are to start with assumeutxo or not, and then to either use assumevalid or not for (background) validation. SwiftSync speeds up the latter, regardless of whether you utilize assumeutxo or not.
In fact, assumeutxo and SwiftSync synergize quite nicely in some ways. SwiftSync makes background validation near-stateless, meaning you wouldn’t have to manage two full chainstates when you’re simultaneously validating at the tip. And if you use SwiftSync (specifically the non-assumevalid version) with assumeutxo then you don’t even need the hints anymore. You can just add every output (spent or unspent) to the hash aggregate and subtract the UTXO set from it (i.e. all outputs - inputs - UTXO set == 0).
Thanks for the update and the resources, that all sounds very promising! I’ll focus on the assumevalid version with my reply for now, since I still haven’t fully processed the non-assumevalid one yet.
Nice idea! As already noted in private, I’m wondering though if only adding a salt is really enough to provide the same security guarantees as MuHash would do? Reducing the modulo field size from 3072 bits to 256 bits and using simple addition instead multiplication as basic operation seem to be quite drastic cuts. This is more “gut-feeling” and far away from a mathematical sound argument, but it feels to me that this was too good to be true if there aren’t any significant downsides to this approach. (That said, I hope I’m wrong, and even if there is a reduction in security, it’s maybe still good enough for the SwiftSync use-case, since the goals of MuHash and the aggregate hash here are different.)
The results are pleasant, with this I’m now already observing a ~5x IBD speed-up compared to the assumevalid run (again, up to block 850900, and using -reindex-chainstate), and this is still without any parallel block validation involved:
assumevalid only
SwiftSync (MuHash for aggregate hash)
SwiftSync (salted sha256 add/sub for aggregate hash)
time
2454m37.039s
1094m31.100s
464m37.234s
speed-up
-
~2.24x
~5.28x
Doing parallel block validation as next proof-of-concept step would be very nice, but that needs of course much more invasive changes in the codebase.
A key trade-off is that a salt must be kept private for security of the node if hashes are being used
Obviously the salt should not be publicly exposed, but are you sure it needs to be secret? If the hints file commits to the chaintip at the end of SwiftSync and the user has a copy of (or commitment to) the hints file when they choose their salt, how can an attacker use knowledge of the salt to create a TXO that negates a previously accumulated TXO? The chaintip commits to all of the past txids, so they can’t be changed (or we have bigger problems!). The node also won’t be using SwiftSync after IBD, so the attacker can’t create new TXOs based on learning the salt. I think that means that even an attacker who knows the salt can’t do anything with it.
The exception would be if you started SwiftSync with one hints file and then switched to another (e.g., you upgraded node versions in the middle of IBD). However, that must be forbidden anyway since a TXO that was previously hinted to be a UTXO might now be a STXO.
It contains more details about the hash aggregate, and answers the following questions (and more):
How exactly assumevalid is utilized and what the implications are
How we can still check for inflation when we skip the amounts with
assumevalid
How we can validate transaction order while doing everything in parallel
How we can perform the BIP30 duplicate output check without the UTXO set
How this all relates to assumeutxo
To my knowledge, every validation check involving the UTXO set is covered,
but I’d be curious to hear if anything was overlooked or if you spot any
other issues.
I love this idea (needed a few iterations with Ruben to understand how it changes the guarantees); it’s a much-needed alternative for something between full IBD and AssumeUTXO.
@theStack created an excellent prototype that makes it easy to check it out and experiment further.
I usually test my IBDs using hyperfine for precision, either an i9 processor with an NVMe SSD (or an i7 with an HDD, not used here).
I have separated the addition of ibdboosterfile/swiftsyncfile argument to be the very first commit so that I can run both before/after versions with the exact same arguments (in the first instance the value is ignored; it’s basically master branch with an unused arg).
I have measured a -reindex-chainstate instead of a full IBD to reduce unrelated networking fluctuations.
I have first tried it with the provided 850900 block hints with MuHash for -dbcache=4500 (since we’re not testing flushing behavior, so let’s use plenty of memory).
As mentioned before, it seems like the MuHash version is surprisingly slow, it’s actually 2x slower than master:
Luckily @theStack provided an alternative which just uses SHA-256 to keep track of spentness via HashWriter.
I have tested this version as well by first generating the hints until block 888888 for good luck🍀 and gave it more cowbell (45 GB in-memory cache to have a single flush at the end to reduce noise).
This is indeed 56% faster for me, resulting in a 2h:47m reindex-chainstate - sweet, I could get used to that.
2025-04-30T06:44:15Z *** SwiftSync: aggregate hash check at terminal block height 888888 succeeded. ***
2025-04-30T06:44:15Z UpdateTip: new best=00000000000000000001347938c263a968987bf444eb9596ab0597f721e4e9e8 height=888888 version=0x24bc4000 log2_work=95.509247 tx=1169009164 date='2025-03-22T09:15:51Z' progress=0.986891 cache=25442.8MiB(173676464txo)
...
2025-04-30T06:44:15Z [warning] Flushing large (24 GiB) UTXO set to disk, it may take several minutes
2025-04-30T06:56:52Z Shutdown: done
EDIT 1:
Running it on a HDD with a slower i7 processor and a lot lower dbcache reveals a lot bigger speedup of 282% (or rather a lot bigger slowdown of master):
SHA-256 benchmark details with 450 MB dbcache on an i7 with HDD
I have a few ideas and questions about the implementation (some might be a bit undercooked for now):
Further Optimizations
Do we really need a cryptographic hash here, or can we use a “pretty-good” hash instead? I’d like to better understand the requirements for salting, especially if we’re storing the hint hashes as well.
Could we use a native 64/128-bit aggregator instead of a 256-bit one? Especially if we can split one big aggregator to one-per-thread, which we’d combine at the very end to check for validity (fork-join)… Given a 256-bit hash for the hints and AssumeUTXO heights, can we make this “less secure”?
Memory/Disk Handling
Since we don’t need to read or remove from the UTXO set anymore, we could use a concurrent queue/ring-buffer instead of the dbcache and write continuously to disk via a background thread (avoiding the expensive final flush). Or maybe just directly write to LevelDB with bigger in-memory cache.
We could investigate what it would take to add undos on a background thread during swift-syncing (e.g. while the main thread connects the next block).
Would this enable ultra-low-memory IBD (e.g., 100MiB, assuming gradual hint loading)?
Validation and Security
We should definitely validate that total amounts at the current tip don’t exceed expected mined values (just noticed you mention this in the latest version of the writeup as well). While assumevalid skips script validation (doesn’t really concern me), I find skipping amount validation more concerning (potential inflation bugs).
We need more negative tests for various invalid scenarios (invalid hints, different tricky double-spends, etc.).
Validate current state against hard-coded AssumeUTXO heights to fail early if inconsistencies are found. We could also add the utxo-hint-hashes there as well to be able to request the hints from any node safely.
Do we need to validate whether any of the outpoints accidentally hash to the same value?
Performance
How would this combine with other pending IBD optimizations (batched block reading/writing, obfuscation speedup, faster UTXO batch writing, etc.)?
What are the next bottlenecks after removing the obvious ones (since this removed the most obvious ones, which eclipsed all other ones)?
How many blocks have outputs that were either all spent or all unspent until a given height? Could we optimize the hints for these cases? Can we optimize the storage compressibility (e.g. sorting by similar block spends)?
Usage Extensions
Could SwiftSync work for very low-performance devices (e.g. smartwatch) even after IBD (reorgs)?
Should we keep updating the hints after IBD to speed up RPC calls (maybe gettxout, gettxoutsetinfo, scantxoutset, listunspent, etc)?
Initially introduce this for reindex(-chainstate) only, since we’ve already validated the chain.
Nice work. Makes sense to me that the speedup is less apparent when RAM isn’t limited. Nice to see it’s still quite significant.
can we use a “pretty-good” hash […] Could we use a native 64/128-bit aggregator
You could consider running a benchmark with a theoretical 0-cost hash aggregate function (i.e. simply don’t hash or aggregate anything) to see what the maximum possible savings are. In terms of security, I believe it boils down to the chance of a single accidental collision, so a 4 byte hash would only have a one in 4 billion chance of incorrectly accepting an invalid chain. Not unreasonable, but the default should probably be at least 16 bytes, just to be able to say there’s no reduction in security.
Validate current state against hard-coded AssumeUTXO heights to fail early if inconsistencies are found
Not fully sure I understood correctly, but if the assumeutxo hash and hints come from the same source, then I don’t think failing early helps.
Do we need to validate whether any of the outpoints accidentally hash to the same value?
I wouldn’t be concerned here about accidental hash collisions, as that’s not happening with 32 bytes and a salt.
What are the next bottlenecks
Batch validation of Schnorr signatures is an interesting one to reduce CPU load (for the non-assumevalid version).
I’ll try to parallelize this in the following weeks
Use xor as the aggregator. The low characteristic field is less secure for a subset sum attack, but since the attacker doesn’t know the salt they can’t make any meaningful progress anyways. The important property from the hash is its collision resistance with an unknown salt.
To be the most tidy and paranoid the user’s seed should be a secret function of the blockhash at the AV height (or whatever height the hints are at, if it’s not the AV height.). The system must not leak any collision information along the way, so no checking for collisions! (which would be slow regardless) It should sync all the way to AV height, and then only if all the chain data it received actually matched AV height should it check the accumulator, don’t check the other way around. If the system is rerun on the same blockhash it should use the same seed. If the system tries to sync with a different AV blockhash it should use a different seed. The point is that an attacker should only get one try per node. (doing the exact same chain over again isn’t another try so long as the seed stays the same). So I would suggest that you have some per node random number (maybe there is one saved with the address database already? I forget) and just hash that with the AV blockhash to get your seed.
This kind of paranoia isn’t necessary for sha256, but I think it’s free to design it that way and would make it safer if deployed with a weaker hash function.
The requirements here are extraordinarily low because an attacker also has to do chainwork to get the user to adopt a tampered chain… but I think using a weaker non-cryptographic hash function would not be a good use of development time right now. With this in place the bottlenecks have to move to things like network, block serialization, validation parallelism overheads… Development time would be better spent on optimizing those than producing confidence that a non-cryptographic hash is sufficient. Also hardware with SHA-NI sha256 will be competitive-ish in performance with ‘fast’ hash functions.
It’s basically free so it should do that for sure. That said, there are so many lost/abandoned coins that if miners (with developer collusion) create a chain that unjustly rewards them, they’ll just steal coins rather than inflate.
There are probably a number of tests that are still free to perform that might be getting skipped in your changes without some refactoring, probably worth going and rescuing them. Like nLocktime can be checked against the block height, sadly CSV can’t be tested.
There is still a significant portion of validation past the AV point, like six months to a year of chain. So even with AV signature validation is in important part of IBD esp if the AV part is made much faster. Keeping that part fast is also good for avoiding any pressure to set AV closer to the tip.
Makes sense. I have even been wondering if using that block hash as a salt is enough, given that it is essentially a commitment to the two sets (inputs and spent outputs) you’re comparing against each other, but that’s difficult to reason through.
All good points.
Agree.
Right, optimization beyond the AV point is certainly important as well. In theory SwiftSync could also help you sync beyond the AV point if you accept hints from a third party. The worst they could do is waste your time.
I am working on a Rust-based binary that performs SwiftSync here. We made a couple of patches to the libbitcoinkernel library to do this. From the client perspective, ProcessNewBlockHeaders to pre-sync block headers and manage the chain state. To build the hintfile, I also require HaveCoin on the ChainStateManager.
The IBD binary works as follows: 1. read a hintfile into memory and parse the agreed upon stop-hash 2. query DNS for reachable nodes 3. connect to a peer and sync block headers to that stop hash 4. spawn N threads to continually request batches of blocks 5. update an accumulator if the output is not contained in the UTXO set (given by the hint file) 6. return true/false if the accumulator state is zero once all blocks have been downloaded.
The times to sync have been promising when testing on my computer(s). I encourage people to try it out and give feedback!
Of note, I am working on a patch to divide block hashes into a “work-stealing” style, which should improve sync times in the coming days.