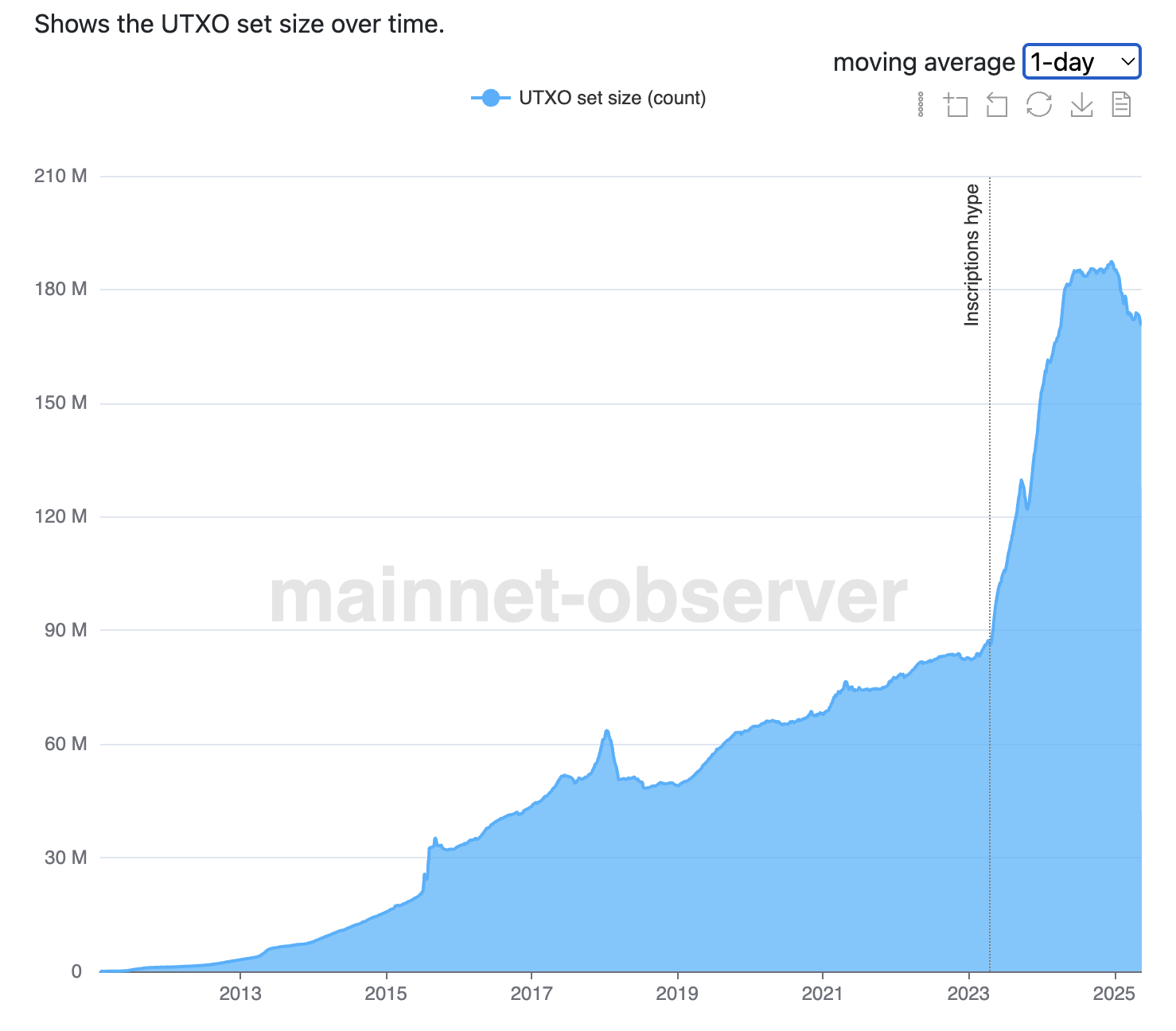
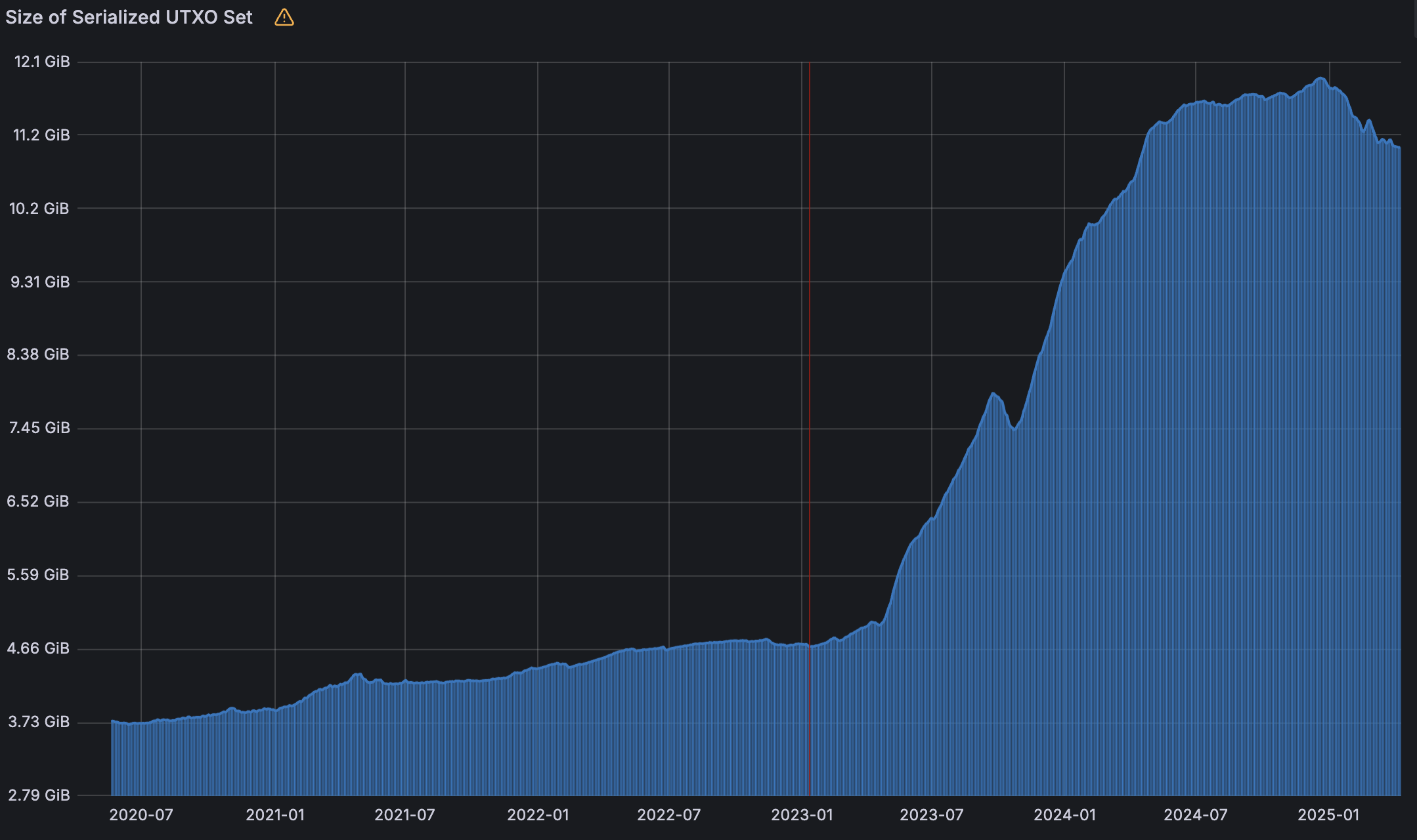
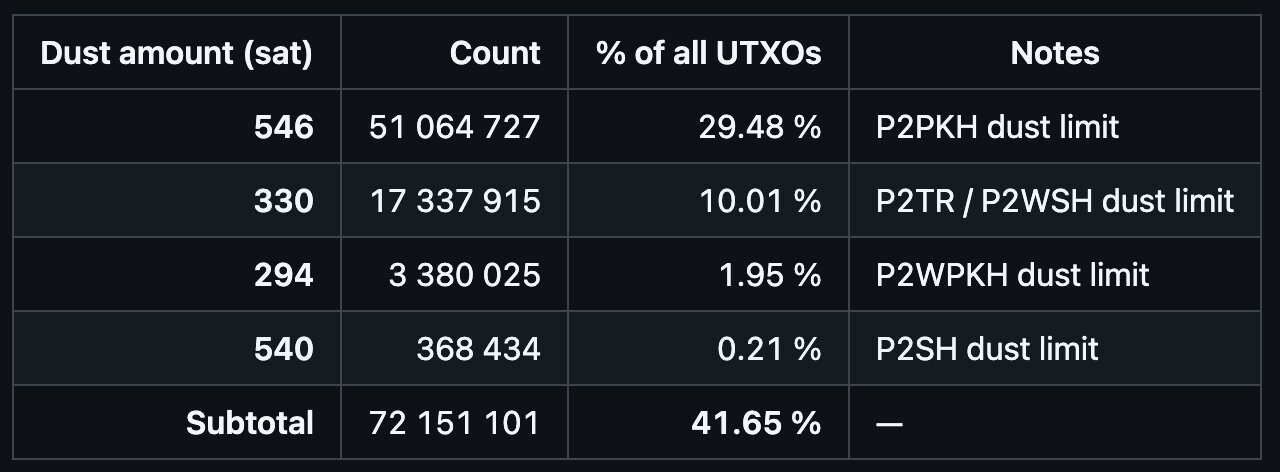
Thus, half of the UTXO set is likely spam-related. Since UTXO spam is permanent and unprunable, it is much worse than spam in the form of auxiliary transaction data.
Thus, we should think about ways to clean the UTXO set of these spam outputs.
Soft-Fork Proposal: Age-Based Expiration
Introduce a rule that makes very small, very old outputs unspendable. For example, let T be a UTXO’s age in years.
Once utxo_amount - T * dust_limit is negative, the UTXO expires and becomes unspendable. Expired UTXOs can then be pruned from the UTXO set.
Hi, author of the linked mempool research report on UTXO set here.
I don’t support this approach being applied retrospectively as it is confiscatory.
That said, useful to know that 41.65% of the UTXO set is dust amounts precisely at the implied default core policy dust limits for various script types.
Introduce a rule that makes very small, very old outputs prunable. However, retain the location of that UTXO—e.g., location = block_height/tx_index/output_index—indicating where in the blockchain the UTXO was created.
Users can still spend their UTXO if they include, in the annex of their spending transaction, an SPV proof (a Merkle inclusion proof of the transaction that created the UTXO, in a block in the chain).
This shifts the burden of storing the data from the global UTXO set to the user.
An expired UTXO’s location can be represented in less than 8 bytes. And since a set of locations has lower entropy, it is likely compressible to less than 8 bytes per expired UTXO.
This reduces spam by a factor of more than 8. In practice, that means of those +5 GB of spam, we could prune more than 4.3 GB. In particular, it would allow us to prune all of the bare multisig spam.
Robin, I appreciate the effort to tackle UTXO bloat it’s a legitimate scalability challenge. But the proposed method of expiring or pruning small, aged UTXOs crosses a line I think we should be very cautious about.
Introducing a rule that makes certain UTXOs unspendable based on arbitrary thresholds amounts to a protocol-level confiscation. That’s not a minor technical tweak it fundamentally alters the trust model of Bitcoin. People have always operated under the assumption that if they control the private key, their coins are safe, regardless of how small or old the UTXO is.
This change would undermine that assumption, possibly harming long-term holders, forgotten wallets, and low-income users disproportionately. It also opens the door to future proposals that may seek to invalidate UTXOs under different pretenses.
Instead, we should double down on solutions that preserve Bitcoin’s principles:
Encourage UTXO consolidation through dynamic fee markets.
Improve wallet UX to discourage spammy outputs.
Explore fee policies that penalize dust creation without invalidating it.
Cleaning the UTXO set is important, but not at the cost of breaking the core promise that Bitcoin makes to its users: your coins are yours, no matter how small or how long you’ve held them.
This approach is reorg-unsafe. You probably want to keep “txid:vout”, because this is what you need to make a valid input anyway. You can strip “scriptPubKey” in that way or another, or replace it with some hash, and require it from the user, but still: you don’t want to make your node cryptographically weaker, because then it could potentially accept an invalid transaction.
Yes, but if you want to go in that direction, then it doesn’t make sense to simplify it only for low-value UTXOs. If you assume, that reorgs cannot be deeper than N blocks, then you can simplify “txid:vout” for all UTXOs with more than N confirmations. And then, when you send transaction data, you can have the current format, where “txid:vout” is used, and some new, compressed format, used between new nodes, which would send everything in more packed way.
The format of locations is block_height/TX_index/output_index.
So if you experience a reorg back to block_height H you simply delete all locations which’s block_height > H from the expired UTXO set, and you add all locations which were spent in blocks that were reorged out.
However, I like your idea that you can replace expired UTXOs with, e.g., a 20-byte hash. That simplifies the scheme significantly, makes it cheaper to spend expired UTXOs, and still prunes about 75% of all spam.
Edit: Oh, now I see your point. There could be a UTXO which expired on the previous fork, but was spent on the reorging fork shortly before it expired. Then you would have already deleted it from your utxo set and can’t simply restore it to verify that valid block.
However, you can restore that deleted UTXO from its ‘location’ as long as you still have the block at block_height, in which that UTXO was created. And if you don’t have that block you can request it from your peers.
Because if it would be reorg-safe, then we could use it for all transactions. Maybe some unconfirmed ones could use “txid:vout” to know, what are you referring to, but everything else could simply refer to indexes in that case.
And I guess, if you apply it to every single transaction, then you can test some edge cases, and see, if things are really resistant to reorgs or not.
⚠ post #11 missing (not fetched, or removed/moderated on the source site)
There have been a lot of older proposals along the utxo commitment scheme lines, they generally run into the problem that maintaining a commitment over the UTXO set is so expensive that it destroys the savings. Like great you made it 1/4 the size but now requires a factor log(n) more work to update… that’s not a big win. And/Or they run into issues that the bottleneck for any particular user might be storage or it might be communication and making it cost log(n) work more to spend isn’t a win.
But perhaps scoping this to outputs which are unlikely to be spent, even unlikely to be spendable, and making their spending cost just come out of their tx size (so no further resource inflation for nodes)-- actually solves both of those issues.
Obviously anything with-confiscation is a non-flyer. The principle is important to uphold, and the fact that you floated it at all might outright sabotage the potentially useful idea.
I think there would also just be merit in setting a threshold value which no matter the age the output wouldn’t be pruned-- I believe this can probably be set so that all ‘real wallets’ are almost entirely above it while almost all outputs which are very unlikely to get spent (unless bitcoin increases in value a lot) are below it. This would greatly increase the pool of users for which the change has no effect at all and might oppose it because they don’t want any change at all.
If the rule against spending without a proof only applied to outputs in a range of heights, it would make it possible to adjust the thresholds both up and down with softforks. Except for a value of 0 it’s arguable that even 1 satoshi may be valuable enough in the future that there is no sense in doing this because it very likely will get spent. It’s a little less elegant, but the realpoltik of people being nervous about losing access to the coins they buried in the back yard (even though it likely wouldn’t be well founded) is worth keeping in mind. If it can optimize almost as well while leaving more people alone that’s better. And asking people to reason about the far future is just going to result in less agreement, e.g. given enough time some people 1 sat will buy a whole planet or something.
Invocation of annex assumes a particular script type, but a lot of the dust stuff is varrious script types. It’s arguable that this proof data should be “super-prunable” – after all it’s entirely redundant if you have the entire chain. So e.g. it could cost weight like regular data but be in a separate witness that you could skip downloading when processing the entire chain (since if you’re processing the entire chain you could just construct it yourself). At the very least it should be designed so that there are no degrees of freedom in the serialization so that even if it were in transactions it could be stripped and reconstructed to save sync bandwidth.
Does Utreexo have this issue? If done as a soft fork, it reduces the UTXO set storage requirement to about 1kb. It would make UTXO “spam” completely irrelevant. It has other benefits too, e.g. being able to validate the blockchain quickly with very little RAM.
This comes at the expense of making the input (witness?) bigger since the spender needs to prove that a coin exists.
In the very long run, e.g. 1000+ years, having every node store an ever growing unprunable UTXO set doesn’t seem ideal, with or without spam / dust.
It’s my view that it does today, yes. I’ll happily agree with you that in a long enough view the costs work themselves out – log() scaling things in particular because log() is essentially a constant beyond a certain size. But it’s no surprise that the optimal construction may differ at different parts of Bitcoin’s life.
Sync things aside (which have security model impacts)-- I don’t think Bitcoin is currently at a point where the utxo set size is dominating the costs of running a node: Consider how few nodes run node-limited (though I admit that’s a biased sample because of course it excludes anyone who just didn’t run it at all).
In any case, an insight to be skimmed here I think is that limiting commitments to coins that are unlikely to be spent might change the tradeoff surface-- cause for those you get the space reduction without as much overheads.
I agree—that’s why I’m not proposing a UTXO-set commitment.
Instead, the spender provides the usual SPV proof (Merkle inclusion of the transaction in its block), which you simply check against the header chain.
So the blockchain itself acts as a TXO commitment.
The only new data structure is a lightweight list of 8-byte “locations”, representing the unspent expired UTXOs:
Just to make sure we’re all talking about the same thing.
The observation that you get a log() scaling factor was made in the context of early commitment schemes, where the entire UTXO set is still kept, but organized in a Merkle tree so that proofs for it can be provided. This would indeed, within fully-validating nodes, be a significant extra cost, because every update to the UTXO set may now requiring updating \mathcal{O}(\log n) many internal nodes of the tree.
Utreexo is not that. It removes the UTXO set entirely from validation nodes, and instead lets them maintain just the commitment - however the network has to provide Merkle paths. The maintenance of the actual tree is (in theory) distributed over wallets, which maintain the paths for just the UTXOs they themselves care about. More realistically however, as it would be hard to switch over the entire ecosystem to Utreexo, it would involve bridge nodes that can translate proof-less transactions and blocks to proof-carrying one. Bridge nodes effectively maintain proofs for every UTXO, and they are the ones that now gain the \mathcal{O}(\log n) scaling factor (because every UTXO change may involve updating that many proofs). There may still be a gain, because bridge nodes aren’t quite on the critical path for validation, and can more easily be shared, but still: it introduces a critical component in the infrastructure that scales worse than full nodes today.
All this to say, I generally agree there is a tradeoff that’s unclear whether it’s worth making, but it isn’t one just inside validating nodes - I think pure Utreexo validation nodes would generally scale much better than today’s validation nodes, but at the cost of outsourcing an even worse factor elsewhere.
EDIT: I just realized you were probably talking about the \mathcal{O}(\log n) scaling factor for bandwidth? Utreexo has some tricks AFAIK to make it not that bad for block validation (lots of sharing between the paths) and transactions spending recent UTXOs, but fair.
That’s interesting, but I wonder if that is acceptable, why wouldn’t it be acceptable for everything? In a way it’s morally similar to Utreexo, in that it forces a (much weaker, but still some) responsibility onto wallets or bridging infrastructure to come up with proofs, reducing the responsibility validating nodes have. It has the advantage of not having expiring proofs (Utreexo proofs expire when the tree changes enough), but at the same time, it’s also only a minor gain to validation I think - still requiring them to maintain an indexed \mathcal{O}(n)-sized set, and significantly increased bandwidth (SPV proofs are larger than typical transactions).
It sort of falls in between Bram Cohen’s TXO bitfield idea (which is \mathcal{O}(n) in the size of the TXO set (not just unspent), but with an extremely small constant factor of 1 bit per entry), and Cory Field’s UHS idea where validation nodes store hashes of UTXOs, and the full UTXOs being spent are relayed along with their spending.
At the very least because of my point-- any overhead costs (from the bandwidth, yes) don’t apply when the output is not actually spent because its actually unspendable or just uneconomic to spend. So for at least these outputs the tradeoff seems easier.
Aside, I was just ignoring the spentness encoding because it can probably be represented much more compactly. (Though the first scheme I had in mind required having the block handy to decode it, so no good. )
Alas, that is problematic given that a single input can require a megabyte txout proof.
But it’s not fatal, you can just remember with every block header an additional hash for a root for some output tree, and proofs are against that. Wallets can remember their static fragments in that tree. Less reuse of existent datastructures, but at least it can be efficient and not have to present potentially a 1mb witness stripped transaction. One could even trim up the tree a bit by omitting provably unspendable outputs.
I would guess that historical data shows that fewer than 1 in 100 dust outputs are ever spent. So even with the extra Merkle proof needed if spended, the total footprint is still far smaller overall – especially for the most problematic dust outputs like P2MS, where we see orders of magnitude more spend-to than spend-from.
Could miners commit to the set of UTXOs being expired in each block, instead of requiring an SPV proof from spenders?
I believe this would remove the burden on wallets to construct proofs, and allow pruned nodes to validate spends simply by tracking which UTXOs were previously expired. It also opens the door to decoupling pruning from spending fee penalties:
dust UTXOs could be pruned AND subject to a higher spending fee as a deterrent, while older UTXOs that are simply considered unlikely to be spent (such as suspected lost coins) could be pruned without any spending penalty.
There is no need for any kind of “deterrent” as a freestanding goal, particularly in this context where the proposal reduces the cost of utxo bloat to essentially whatever it cost to track the (un)spentness.
From the perspective of the consensus rules it mostly doesn’t matter who constructs the proofs. From a security and autonomy perspective it must be realistic for the owners of the coin to do so on their own.
This proposal has the advantage the the proofs are static, so they’re basically free to construct-- the Bitcoin wallet even used to store exactly the txo proofs this proposal assumes though the behavior was removed because it wasn’t used for anything. (I point out above why sadly I think standard SPV proofs aren’t great but if this were adopted using them sufficiently old wallets even already have the required proofs, how cool is that?)
Of course you could also have other parties providing the proofs, – anyone who wants to, miners might well find it attractive since they collect the fees on the spend. But I think this question is mostly outside the scope of the consensus rules themselves.
⚠ post #21 missing (not fetched, or removed/moderated on the source site)
Wouldn’t that require everyone to resync the chain, though?
I think simply using txout proofs is fine, given that it is extremely unlikely that someone created a dust UTXO in a 1MB transaction which they want to spend someday after it would expire.
Also, people would have plenty of time to consolidate such dust outputs before the proposal would activate, so I think it is fair to shift the responsibility to those users who want to keep using dust outputs which are a significant burden for the whole system as they are indistinguishable from the spam that makes up half of the UTXO set.
Pretty much every regular user wouldn’t notice the change at all, because even if your UTXO is worth only $5 today, it would remain untouched for 100+ years.
[quote=“RobinLinus, post:22, topic:1707”]
Wouldn’t that require everyone to resync the chain, though?
[/quote] Just a reindex, which has been required for upgrades before. Only a very small percentage of nodes are pruned and otherwise the process could just be done invisibly in the background so long as you upgraded before the requirement was active. (Even if pruned it could be done invisibly in the background too, though obviously with a bandwidth cost).
If the node was pruned and didn’t care for the bandwidth cost and didn’t mind a reduction in autonomous security it would be easy to make the values importable.
A lot of these dust outputs are created by quite large transactions, and so constructing it with a txout proof makes the proposal easy to argue against. Some (though sure, not many) are created by txn so big that the txout proof wouldn’t fit, so that form is confiscating. The point that the value of the outputs are small only get you so far because some imagine bitcoin worth millions per coin in the not distant future, so I think it’s important that the non-confisciationess is sincere and not just ‘technically true’-- besides to the extent that the coins do get spent we wouldn’t want them wasting the block weight cap reinserting over and over again junk that is already in the chain.
I think a policy something like this could be interesting:
give utxos a score based on their value in sats and how long they’ve been in the utxo set, eg score = utxo_value - floor((tip_height - utxo_height)/2016) * 4000
when the score for a utxo drops below zero, move it from the utxo set into an accumulator, and require an accumulator-inclusion proof when spending
treat the accumulator-inclusion proof as free as far as block weight limits are concerned
That’s non-confiscatory, not only in the sense that any spendable utxo remains spendable, but also remains spendable with no increase in required fees.
(Having it be costed per byte at some ratio to witness bytes is also plausible, but I think would be slightly annoying – the proofs required could change at each block, depending on how the accumulator changes, and could grow in size, resulting in your tx’s feerate decreasing unexpectedly. Having it be costed as a flat per-accumulator-input could also work, but that would still make discourage cleanups of utxos in the accumulator, which might be something we’d prefer to encourage?)
Maintaining the accumulator-inclusion proof can be expensive (it may need to be updated every time the accumulator is updated, which requires maintaining a full node), however this can be outsourced, and can also be calculated from scratch at any point by reindexing the blockchain. I think a node running on consumer-level hardware could reasonably maintain a full set of utreexo accumulator-inclusion proofs for every utxo created in the past 20 years indefinitely, with costs only increasing roughly linearly as you bump the number of years up.
As at block 897,666 that rule would have the following impact:
currently, there are 171,366,598 utxos, using ~12GB of disk, with 19,867,488.3479_1527 bitcoins worth of value
after discarding based on the above rule, there would be 32,694,853 utxos remaining (ie reducing the utxo set size by ~81%, to perhaps 2GB or 3GB. the value of discarded utxos would total 34,761.7225_9465; about 25000 sats each on average
under this rule, a utxo worth less than 4000 sats (~$4 currently) would be dropped after two weeks, and a utxo worth less than 104,000 sats (~$100 currently) would be dropped after a year
about 27% of utxos were created in the past year (since block 845520), of those, 68% would be discarded under the above rule
in the 1000 blocks prior to 897,666, there were only 31 spends of utxos that would have been in the accumulator under this rule out of 7,304,674 total spends (0.00042%). Those spends were across 18 blocks (1.8%). No doubt there are periods where that number is much higher, though.
In the context of utreexo, I think this is the interesting part: the downside of utreexo is that every user has to construct/maintain proofs in order to broadcast their transactions, or rely on bridge nodes to do the translation for them, except that full bridge nodes are very expensive to run, and will only get more so as time goes on, which doesn’t seem ideal from a privacy/centralisation/efficiency point-of-view, at least to me.
In contrast, just doing it for old/low-value outputs that are rarely spent anyway means that most users are entirely unaffected, and that bridge nodes are only needed for people spending anything in the masses of low value outputs that are causing the problem in the first place. Likewise it reduces the bandwidth impact of adding proofs to the chain by quite a lot – you’re no longer adding proofs for utxos that are spent quickly, or that were high value, which is most spends. (With the parameters set at 4000sats and 2016 blocks, a 1.0 BTC utxo would not get moved to the accumulator until it had sat unspent in the utxo set for ~960 years, eg)
The downside, compared to utreexo, is that recent/high-value utxos are still stored individually, which still requires a database of a few GBs, rather than just the accumulator of a few kB. I believe that a value - floor(height/N)*V >= 0 calculation along with the supply cap and blocksize limit also implies a hard upper limit on the size of the utxo set, but I’m not sure off hand how you’d calculate it.
As far as implementation goes, the score calculation above could be rearranged to instead calculate acc_height = floor((value + 1)/4000)*2016 + height – the height at which the score becomes negative and the utxo should be moved into the accumulator. This could either be maintained as a separate index (if our utxo db supported that), or you could scan through the utxo set for any potentially affected utxos during the 2015 blocks where nothing changes.
Accumulator proofs that require updating though are problematic-- I think probably a lot worse than them costing weight even, particularly because they’re quite expensive for anyone who just wants to track all of them (an “index node”?). The idea that coins can be excluded from them is a good one, though if the criteria is too complicated I think people will justifiably worry that their coins will fall into them and then they are even worse off because they didn’t track the proofs. That’s why I was favoring a simple absolute limit: if your coins are above this value they’ll won’t get subjected to the accumulator. Also the non accumulated utxo set size has a fixed upper limit when you do that, – number of coins divided by that limit.
(Depending on how it’s set one could even bite the bullet and preallocate the usage!)
I wonder if it would be at all interesting to hybridize.. E.g. use a txout style proof that never changes for the coins identity and use a utxotree style proof for just the spentness bit. The total proof size would be increased, but nodes that maintain spentness wouldn’t need the spentness proof. (and probably the utxotree proof is smaller than you imagine since many spentness commitments could be stuffed under one leaf).
I think that’s a good idea. Dust Expiry should reflect a balanced principle: while every UTXO imposes a cost on the system, non-dust UTXOs also provide value—since the holder’s conviction contributes to Bitcoin’s overall worth. The mechanism should penalize only those UTXOs so small that their cost clearly outweighs their contribution.
Do you mean an accumulator scheme that allows state updates using an inclusion proof? Otherwise, if updating requires knowledge of the entire set, the accumulator introduces unnecessary overhead.
Also, the set of unspent expired UTXOs isn’t actually that large: location pointers of the form
pointer = (block_height, tx_index, output_index)
can be naively encoded in under 8 bytes. That amounts to roughly 800 MB for the ~100 million spam UTXOs created in recent years.
Moreover, the set can be compressed significantly. First, since the order doesn’t matter, you can sort the entries to reduce entropy. Second, both block_height and output_index have quite low entropy and can be compressed efficiently. So you can likely get away with 4 bytes per entry. Perhaps even less than 2 bytes.
And since this cleanup mechanism disincentivizes UTXO spam attacks, the set likely stops growing so rapidly.
I agree that it can be compressed. The interest in exploring the applicability of commitments is that this scheme still leaves UTXO cost O(N) just with a better constant factor.
It’s interesting to consider how that could evolve over time e.g. once the reduced cost justify doing something about it. Like the utxotree stuff results in a kilobyte of state, which 800MB (plus the non-dust utxo set) is very large against indeed. Particularly where someone may want a circuit that validates (most of) a block that difference matters. But the more efficient solutions have the problem of updatability, while the txo suggestion needs only a static proof which is a big win.
At least I’ve always found it useful to try thinking a couple steps ahead of any proposal, sometimes it results in changing how I think about it.
That seems somewhat dubious to me, I could argue for that side but it feels like a stretch.
Yeah, simple might be fine, though that becomes a different sort of dust limit, and maybe wallets will just decide “oh, I’ll ignore the complexity by just pretending values below that amount are unspendable / don’t exist at all”, making it more confiscatory in practice than in theory.
I don’t think it actually gives a very nice fixed upper limit; sending utxos at 20,000 sats ($20) or below straight to the accumulator still lets you potentially have 105 billion utxos at 20,001 sats each, using up about 7 terabytes of disk, assuming the entire 21M BTC is used for the attack. Of course, applying a budget constraint to the attack might fix that; if you’re discarding anything under as little as 4000 sats, then every additional 10GB added to the utxo set implies that ~5714 BTC ($570M) has been reserved by the attacker, and at 1sat/vb, I think recovering those funds would cost ~81 BTC ($8M, ~1.4% of the funds used).
Adding the time factor in doesn’t really help here though, because if the entire network is conspiring to fill your disk, they can just create too many new utxos in each block and hit pretty high numbers before any time factor comes into play. So perhaps that also argues in favour of simplicity…
One thing maybe worth worrying about is if low-value utxos are used briefly as part of L2 systems (eg John Law’s systems, perhaps some of the Ark designs); being able to create a dust utxo then spend it quickly without having an extra layer of complexity thrust upon you is probably nice, and also fairly benign as far as everyone else is concerned.
Perhaps that just means that you should move things to the accumulator if it’s below 4000 sats and older than 1008 blocks, or similar though.
In the worst case, over ~1000 blocks, I think you could create somewhere around either 10M utxos (normal-ish transactions), 30M utxos (as many outputs as possible), or 100M utxos (dummy utxos that are either unspendable or anyone-can-spend, and probably use up less space individually in the utxo set), using up between 700MB to 7GB on disk.
I guess you could probably also do something like “for the first 1000 blocks (1 week), you just need a txid/vout; after that, for the next 100,000 blocks (2 years), you need the txid/vout/block-hash/position-within-block to spend; and after that, you need to maintain/reconstruct a utreexo-style proof as well” could work.
Honestly I think it would be the reverse – if the UTXO set could grow without placing a burden on nodes, there’s no longer the same argument for preventing dust outputs, so probably not really a reason to reject them from mining/relay, which in turn would invite them to be used more frequently in L2 designs (“this output’s available if we need it, for unusual paths when participants disappear or try to cheat or something else weird happens, but normally we’ll just ignore it and let it expire into the accumulator forever”), creating significantly more of them.
Which less of an issue for log(n) scaling proposals as log(n) is eventually a constant, more of an issue for O(n) with a good initial constant!
On the other hand the proof costing weight is plenty of incentive for the decisions you mention favoring avoiding dust when they can.
For the subject of “your wallet might not implement stuff and abandon you” being functionally confiscatory. I think that’s a useful thing to consider, but I think it fundimnetally doesn’t get you far, as we’ve seen exactly that happen with stuff like “scanning blocks is unusably slow for our SPV wallet, guess we’ll just shut down”. The standard for confiscation has to be, I think, an assumption that the user can rip out the private key and use it with something that does work and that they’ll find it worth their time to do so.
Even bitcoin core has made it harder to use old wallets now, friction from software changing is just life.
As far as 7TB in storage costs that doesn’t seem that immodest to me, thinking in the long term. It’s a pretty good improvement on literally infinite.
The proof costing weight is a disincentive to spending dust, but not to creating it, though, so mostly makes this worse, rather than better, as far as I can see?
No effect to dust as a semaphore, I think. Disincentivizes creating many tiny outputs when you could create fewer larger ones, under the assumption they’re actually going to spend them eventually and not just use them for sequencing.
There was a time I would have been amiable to expiring near dust UTXOs or to introduce a “UTXO rot”, but since then we have alternative node designs proposed that either entirely remove the burden of maintaining a UTXO set or just simply ditch the UTXO set.
Currently I lean towards the UTXO set being the problem we should do away with not something we have to protect from bloating. Therefore this seems like something of no long term importance for the time being. The considerations we would also have to make are related to the future block size and parallelization of- and various technical bottlenecks in validation.
If I understand the tradeoffs correctly, Utreexo removes the need to involve IO in the validation / sync process as it can be performed in memory and if blocks stay at this size, then lack of parallelization is not a major concern. If sync is mainly IO bound and not CPU bound and also network speeds will be no obstacle, then the accumulators solve our problem in syncing up nodes with full validation without the barbarous disk murder ritual.
It comes at a different cost: you have to have a constantly updated proof to spend the coins. You can’t go offline and spend coins you know you have SPV style without having someone who has validated the chain provide you with an updated proof. And running an ‘indexer’ node that monitors proofs for all coins is very costly compared to running a node today. That model also increases the bandwidth needed for relaying transactions and blocks considerably. I think but am not sure that you can’t avoid the bandwidth increase by just having a today-style utxo set, because you’d need to provide proofs to non-local-utxo peers.
There is a reasonable argument that the asymptotic behavior means it will eventually be needed, but I think it’s harder to argue that it’s a good tradeoff now. So I think that makes alternatives with other tradeoffs interesting to discuss.
I was thinking about IBD / initial sync done via Utreexo style accumulators in memory. This ofc requires aid from nodes that can serve the blocks in that enriched form. However this just means the blockchain is validated in memory without involving IO not that you absolutely have to prune it. It becomes a smooth download and write to disk once kind of experience.
Once the node synced, it can switch to a standalone full archiving node or even Utreexo server depending on configuration. It can also just hang on to the Utreexo forest roots and header chain (few hundred megabytes). The point is the size of the UTXO set no longer would be a detriment to low powered node hardware to do full validating initial sync.
Ofc we can also decide that the UTXO set was a premature optimization that backfired and go with an alternative node design like libbitcoin. That has it’s own tradeoffs again.
Want to add: based on my recent experiments with syncing on ramdisk (which basically removes most of the the IO cost) I have to conclude that syncing - when enough RAM is available - is largely CPU (and ofc network) bound in practice. Because of the serious lack of parallelization it doesn’t really matter if there are many cores available, on average only 1 will be fully utilized at a time. Especially below assumevalid height with default settings.
edit: In this context Utreexo only helps with capping the RAM required for expedient validation, while can possibly hinder improved parallelization. Opportunistic write-through memory caching from OS explains why the sync is mainly CPU bound while the UTXO set fits into the unused RAM while nodes not clearly benefiting from larger dbcache settings in practice.
perhaps it’s not acceptable for everything because the incentive to attack the chain over a 1 year re-org (unlikely) is greater if the attacker can confiscate everything vs dust
I really like the idea you’ve outlined here. I’m working on a proposal that addresses dust by targeting dust created for clearly non-monetary purposes. I believe it’s superior to a blanket dust removal because, rather than touching all dust, it only acts on dust that can be deterministically shown to be spamming the network in support of non-monetary activity external to Bitcoin’s monetary function. This has the added benefit of also removing the financial incentives that drive much of this spam in the first place.
According to my analysis so far, at least ~40% of Bitcoin Core’s current UTXO set consists of dust under 1,000 satoshis that can be deterministically shown to match the classification rules for spam created by Ordinals (a type of Bitcoin spam) alone.
I also find your method of shifting the burden onto the user a very clever way of avoiding any confiscation risk. I’d love to explore whether something similar could be adapted to my proposal, although I’m not yet sure it’s compatible, since a key goal is also to reduce the incentive to continue this behavior going forward.
I’m curious about what you mean by “deterministic” here. I guess you mean something like, if you pass the dust utxo through a spam-checking-function f it always returns true, not just sometimes? Obviously in a very general sense you have no fully objective deciding function, but maybe you are trying to emphasize that it’s reliable for some subset? (To be clear I don’t believe anything like this makes sense, but I’m curious to understand the exact line of thought implied by that word).
Yes, you got it. The classification rules are specific and objective. They apply to on-chain data and can be verified by anyone using the same rules to produce the exact same set of transactions with no errors.