A technical aspect that has influenced those discussions is the impact on compact block relay.
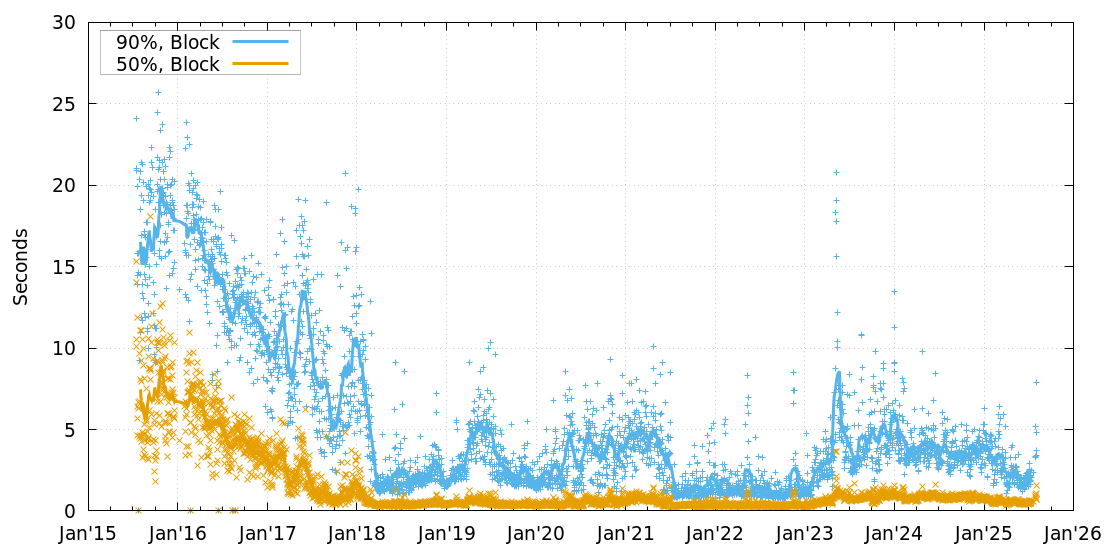
As a quick reminder, it’s fairly important for new blocks to be relayed quickly to other miners: if there are significant delays, that can both (a) increase the orphan rate for smaller miners, leading to higher comparative returns for larger miners, leading to centralisation, and (b) make attacks such as selfish mining easier to perform. Compact block relay, which was released in Bitcoin Core 0.13.0 in August 2016 provides a way to significantly improve block relay speeds, but relies on each node’s mempool making an reasonably accurate prediction of what transactions will be in the next block. When it gets it right, the current tip can be updated without requiring a round-trip over the network, potentially reducing relay time to a third of what it might otherwise be. This effect can be observed in the DSN Block Propagation History charts, driving block propagation times down from around 5s to very close to 0s:
The expected orphan rate if blocks take about 5s to propagate is perhaps 1.2 per day; if they take about 300ms, it’s about once every two weeks, roughly matching observed rates.
The practical impact of the adoption of diverse mempool policies by nodes and miners has been written up in another topic:
Last year, Greg raised the prospect of using weak blocks (including a proof of concept implementation), as one way to mitigate this – that way miners would (optionally) publish shares that didn’t quite hit the proof-of-work target to the p2p network, and peers would be able to see what miners are actually working on, while still benefiting from proof-of-work to limit just how much traffic they have to deal with.
To my mind, relying on proof-of-work has significant drawbacks: it biases towards groups with high hashrate, leading to a lot of repetition; and weak blocks will be spread out randomly across time, so if a miner with 10% hashrate wins the next block, their last weak block may well have been from 7 minutes ago (assuming weak blocks are 1/16th the difficulty of a real block), and thus be missing transactions, and still lead to a round-trip.
Template sharing
An alternative approach that I think could be made to work is simply sharing your block template with your peers. That is:
you regularly generate a new block template from your mempool,
you share that template with your peers when they ask for it
you request your peers send you their template regularly
you check txs in your peers’ templates, adding them into your mempool if they meet your policy requirements and you didn’t already have them
if they don’t meet your policy requirements, you keep the transactions in memory anyway, until you get a new template from that peer
when you attempt to reconstruct a compact block, you use your peers’ templates as a source of transactions in addition to your mempool
This can be done fairly efficiently: using the compact block encoding, sharing a template of 3000 transactions requires a 20kB message, and because sharing templates is not particularly time sensitive, it’s not much of a burden to request the missing transactions. Likewise, it’s not much of a burden to just skip a template entirely if you’re not able to cleanly reconstruct a template because the random numbers chosen give you conflicts.
This approach has a couple of other benefits/properties too.
It means that if you start up a node that either has an empty mempool or just one that’s out of date, it will very quickly be populated with what your peers think are the highest fee paying transactions. That’s beneficial not just for compact block relay, but also if your node is providing templates to miners, either as a pool template node, or as a datum or stratumv2 template provider for an individual miner.
It also automates rebroadcasting transactions that may have dropped from default mempools, once fees have reduced and they get to the top of the mempool. This primarily has privacy benefits – rather than the only person likely to rebroadcast a transaction in that scenario being the sender or recipient, any p2p node with a large enough mempool to have kept it will include the tx in its templates, and those nodes’ peers will rebroadcast the tx when they reconsider it for their mempools.
It also provides a way to query the top of random nodes’ mempools at fairly low cost, which may be useful for either overall analysis of network behaviour, or for detecting tx relay issues (in the event of pinning attacks, eg).
I’ve done a proof of concept of this approach at:
It’s setup to generate a template every 30s and keep the last ten generated templates (as a way of caching recently RBF’ed txs), it only announces templates to peers when all the txs in the template are considered to have been announced to that peer (base on last_inv logic), and it requests templates from outbounds once every 2 minutes. Transactions that failed mempool policies that might succeed later will be retried every so often.
It’s limited in that it will only request templates from outbound/manual peers (to limit the additional memory use to something on the order of 30MB), and would need some cleverer budgeting logic to safely store txs from templates from random inbound connections. It also doesn’t keep track of which transactions are actually in the mempool; doing that would likely make block reconstruction a bit more efficient, and is probably also necessary for any cleverer budgeting logic.
Starting a signet node with an empty mempool (but synced blockchain) looks something like this:
I love the idea; but combined with GETDATA this would allow for someone to obtain transactions a miner has deemed to valuable enough even with bad prop to be private.
Currently Antpool (all whitelabels) & MARA Pool participate in this behavior. Rebar labs offers this as a service.
But more realistically, whatever mechanism they have to prevent those transactions from being relayed currently could equally be used to prevent them from being included in the template responses proposed here.
I am kind of new to this topic and didn’t go through all of the previous weak block conversations but I am curious if usage of set reconciliation has been discussed in this context. Sharing templates is certainly the easiest way to implement and reason about such a feature but if we want to share more transactions than are included in one block/template I think it might be interesting to consider.
Good question, that’s been asked a few times now. I had a look at using minisketch / BIP330 for it.
I think there’s two immediate challenges:
BIP330’s still in progress so just reusing an existing implementation isn’t possible
minisketch has O(n^2) scaling for computation as the capacity increases, and the number of transactions in a block template is often much larger than the number of transactions in the INV queue. So when trying to figure out a new peer’s template, it might not be very suitable/efficient.
As far as updating a template goes, I’m not sure complicated set reconciliation is needed though – the sending peer knows what template they last sent to each peer, so could probably just send a diff if that template is recent enough to still be in memory: ie tell the receiving peer to drop these txs by position, then add these txs by short id and new position. That would probably reduce the template message from 20kB (3000 6-byte shortids) to 2.5kB (250 2-byte positions plus 250 6-byte short ids/2-byte positions).
Minisketch complexity is quadratic in the set difference, so what matters is the consistency not the size of the queue. I’ve implemented it and lab tested for block relay and it was highly efficient for it.
Before coming up with the ideas behind erlay my thinking was actually centered on continually reconciling the entire mempool. But the issue I ran into with that was that when there was a policy difference or a conflict race there would be a continual bandwidth loss until mining resolved it. Reconciling announcements avoids the issue. But except for the persistent difference problem reconciliation of the mempool and invs should otherwise take the same bandwidth and decoding cost.
But you are absolutely right about the preferable alternates: if you have a recent template from the same peer it’s better to just construct an edit– the edit is small and fast to construct, and should be compact on existing data.
One can also use minisketch to make predictable edits easier to communicate, but it may not be worth it (e.g. by using setrecon on the edits). Or may only be worth it periodically, like the first update or first update after a new block.
I think it’s worth considering avoiding salted shortids in further reconciliation protocols (deltas are a reconciliation protocol too!). We had to use them in compact blocks because making the short IDs very short was essential to making it efficient, and without the salting we’d probably want at least 128bit ids which would have put compact blocks consistently outside of TCP window sizes. But hashing the mempool results in a fairly large portion of the total reconstruction time particularly when you’ve missed txn and must hash the whole thing. Any scheme that mostly avoids sending IDs can probably get away with using 128 bit wtxids.
I think my general thinking is that in the future nodes should just maintain a clone of a small (say 4-8) peers’ “top two blocks” (or three blocks) of mempool via deltas and(/or) reconciliation with absolutely no policy restrictions (though if the peer exposes and invalid txn they should be disconnected). E.g. these little alternative mempools would even allow txn that conflicted with transactions in your own mempool.
So each peer would have in memory a 2-3 block mempool tip which is the last one they shared with other peers, plus one for each of a couple peers they’ve picked to remember. When a block comes in it can be relayed from or to any peer with a remembered template using highly efficient means.
This should largely eliminate policy differences and even conflict-announcement-announcement races as a significant source of block propagation delay. Memory usage would be moderate, costing at worst a hand full of megabytes per selected peer, but likely much less due to sharing the tx objects.
For this purpose, the order of transactions in the template doesn’t actually matter (at least until compact blocks, or some other block relay protocol, can make use of pre-sent orderings). This means there is a nice additional bandwidth saving possible.
Sort the set of all short ids (interpreted as 48-bit integers), and only send the differences, using Golomb-Rice coding, like BIP158 does. For a block with 4000 entries, the math I get that this only needs ~37.8 bits per element, rather than 48.
Of course, using an edit encoding w.r.t. the previous template can be a much bigger win, but that too can benefit from using some canonical encoding of the transactions (like the sorted shortids from above; there is no need for it to be topologically valid in this context).
If the originating node of the next PoW block shares its template ahead of time with its direct peers, they would be able to reconcile compact blocks at a much higher rate, but would there be much benefit for indirect peers? My understanding is that indirect peers would not be forwarding templates they received from others, or is that a thing in this design?
But in between the two extremes (1 being ~everyone+miners running the same policy, 2 being ~everyone running the same policy but miners another one), there is an intermediate situation, where there are a number of diverging policies on the network, one of which matches closely what miners do, and they’re sufficiently widespread that many network participants are connected to some peers with a miner-matching policy. It’s in such a scenario that the approach here has the most benefit.
That said, the extrapool does (or at least can if it’s size is large enough) substantially solve “one hop divergence” all on its own.
At least what I observe is that one hop is not enough.
It’s a little hard to give concrete measurements though because the big policy divergence right now has been minfee related and fee filter messes up the ability of the extrapool to address it.
My original concept was along the lines of “It would be nice if blocks propagated quickly even if they include transactions filtered by 95% of the network” – with the theory being that if 5% of the network isn’t filtering them (and is a strongly connected subgraph), then that gives listening nodes a >99% chance of having one of their peers be non-censoring, and thus they’d be at least theoretically able to get the tx in advance. That’s then good for censorship resistance, good for spam-filtering mining nodes who want to minimise their orphan rate, and good for nodes who haven’t kept up with the latest policy/soft-fork changes.
For that to work, I suspect you’d want to continually be reviewing updated templates from all your peers, not just a select few of them, though.
That only makes reducing the bandwidth and computation needed for processing updates more important, of course.
I’d really like to have something reasonably widely deployed on mainnet to be able to get some data to inform these sorts of decisions, so I think something simple to start with makes sense, that can then be refined later.
One idea might be to have a GETTEMPLATE request with no arguments just give a fresh 1MvB template encoded as a compact block, but to have something like GETTEMPLATE 2 d02b1b466de4ab17a64c9dc81f7677f39e3e67fea1a83610f22dd3def6c55062 request a 2MvB template encoded as a delta versus a specified previous template received from this peer.
One of the nice things about compact blocks is that the node sending the block only has to calculate the compact block once; if they had to re-encode the block’s tx list multiple times due to the different templates they’d sent recently, or, worse, the different templates each peer had sent them, that might be cumbersome.
Maybe something to think about would be having the receiver choose the salt and send it to the sender; eg GETTEMPLATE 0x8c7e823d78453ad3 0xdd6e8934258433c5 2. That puts some additional computational burden on the sender, but they only have to do the calculation on the txs in their template, so it shouldn’t be very burdensome. Meanwhile the receiver could give the same salt to all their peers, and pre-calculate and index the short ids for everything in their mempool.
That might be annoying in that it would let peers easily identify your node across distinct connections despite the use of tor/etc (though consistently providing the same templates would also do that). It might also allow adversarial nodes to construct txs that have the same shortid, resulting in reconstruction failures (if you had one of the txs but the template included the other).
Another option might be to continue using 6-byte short ids with a random seed chosen fresh for each template by the sender, but for the receiver to only compare it against the template pool (including their own template which might be the top 3 MvB of their mempool) not their entire mempool. That would result in more round trips and perhaps some avoidable tx retransmissions, but maybe that’s fine. If retransmissions are a problem, having a GETBLOCKTXIDS step to just get the missing wtxids rather going straight to getting the missing transactions could perhaps work.
At least having sender compute is a constant cost– however many txids are in a block. vs rx which might have to do several hundred times the work if they can’t cache it.
OTOH RX having a long lived id is an attack vector as its quite trivial to construct 48-bit colliding txn… so the ‘cost’ of working that way is having to continually assume that someone can do that. Compact blocks are at least protected by the root hash needing to match, so you’ll always detect that it failed.
It would perhaps not excite you for me to point out that the send could at essentially no cost send a tiny minisketch (like 8 element) over the last 64-bits of each txid and the receiver of a template could reliably detect a failure and recover from small number of collisions. (and if they know the colliding txn they don’t even need a minisketch decoder, they could just try the alternatives)
detecting unknown collisions, where the sender has wtxid A and the receiver has wtxid B and they both map to the same seeded shortid; assuming there are fewer than 4 such errors, when you calculate the minisketch, each A/B value will be reported, and because you can identify the B txs in your receovered template, you can request the A values
resolving known collisions, if the receiver has wtxids A and B that both map to the same shortid, you can know which one of them to include without a round-trip
optimising reconstruction, where you just calculate the shortids for the txs you think are highly likely to be in the block/template, then use the minisketch to tell you the 64-bit suffixes of the handful of wtxids you missed, then look those up in the mempool, check their shortids, and finish the reconstruction
Doing 8 elements (64 byte sketch) seems fine for the first two (detecting 4 unknown collisions, or resolving 8 known collisions), but you’d presumably want a bit more than that if you were trying to optimise reconstruction by ignoring most of your mempool on the first pass – maybe 64 or 128 elements (512 or 1024 byte sketch)?
If you did the latter, then a template delta could include a list of the changes by shortid (perhaps a few hundred new transactions in the last couple of minutes for maybe 4kB) plus a sketch (1kB) and be recovered by only examining a small fraction of the mempool and doing a minisketch calculation, I think?
Maybe you could save bandwidth a little further by doing up to three round trips: get the shortids+sketch, if there’s more problems than the sketch can resolve, get the 64-byte wtxid suffixes directly, and only then request the txs you’re missing.
Right my intuition is that you want to send some check value to confirm you got a correct decode regardless. You could just use a hash, but using a minisketch has the advantage of letting you do more than just pass-fail. An implementation could start by just using it as a pass/fail like a hash.
When doing the math on short-id collisions it turns out that the failure rate is dominated by cases where there is just a one or two collisions (unless the short-id is woefully too small), so being able to disambiguate just a couple is potentially useful.
Assuming it’s all unsalted the sketch is very close to free to compute, like store w/ txn their sketch values, and you just xor them when building the template (either on the sender side or as the receiver decodes).
I suggested size 8 kind of as a random example, with the thought in mind that overly small minisketches have a non-negligible probability of false decode. Though I didn’t bother to run the calculator to check (there is a function in the library), IIRC it’s cryptographically negligible by size 8 for 64-bit hashes but it might also be by size 4.
Information theoretically it should be possible to decode minisketch sketches well beyond the size limit if you happen to have a list of candidate elements that you expect to be more likely in the difference – like your own mempool or a list of collisions. Unfortunately we don’t currently know of a decoder that can exploit that which has subexponential complexity. So like a 64bit * 8 element sketch could teach you 8 elements that you’re missing, but it probably could tell you about removing 30 extra elements you have that you shouldn’t out of a collection of 1000. (the exponential decoder is the one that just brute force tries toggling every combination of your set then runs the ordinary quadratic decoder). I only mention it because this is a case where it would be handy to go beyond the bound, but it’s really a sidebar unless someone figures out how to make it tractable
If the receiver picks the salt for the ordinary short ids and has been caching it all along then it’s very cheap to do the decode anyways, so I don’t know that your third example is that compelling.
I was assuming the sender would choose the salt in that case, so you don’t have to worry about someone targeting you and giving you many conflicts (or having to worry about updating your salt and reindexing all the txs in the mempool). I guess if you changed your salt once every few minutes and reindexed, that wouldn’t be too expensive, and would let you avoid reusing salts with any given peer, which might make attempting to attack any particular salt fairly worthless.
It seems to me that sendtemplate is just transaction relay with extra steps. I don’t see the point, we should just focus on transaction relay instead, by increasing the size of the orphan pool, for instance.
A template (without using weak blocks) is costless to generate so is just an “extra step”. There’s also no way to know whether the sender is actually a miner and trying to mine the block. If I want to fill your orphan pool with junk that wouldn’t normally be relayed, I’ll just send all my peers templates with the junk txs. I think we need to think harder about relay policies against DoS, and instead using a (very) large orphan pool and blockreconstructionextratxn.
It is a way of relaying transactions, but the important/novel part of it is that it’s a way of finding out what transactions your peers think are likely to be mined. If nodes and miners maintain diverse transaction acceptance policies, that’s valuable information.
Orphan transactions are generally not useful for block relay – that they’re orphans means you don’t have their parent transactions, and any block that included the orphan but not the parent would simply be invalid. And once you have to ask for the parent, you’re already incurring the round trip cost you’d like to avoid.
The extra pool accepts any transaction that is below a certain size, which is fine as a best-effort approach, but is not particularly good. Expanding it significantly simply opens up an attack surface, allowing adversarial peers to fill your memory with arbitrary garbage (The datum recommendation of a million entries, combined with the 100kB per-entry limit could hit 100GB of memory usage, eg; Knots’s recent release has added an additional 10MB limit, which means that an adversarial peer can again clear your million-tx-capacity extra pool by sending 100 invalid txs (100*100kB = 10MB)).
what transactions your peers think are likely to be mined
…is simply false, and an attack surface identical to those you point out, just with extra steps. There is no way to know that the template sender is a miner and not just stuffing your tx DB in exactly the same way.
Anyone can put anything into a Merkle tree, that doesn’t mean it’s “likely to be mined”.
I find it surprising you’d simply assume AJ didn’t think about that. Under this proposal you maintain a template per peer, so one peer cannot evict other peers’ transactions. It can at worst waste a bounded amount of your memory.
Probably having a bastion node would be the best way to avoid sharing data, something like:
sequenceDiagram
Pleb<<->>Bastion: normal relay
Bastion->>Helper: txs, templates and blocks
Helper->>Miner: txs, templates and blocks
Miner->>Helper: txs and blocks
Helper->>Bastion: blocks only
Pleb<<->>Bastion: normal relay
Having a fake node that only relays txs to the miner, but never relays txs from the miner would probably work pretty well; having it pass on templates generated by the bastion node might help ensure CPFP txs and the like don’t get lost, but if the miner and bastion run the same policy and just have slightly different sets of txs, shouldn’t make a huge difference, I think.
Presumably you want something like that now, if you want to prevent early relay of secret transactions that don’t violate standardness rules.
This is published as BIN25-2 now. That only describes the basic protocol, not how to best use it, which is something still to be figured out. It also doesn’t allow for any sort of delta-encoding as discussed in this thread.
I’ve now done some very limited experimentation on mainnet with it, just between two peers running similar mempool policies. With that setup, I’d expect very few out-of-mempool txs to appear in the templates being shared. The ones I am seeing seem to take the form:
this tx was just RBFed, but the template was generated beforehand
this tx was confirmed in the previous block, but a new template hasn’t been created since that block came in
The just-confirmed txs seem like they might take a little too long to deal with (I’m seeing ~0.3ms each, but when they happen, it can be 3000 txs all at once so that’s still 1s of total processing that doesn’t really achieve any useful progress). But we already have a map of the last block’s transactions, so just using that to quickly move on seems like it might be fine.
The just-RBFed case could perhaps also be cached and skipped over, though I like the idea of reconsidering recently RBFed top-of-mempool transactions as a way of mitigating Riard’s replacement cycling attacks, so it might have the potential to be beneficial. In any event there aren’t that many of them and they and easily resolved, so aren’t much of a problem.
Still haven’t figured out a decent way of covering templates from honest inbound peers that works well in the presence of adversarial inbound peers.
On the other hand, one thing that occurred to me is that I think if you requested a template from feeler peers before disconnecting and attempted to add any novel txs they had to your mempool, that would provide a fairly good way of increasing relay connectivity to get around attempted relay censorship, without adding much of an ongoing burden.
With txs confirmed in the previous block excluded I’m seeing about 2 txs per minute that get (re)considered. They seem to fall into these buckets:
most of them are from slightly old templates where the RBF came through after the template was generated, but before I requested it
a few are due to an RBF missing a block, but the template is from before the block was found but does include the RBF tx
new transactions, that I had requested via INV/GETDATA but that hadn’t come through (the 1 minute delay to retry from another peer, vs the ~2 minute delay to request a template presumably means that top of mempool txs that aren’t getting a quick reply will often get requested via template sharing)
One way to reduce the RBF hits might be to change it so that rather than sending the latest template immediately, you mark the peer as wanting a template, and send the next template as soon as you generate it. That will make it much rarer to send a template based on an old block, and also much rarer for an RBF to arrive in-between the template being generated by the sender and being processed by the receiver.
After some more mainnet experimentation (updated spec and code linked here), I’m a little bit disappointed at the amount of traffic it’s using:
node
direction
inv
tx
tmplt
tmplttxn
nodeA
sent to
inv=35M
tx=4M
tmplt=16M
tmplttxn=9M
nodeA
recv from
inv=15M
tx=15M
tmplt=16M
tmplttxn=4M
nodeB
sent to
inv=19M
tx=138M
tmplt=6M
tmplttxn=13M
nodeB
recv from
inv=7M
tx=3M
tmplt=6M
tmplttxn=461K
That feels a bit too close to an additional peer’s worth of INV traffic to me, which is probably manageable, but I was hoping for better, and as a result I’m exploring using minisketch to reduce it.
Current theory is to use 46-bit short ids (since per the minisketch docs that hits a sweet-spot with the CLMUL implementation, and it gives low odds of false positives with thousands of entries comparing against a full mempool), and use a bisection approach over 8 sketches with 256 capacity – so a single sketch at ~1500 bytes gives you perfect recovery if you’ve got fewer than a couple hundred differences, 4 sketches gives you good odds of recovery if you have fewer than ~1000 differences, and you only communicate a full set of shortids if you don’t catch it with 8 sketches, and have over ~2000 differences.
Anyway, plan is to try to get that working and see how it performs – I’m pretty optimistic that many cases will only need a single sketch to get fully resolved, which I think will be fine. But if not, we could probably do smaller (32 byte?) shortids, by adding a second small sketch over (part of) the actual wtxids to catch the small number of false positives that sneak through.