Introduction
Hello everyone. I’ve been developing a high-throughput implementation called UltrafastSecp256k1. The project, which was open-sourced on February 11th, 2026, started as an exploration of how modern hardware features (SHA-NI, AVX2, ARM64 Assembly) can be leveraged to push the limits of ECC performance across diverse platforms—from high-end x86 servers to resource-constrained IoT devices like ESP32-S3 and RISC-V boards.
The goal is to create a highly portable, constant-time, and branchless library that is accessible through multiple language bindings (12+ languages including Rust, Go, Swift, and Dart). I am reaching out to this community for a technical audit, feedback on the cryptographic primitives, and suggestions on our constant-time implementation.
Architecture & Core Optimizations
The library is built on a “Zero-Allocation” hot-path contract, ensuring no heap overhead during critical operations. Key technical pillars include:
Field Representation: We transitioned to a field representation for Point internals, enabling __int128 lazy reduction across constant-time (CT) operations.
Constant-Time Field Inversion: Implemented using the SafeGCD (divsteps) algorithm, specifically optimized for different architectures (e.g., divsteps for robustness).
Scalar Multiplication: Leverages GLV Endomorphism via -decomposition combined with interleaved double-and-add, significantly reducing the cycle count for .
Hardware Acceleration: We use SHA-NI (Intel/AMD SHA Extensions) for high-speed hashing dispatching and AVX2 CT table lookups for secure, constant-time scans.
I-Cache Efficiency: We utilize noinline on large functions like jac52_add_mixed_inplace to prevent instruction cache pollution, resulting in a ~59% reduction in I-cache misses.
Platform-Specific Implementation & Benchmarks
We have focused on making the library performant where it’s needed most:
x86_64: Utilizing Comb precomputation tables (teeth=6, blocks=43) to optimize operations, achieving significant speedups over standard implementations.
ARM64 (Android/Linux): Hand-tuned multiply/square bypasses directly calling assembly, optimized for Cortex-A76 and newer cores.
Embedded & Emerging: Current support for ESP32-S3 and upcoming optimizations for RISC-V (Milk-V Mars).
Current State (v3.10.x):
The library currently passes over 12,000 consistency tests across x86 and ARM64 platforms. The ecosystem includes full bindings for NPM (Node.js/React Native) and NuGet (.NET), making it ready for high-level integration.
Request for Review & Technical Discussion
I am specifically looking for feedback on:
Constant-Time Integrity: Review of our assembly bypasses for potential side-channel leaks.
Algorithm Selection: Evaluation of our H-Product Serial Inversion and SafeGCD implementation details.
Branchless Logic: Suggestions for further removing branches in the point-normalization and signing flows to improve security.
The project is fully open-source, and I believe that peer review from the Delving Bitcoin community is vital to ensure this tool remains both fast and secure for the wider ecosystem.
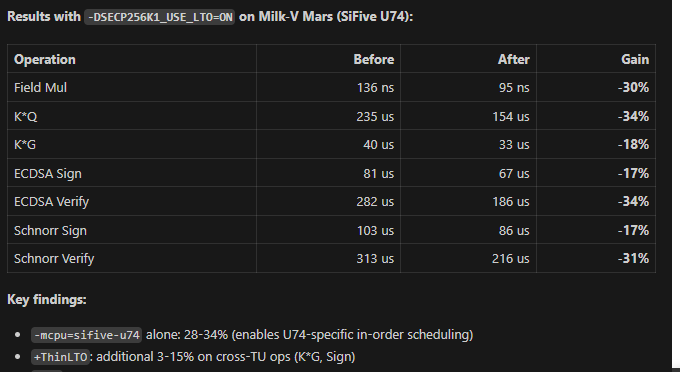
Just finished the RISC-V optimization sprint for Milk-V Mars (SiFive U74). Using U74-specific in-order scheduling gave us a 34% boost in verification speed. This is part of the v3.11 roadmap to make UltrafastSecp256k1 the go-to library for resource-constrained IoT devices. Cycles don’t lie!
I wonder what your expectation is. If it is that someone here will make the effort of reading and reasoning about more than 150 000 lines of cryptographic code, then I deem that the probability that this happens is negligible.
My main piece of feedback is that the license is not a good fit for the Bitcoin system ecosystem. Almost everything in the ecosystem uses the MIT license. Picking the AGPL means that essentially no projects will be able to use your code, even if they wanted to.
Thank you for the candid feedback — I appreciate it.
You’re absolutely right regarding the license friction. After reflecting on your comment and the broader ecosystem norms, I’ve decided to switch the project to the MIT license to better align with Bitcoin Core and related projects.
My intention was never to create adoption barriers. The goal is to build a portable, zero-dependency secp256k1 engine that can be evaluated and integrated freely.
I understand that a full manual review of a large cryptographic codebase is unrealistic without structured audit scope. I’m currently working on:
• A clear threat model document
• A minimized audit surface breakdown
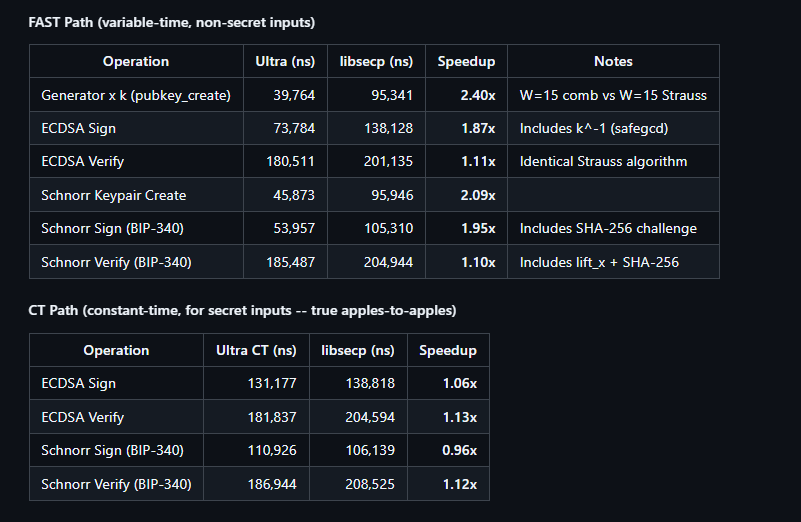
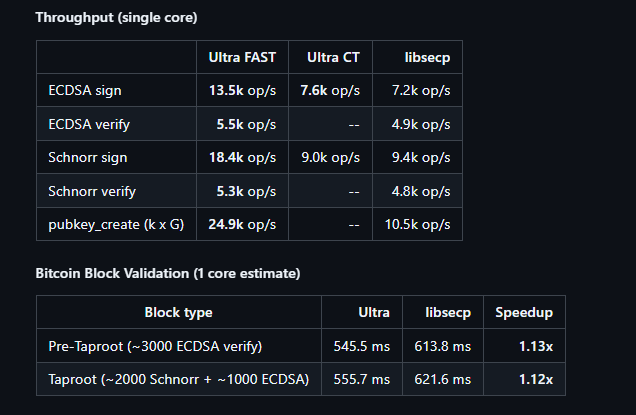
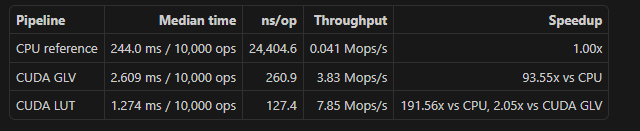
• Reproducible apples-to-apples benchmark harness
• Cross-implementation comparison vs libsecp256k1
Any targeted feedback on specific subsystems (e.g., scalar arithmetic, field layer, constant-time strategy) would already be extremely valuable.
I’ve been experimenting with BIP324 v2 encrypted transport and wanted to share some measurements around its performance characteristics, focusing on throughput, latency, and batching effects.
The goal was not to propose changes, but to better understand where the actual costs are and how they scale under different execution models.