opened 02:24PM - 04 Mar 26 UTC
# CPU Performance Report: UltrafastSecp256k1 vs libsecp256k1 in BIP-352 Silent P…ayments Scanning
## Summary
I integrated UltrafastSecp256k1 (v3.16.0) into a DuckDB extension for BIP-352 Silent Payments scanning and benchmarked it against an equivalent extension using bitcoin-core/secp256k1. In this real-world workload, **UltrafastSecp256k1 is 1.7-1.9x slower than libsecp256k1** on x86-64 Linux, contradicting the project's claimed 1.47x overall speedup (CHANGELOG v3.15.0, `bench_apple_to_apple`).
## Context
[Frigate](https://github.com/nickg/frigate) is an Electrum server for Bitcoin Silent Payments (BIP-352). It uses DuckDB with custom extensions to scan transaction tweaks against a wallet's keys. I maintain three DuckDB extensions:
- [**duckdb-secp256k1-extension**](https://github.com/sparrowwallet/duckdb-secp256k1-extension) — CPU scanning via libsecp256k1's C API
- [**duckdb-ufsecp-extension**](https://github.com/sparrowwallet/duckdb-ufsecp-extension) — CPU scanning via UltrafastSecp256k1, plus GPU-accelerated scanning via CUDA
- [**duckdb-cudasp-extension**](https://github.com/sparrowwallet/duckdb-cudasp-extension) — GPU scanning via a separate CUDA library
I implemented a `scan_silent_payments` scalar function in the ufsecp extension (on the [`cpu_scalar_fun`](https://github.com/sparrowwallet/duckdb-ufsecp-extension/tree/cpu_scalar_fun) branch) that mirrors the secp256k1 extension's function exactly in signature and behavior, to allow a direct performance comparison.
## BIP-352 Scanning Pipeline (per row)
Each row in the scan performs these operations:
1. **EC scalar multiply** (fixed K, variable Q): `shared_secret = tweak_point * scan_private_key`
2. **Serialize** to 33-byte compressed SEC1
3. **Tagged SHA-256**: `hash = tagged_sha256("BIP0352/SharedSecret", serialized || 0x00000000)`
4. **Generator multiply**: `output_point = hash * G`
5. **EC point addition**: `candidate = spend_pubkey + output_point`
6. **Match check**: compare upper 64 bits of candidate x-coordinate against outputs list
7. **Label iteration**: for each label L, compute `candidate + L` and re-check
The bottleneck is the two scalar multiplications (steps 1 and 4).
## UltrafastSecp256k1 Optimizations Used
The ufsecp implementation uses several UltrafastSecp256k1-specific optimizations not available in the libsecp256k1 version:
- **KPlan precomputation**: The scan_private_key is constant across all rows. I precompute a `KPlan` (GLV decomposition + wNAF encoding) once and reuse it via `scalar_mul_with_plan()` for every row. This avoids repeated GLV decomposition.
- **Tagged hash midstate caching**: The `"BIP0352/SharedSecret"` tag midstate is computed once and reused via `cached_tagged_hash()`.
- **Static caching**: Both the KPlan and midstate are cached in static variables keyed on the scan_private_key, so they persist across DuckDB query invocations.
Despite these optimizations, the ufsecp version is significantly slower.
## Benchmark Results
**Hardware**: x86-64 Linux (same machine for all tests)
**Workload**: BIP-352 Silent Payments scanning over Frigate's DuckDB tweak database
**Both extensions produce identical results** (verified on both datasets)
### Testnet4 (~56,000 rows)
| Extension | Backend | Wall Time |
|-----------|---------|-----------|
| duckdb-secp256k1-extension | libsecp256k1 (scalar fn) | **24.2s** |
| duckdb-ufsecp-extension | UltrafastSecp256k1 `scan_silent_payments` (scalar fn) | 45.3s |
| duckdb-ufsecp-extension | UltrafastSecp256k1 `ufsecp_scan` (table fn, batched) | 50.7s |
| duckdb-ufsecp-extension | CUDA GPU `ufsecp_scan` | 1.8s |
**UltrafastSecp256k1 scalar function: 1.87x slower than libsecp256k1**
### Mainnet (~880,000 rows)
| Extension | Backend | Wall Time |
|-----------|---------|-----------|
| duckdb-secp256k1-extension | libsecp256k1 (scalar fn) | **378.3s** |
| duckdb-ufsecp-extension | UltrafastSecp256k1 `scan_silent_payments` (scalar fn) | 647.7s |
| duckdb-ufsecp-extension | UltrafastSecp256k1 `ufsecp_scan` (table fn, batched) | 610.6s |
**UltrafastSecp256k1 scalar function: 1.71x slower than libsecp256k1**
### Note on the batched table function
The `ufsecp_scan` table function uses additional batch optimizations (Montgomery batch Z-inversion, batch affine addition) on top of the same UltrafastSecp256k1 primitives. Even with these, it is still 1.6x slower than libsecp256k1's non-batched scalar function on mainnet.
## Analysis
### Per-row cost breakdown
The BIP-352 pipeline is dominated by two scalar multiplications per row:
| Operation | libsecp256k1 (estimated) | UltrafastSecp256k1 (estimated) |
|-----------|-------------------------|-------------------------------|
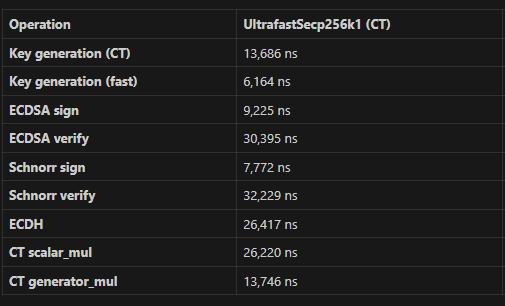
| EC scalar multiply (fixed K, variable Q) | ~15-20 us | ~25 us (with KPlan) |
| Generator multiply (k*G) | ~12-15 us | ~6 us (precomputed) |
| Serialize compressed | ~3 us | ~3 us |
| Tagged SHA-256 | ~0.5 us | ~0.3 us (midstate cached) |
| Point addition | ~1 us | ~0.5 us |
| **Total** | **~32-40 us/row** | **~35-45 us/row** |
The generator multiply is faster in UltrafastSecp256k1, but the arbitrary-point scalar multiply (the dominant operation) is significantly slower.
### Why the `bench_apple_to_apple` results don't translate
The project's own `bench_apple_to_apple` (CHANGELOG v3.15.0) claims "7 FASTER, 5 EQUAL, 0 SLOWER (geometric mean 0.68x = UF 1.47x faster overall)" against libsecp256k1 v0.6.0 on 13 operations. However:
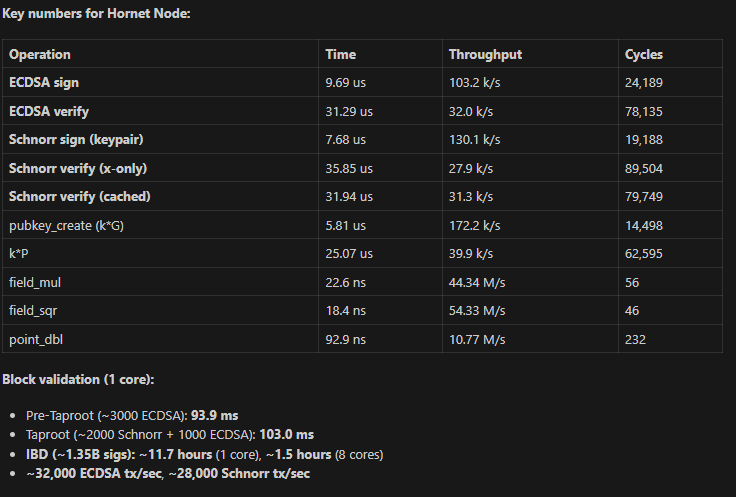
1. **The benchmarks primarily measure signing and verification paths**, not the raw scalar multiplication that dominates BIP-352 scanning. The project's own `bench_hornet` report (Windows, i7-11700, Clang 21.1.0) shows:
- Generator multiply (k*G): 5,976 ns (UF) vs 15,402 ns (libsecp) — **2.58x faster** (UF wins)
- ECDSA Verify: 30,743 ns (UF) vs 25,423 ns (libsecp) — **0.83x, libsecp wins**
2. **The 1.47x claim uses geometric mean across operations with very different weights.** Generator multiply shows a large speedup (2.58x) but arbitrary-point scalar multiply — which is the bottleneck in BIP-352 scanning — is not separately benchmarked in the apple-to-apple suite.
3. **libsecp256k1 uses hand-tuned x86_64 assembly** (5x52-bit limbs with inline asm, carefully scheduled `mulx`/`adcx`/`adox` instructions). UltrafastSecp256k1 uses portable C++20 which, while producing good code, does not match hand-written assembly for field arithmetic throughput on x86-64. Note that both libraries use the FAST (variable-time) path in this workload — the scan key multiplies public tweak points, so constant-time guarantees are not required.
4. **The bench_hornet v3.16.1 comparison** (4 platforms, libsecp256k1 v0.7.2, 6-op suite) confirms the pattern: UltrafastSecp256k1 wins on generator multiply and signing, but loses on verify operations that are dominated by arbitrary-point scalar multiplication — the same operation that dominates BIP-352 scanning.
## Recommendation
The README's title claim "Fastest Open-Source secp256k1 Library" and the CHANGELOG's "1.47x faster overall" should be qualified:
1. **The claims don't hold for workloads dominated by arbitrary-point scalar multiplication on x86-64.** Generator multiply (k*G) is genuinely faster in UltrafastSecp256k1, but k*P (arbitrary point) appears significantly slower, and k*P dominates in many real-world protocols.
3. **The GPU backends are genuinely impressive and unique** — no other open-source library provides secp256k1 ECDSA/Schnorr on CUDA/Metal/OpenCL. The GPU performance (1.8s vs 24.2s on testnet4) is the real differentiator.
4. Consider adding a benchmark for **arbitrary-point scalar multiplication (k*P)** to the apple-to-apple suite, as this is the dominant operation in many real-world protocols (ECDH, BIP-352 scanning, key tweaking).
## Environment
- **OS**: Linux 6.17.0-14-generic (x86-64)
- **UltrafastSecp256k1**: v3.16.0 (submodule in duckdb-ufsecp-extension)
- **libsecp256k1**: latest master (submodule in duckdb-secp256k1-extension)
- **DuckDB**: v1.4.4
- **Compiler**: System default (GCC/Clang via CMake)
- **Build**: Release mode, `-O3`