
I always compile the bitcoin software myself (Ubuntu 24.04.2 LTS). For bitcoin-29.0 I compiled it (of course) for the first time with cmake (with and without berkeley-db).
For both (with and without berkeley-db), bitcoind-29.0 is much slower than bitcoin-28.0 which gives me problems on my server.
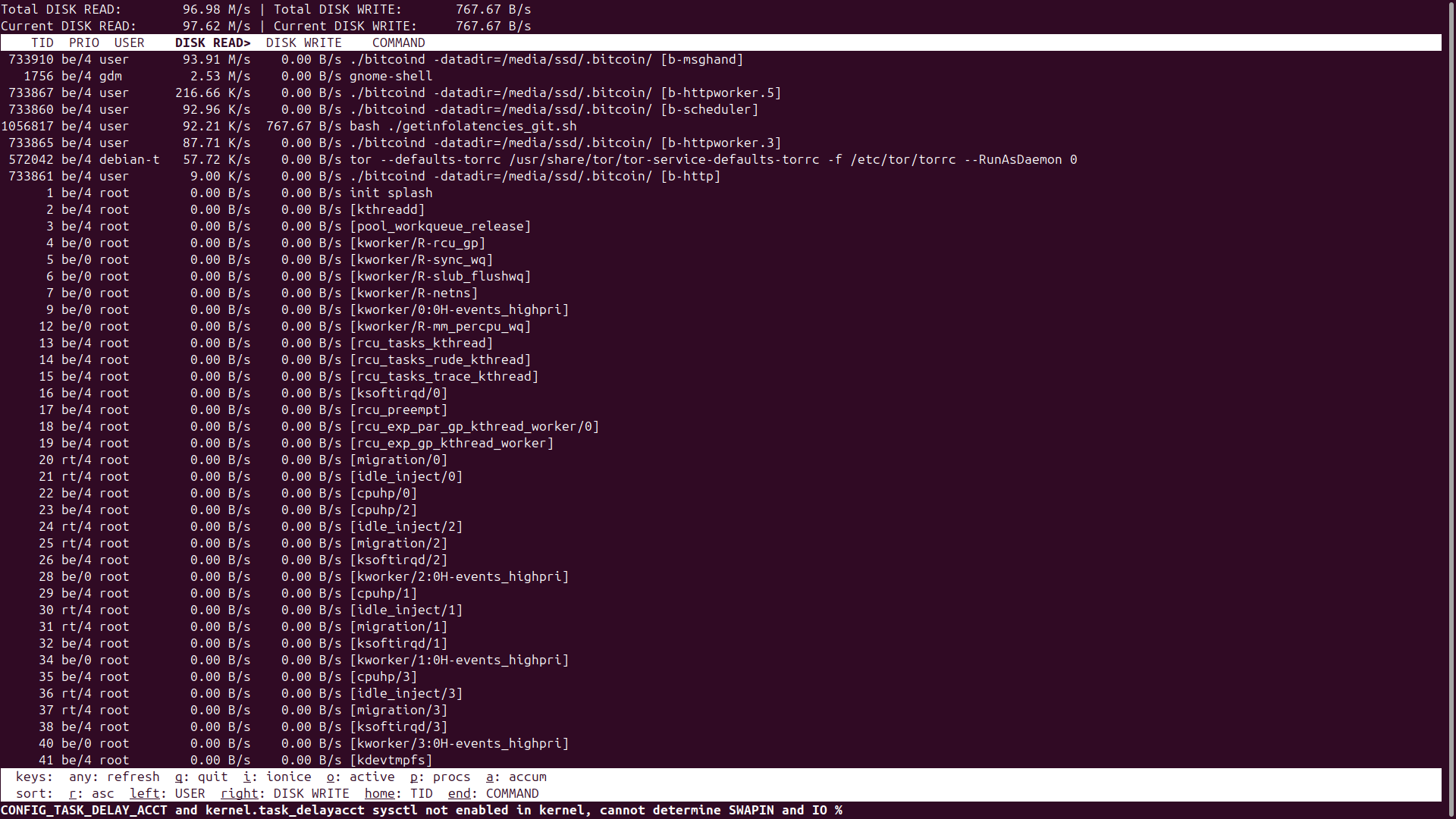
To investigate I wrote a shell script that determines the time difference in seconds between “Saw new header” and “UpdateTip”:
02025-05-09T05:24:11Z Saw new header hash=0000000000000000000213e630619be8945d471d06b0395fb6adca797877527d height=895920
12025-05-09T05:24:11Z Saw new cmpctblock header hash=0000000000000000000213e630619be8945d471d06b0395fb6adca797877527d peer=5197
22025-05-09T05:24:12Z UpdateTip: new best=0000000000000000000213e630619be8945d471d06b0395fb6adca797877527d height=895920 version=0x2a4aa000 log2_work=95.598602 tx=1188522869 date='2025-05-09T05:23:59Z' progress=1.000000 cache=216.6MiB(1587712txo)
which in this bitcoind-28.0 example is only 1 second. This is typical for bitcoind-28.0 on my system where it is between 0 and 1 seconds with only very occasionally a bit longer. Now for bitcoind-29.0 it’s much longer:
Block nr: delta t in seconds 895579: 3 895580: 3 895581: 4 895582: 2 895583: 16 895584: 65 895585: 8 895586: 280 895587: 81 895588: 133 895589: 124 895590: 3 895591: 73 895592: 153 895593: 284 895594: 528 895595: 17 895596: 8 895597: 4 895598: 2 895599: 3 895600: 4 895601: 6 895602: 3 895603: 2 895604: 5 895605: 5 895606: 34 895607: 2 895608: 6
This is true whether it’s compiled with or without berkeley-db. So mometimes it takes several minutes!
So I did some investigations. The first thing I found was that my bitcoind-29.0 and others are much bigger than the pre-compiled ones:
Precompiled 29.0 (du in MB):
3 bitcoin-cli
16 bitcoind
42 bitcoin-qt
5 bitcoin-tx
3 bitcoin-util
10 bitcoin-wallet
28 test_bitcoin
For my self-compiled 29.0:
21 bitcoin-cli
273 bitcoind
47 bitcoin-tx
21 bitcoin-util
134 bitcoin-wallet
511 test_bitcoin
Although normally I use some compiler options, here for comparison compiled according to the docs: (cmake -B build; cmake --build build; cmake --install build)
Both (my and pre-compiled) test_bitcoin work fine. Note that also my (not too slow) bitcoind-28.0 (etc) is about the same too big a size (269 MB) as my bitcoind-29.0. So I had this before but never noticed.
So my first question before I investigate any further is: how come my bitcoind is so big compared to the pre-compiled one?









{kind=link}
{kind=link}