[WIP] Aggregate signature module implementation #461
pull apoelstra wants to merge 1 commits into bitcoin-core:master from apoelstra:newschnorr changing 10 files +758 −0-
apoelstra commented at 1:22 pm on June 19, 2017: contributor
-
apoelstra commented at 1:29 pm on June 19, 2017: contributorIn verification I use Bos-Coster to do the multi-exp which is very fast (consistently about 830 iterations for ten random scalar/point pairs, an iteration being a point-add and a scalar-subtract). Interestingly this does not require any pre-computation. However if you use the aggregate verifier with only one or two points the performance is relatively bad, in the one-point case it just breaks down to using a binary addition ladder. Fixing this would require I change the API to require a verify-enabled secp context, which sucks to require for just a special case. Thoughts?
-
in src/ecmult_multi_impl.h:93 in e15404c86a outdated
88+ secp256k1_scalar max_s; 89+ secp256k1_scalar max_s1; 90+ secp256k1_gej max_p; 91+ secp256k1_gej max_p1; 92+ 93+iter_count++;
apoelstra commented at 1:31 pm on June 19, 2017:Oops, hanging debug code. Should I expose this somehow or just delete it?apoelstra commented at 2:11 pm on June 19, 2017: contributorShould state-machine violations (e.g. trying to create two partial signatures with same key/nonce) beARG_CHECKerrors or just return failure?apoelstra force-pushed on Jun 19, 2017apoelstra force-pushed on Jun 19, 2017gmaxwell commented at 11:28 pm on June 19, 2017: contributorverify-enabled secp context
I expected it to need this for the edge case.
What I haven’t benchmarked out but think might be interesting: switching to a boring multiexp once enough points have dropped out that bos-coster is not making much progress anymore. (though this wouldn’t be the existing very code, it would be optimized for smaller number (e.g. no endomorphism, smaller precomp, perhaps “joint-point” precomp).
gmaxwell commented at 11:31 pm on June 19, 2017: contributorin your heap, I believe you will get better performance if the heap itself is on indexes to entries which themselves don’t move around… your comparison code would know how to dereference the indexes. Because you support only a max of 32 right now char would be fine.apoelstra commented at 10:57 am on June 20, 2017: contributorHeh, yeah, on 30-key signatures using indices in the heap gives a 15%+ improvement on verification speed, which means we now take only 47% as long to verify compared to 30 individual verifications. (These numbers to be taken with salt, given I’ve only done a few measurements and I’m using my battery-backed laptop with a bunch of other stuff running. But they are pretty consistent.) Before we were at 57%.
Using an index-only heap not only gets rid of a bunch of copying, it lets us do swaps with the triple-xor trick (
x ^= y, y ^= x, x ^= y). Also inecmult_multiI was removing the second-to-max point, changing the point but not the scalar, and putting it back. This is an expensive no-op for a scalar-ordered heap, so I stopped doing that.Next I’ll try catching scalar 1’s and adding their points to a running return value rather than spamming the heap with them, and using the endomorphism, but I may be in the air for the next 10+ hours and unable to report.
gmaxwell commented at 7:14 pm on June 20, 2017: contributorYou need a heapify: repeated insert is O(N log N) instead of O(N).
While working on this before I came up with an optimization that halved the number of comparison operations; after googling a bunch I found it had a name, but I don’t recall the name or the exact optimization and searching again is failing. :(
I think (part of) it went like this: when starting pop the first element and set it aside in a separate super-root position effectively outside of the tree. Then in each iteration, read the super-root and root, compute the new values. Swap the root and super-root (since the root will now be the highest value) then rebalance the root. This saves replaces the rebalance in both the delete+insert with just a single rebalance.
I keep thinking there was another optimization which came from enforcing the heap property less strongly which was possible because no insertion is needed (only delete and replace, which only sweep the heap in one direction), but I don’t recall what that part was. :(
It would be useful to know what a profile looks like .. e.g. how much of the time is spent in comparisons– this would tell how much gain there would be from optimizations like the above or from speedups in the comparison (e.g. storing the number of non-zero words in the scalars, so comparison can compare just those values or if equal start on non-zero words).
For your figures above for the 10 point case 12% of your adds will be gej+ge, so it will likely be faster to detect and switch to the special case. (stop me before I make some observation that there is some crazy effective affine trick that can be done by tracing the computation depth of each point, and putting all at the same depth on the same isomorphism)
apoelstra commented at 11:42 pm on June 20, 2017: contributorVery tired. Gained a fair bit by replacing the scalar subtraction with simpler code that doesn’t do a modular negation, and another fair bit by hashing less stuff (pre-hashing all the constant stuff). Tried switching to native int math in a couple ways when the scalars got small enough, that had no effect I could observe.
The endomorphism helped but not as much as I wanted it to. Had some frustration with
lambda_scalar_splitgiving me negative numbers, these result in putting a mix of 256-bit and 128-bit numbers into the Bos-Coster ladder, which poisons it (it gets into an effectively infinite loop repeatedly subtracting a small number from a big one). You have to detect this and negate so that everything is the same bit-size, which slows you down.Agreed profiling would be good at this point to see what’s actually happening. I’m doubtful at this point that the heap is costing us a lot, but we’ll see. Will try the gej+ge thing a shot, that’s quick and easy to do.
Spent some time thinking about effective affine, I didn’t get anywhere, but maybe I’m just missing something obvious.
gmaxwell commented at 2:31 am on June 21, 2017: contributorRe: on where my arms were waving about effective affine like tricks. on my desktop, gej+ge is .181us faster than gej+gej, subtracting of 0.0644us per pubkey for additional fe multiplies, it would only take a batch of 29 points that would later gej+ge to pay for the cost of a feinv to bring them back to affine.
So, e.g. as points are changed to no longer be affine they could be removed from the heap, and once half the points are removed (ratio will depend on the tradeoff in the asymptotic behavior of the algorithm), the whole thing batch inverted so everything is back at z=1. At least that is the general direction my hands were waving, – to get really interesting it would be useful to get rid of the inverse.
Hm. I thought we already handled the negating for the endo… but I guess the wnaf code is doing that.. and manages to do it without negating the point directly but instead permuting the wnaf table entries. Cute trick. (obviously negations could be deferred here by sign tracking, but I don’t see how to avoid most of them).
RE: degenerate performance when the magnitudes are too different: When I first pointed out these techniques, sipa remarked:
9:59 < gmaxwell> Anyone looked at using bos-coster (or other similar algorithims) for batch verification? 20:00 < gmaxwell> it’s kind of like extgcd… the way it works is we want to compute aP1 + bP2 + cP3 … we put these scalar,point tuples in a max-heap, and pop off the two largest items (x,y) and set x = (x-y),Px y = y,(Px+Py) then push them back into the heap (unless x becomes 0, in which case it falls out). This keeps going until at the end you have a single remaining value, which should be small, and you then use
20:00 < gmaxwell> a coventional variable time scalar multiply for it. 20:03 < gmaxwell> It would couple well with the endomorphism split, which the existing batch does not. 20:22 < gmaxwell> a little toy implementation in sage, with a batch size of 512, if I split first (meaning a batch of 1024 half sized entries) I end up needing an average of 16097 point adds total. I think this compares pretty favorably what we currently do (which IIRC does ~32 adds per pubkey, plus about 16 or so to build the precomp) 20:28 < gmaxwell> A really gigantic batch of 4096 gets it down to 24 adds per pubkey. 22:53 < gmaxwell> (I was looking for how to compute an efficient addition chain for polysig when I ran into that) 02:03 <@sipa> i guess, when x>2y, you can replace with Px+2Py 02:04 <@sipa> why does ed25519 not use this? 02:04 <@sipa> or does it? 02:04 < gmaxwell> It doesn’t. So, there is a ed25519 paper that talks about it. 02:05 <@sipa> it probably only helps with very large batches? 02:07 < gmaxwell> They claim in that paper that its a win at all batch sizes, though I think because of our other optimizations that it kills it probably isn’t. They also have a newer paper that goes into more detail http://cr.yp.to/badbatch.html .. but it looks as close as they have to an implementation is in python. 02:08 < gmaxwell> Paper also mentions an algorithim that should be asymtopically 2x faster, due to Pippenger – I got the paper but my patience ran out before I managed to extract the algorithim from it. :) (the bos-coster is super trivial) 02:10 < gmaxwell> The gain is greater with bigger batches (goes up with the log of the batch size). 02:11 < gmaxwell> I think how well it composes with the endomorphism is pretty much required to make it a win for us, but I didn’t compare that much.peterdettman commented at 5:42 am on June 21, 2017: contributorNext I’ll try catching scalar 1’s and adding their points to a running return value rather than spamming the heap with them
You could generalise this by diverting “small” multiples (probably 2-4 bits or so) to an entry in a small-multiples table. Say it’s 3 bits, so 7 (non-zero) values. This can be finished off with 3 doubles and 9 adds to get the result in the “1” entry, less if there are empty entries. @gmaxwell That ‘replace’ operation was the first thing I noticed missing from Java’s PriorityQueue. In that class, the heap replaces a removed head with the last (array) element and sifts down. Then a subsequent add is placed at the end and sifted up (these operations are careful to keep a dense representation in the underlying array). A replace should be able to just remove the head, bubble up the largest children, then put the new entry in the “hole” and sift up (not sure Floyd’s trick refers to this specifically or any case of sifting new entries up from the end).
I’m somewhat skeptical that any sort of z->1 “fix-ups” mid-algorithm can work out; my sense is the cost is likely higher than the savings, but it obviously depends on the average number of additions you’re performing on all the intermediate points. Removing points (or rather scalars) from the heap could hurt though. Assuming there is any advantage to be gained, a periodic stop-and-fix should be enough; maybe keep a counter of how many non-affine points have crept in.
Looking at n1.P1 + n2.P2 + …, with n1 >= 2^k.n2. As noted above, https://ed25519.cr.yp.to/ed25519-20110926.pdf mentions using (n1 −2^k.n2).P1 +n2.(2^k.P1 + P2). They don’t use it there, because the scalars are all randomised (by 128-bit values), and it virtually never occurs. For a general multi-exp, you couldn’t assume anything of course. A few thoughts:
- The above formula dodges the truly worst case, but you can still end up having to (chain-)double the same P more than once.
- If n1 is even, we can first double P1 until it’s not (up to k times).
- Maybe decompose n1 as (u.2^k + v) and (conceptually) put (u, 2^k.P1) and (v, P1) into the heap. Downside is post-construction insertions (probably bounded by the maximum scalar bits), but if the small-multiples table is used, k could be limited so that we just slice “windows” from the bottom of n1 to shorten it, and add P1 to the appropriate entry, keeping (u, 2^k.P1) at (super-)root.
- Note that the windowing decomposition plus small-multiples table gives a reasonably efficient behaviour when you are left with (or start with!) a single scalar multiple.
I’d expect the endomorphism to have a large impact for small batches, but the advantage should taper off for larger batches, and memory use is a constant factor higher (<2). I’ll try and get a rough “scale” from my Java implementation.
storing the number of non-zero words in the scalars
Or just track the “longest length” (hey, it’s a heap), and do all comparisons to that length.
in src/modules/aggsig/tests_impl.h:44 in 6c2b341da5 outdated
39+ random_scalar_order_test(&tmp_s); 40+ secp256k1_scalar_get_b32(seckeys[i], &tmp_s); 41+ CHECK(secp256k1_ec_pubkey_create(ctx, &pubkeys[i], seckeys[i]) == 1); 42+ } 43+ 44+ aggctx = secp256k1_aggsig_context_create(none, pubkeys, 10, seed);
jonasnick commented at 1:31 pm on June 22, 2017:This line makes address sanitizer complain loudly because it is an out of bounds read (pubkeys only has 5 elements).apoelstra commented at 3:35 pm on June 23, 2017: contributorNeeds rebase now, but added several commits:
- change heap implementation to work only on indices rather than copying whole scalars and points around
- replace heap insertions/deletions with in-place heapify and update-root
- optimize some scalar operations to avoid interacting with the modulus
- hash all the non-index data separately so that the per-pubkey hash has less data (hash the nonce too so the sigs are no longer forgeable ;) this was going to be a review canary once everyone stopped focusing on perf, but Jonas caught it early)
- endomorphism support
Some approximate perf numbers on my laptop with 30-signature aggregates:
- just verifying 30 signatures w/o endomorphism: 1960us
- just verifying 30 signatures with endomorphism: 1400us
- first version of this PR: 1150us
- current PR w/o endomorphism: 730us
- current PR with endomorphism: 650us
The numbers are much less impressive with small aggregates (in fact for one or two signatures they’re significantly worse) and much more impressive for very large aggregates.
We do actually need to deal with the big-number-small-number performance issues, there is a real DoS vector in the current code where if the user passes an “aggregate signature” with a 16-bit s value, say, the endomorphism-enabled code will spend 112 bits of iterations grinding that
soff of some 128-bit scalar. It’s even worse without the endomorphism.Edit: callgrind tells me we’re spending 87% of our time in
gej_add_varand 7% of our time inheap_siftdown, so it seems like any more gains at this point are to be had by somehow reducing the number of additions we do (or reducing the cost of additions by effective-affine or some other black magic). Comparisons etc are less than 0.1%.I don’t see any obvious ways forward here, for uniformly random input this algorithm does a very good job of quickly reducing its input sizes and not repeating any work.
peterdettman commented at 7:59 am on June 24, 2017: contributorI see (every time) test failures after building (–enable-endomorphism=yes if that matters):
test count = 10 random seed = b26c06e44c9a45c5749433488fadbad7 ./src/field_5x52_impl.h:50: test condition failed: r == 1 Abort trap: 6
Edit: callgrind tells me we’re spending 87% of our time in gej_add_var and 7% of our time in heap_siftdown, so it seems like any more gains at this point are to be had by somehow reducing the number of additions we do (or reducing the cost of additions by effective-affine or some other black magic). Comparisons etc are less than 0.1%.
Actually there are still some gains to be had in the heap implementation. I re-implemented here: https://github.com/peterdettman/secp256k1/commit/aa01f4b87118805a3cfd3ffa92ab1b02c4e981b9 . That’s at least 5% faster on
bench_aggsignumbers for me. It’s mostly due to reducing the number of scalar comparisons (branch mis-predictions) I believe, by 1) managing the max element outside of the heap, and 2) using Floyd’s trick of “replacing” that element to the bottom of the heap when it’s reinserted.peterdettman commented at 3:21 pm on June 24, 2017: contributorFor the pathological inputs (big-small problem), just adding a binary ladder step when a single subtraction isn’t enough seems to at least avoid disaster: https://github.com/peterdettman/secp256k1/commit/cea5d3a371917592f8a96b30669f9c12bc717066 .apoelstra commented at 6:03 pm on June 24, 2017: contributorVery cool, my numbers also show your code performing 5% or so faster than mine. I’ll maybe clean up your commit (just renaming
MY_tosecp256k1_and removing the#ifdefis probably sufficient) and cherry-pick it onto my branch. Can also confirm that the hit from doing the binary ladder step is small, if anything.We want to use the existing
ecmultanyway for 1- or 2-point multiexponentiations so maybe we should replace the binary ladders with that?I’m not sure what to make of your test failures, I don’t see this on my code or yours, and Travis seems happy with my code at least.
gmaxwell commented at 7:01 pm on June 24, 2017: contributorI may have reproducedg dettman’s crash. looking into it, as an aside:
memset(&sc[0], 0, sizeof(sc[0])); secp256k1_ecmult_multi(&r, sc, pt, 20);you only zero the first one, but add 20 of them. If tests are run with ncount 0, some of the entries are uninitilized by earlier code. (looks like this error is common in the new tests, not just at this one point)
in src/scalar_4x64_impl.h:113 in 45fad60ab7 outdated
100+ r->d[3] = a->d[3] - b->d[3] - (a->d[2] < b->d[2]); 101+ r->d[2] = a->d[2] - b->d[2] - (a->d[1] < b->d[1]); 102+ r->d[1] = a->d[1] - b->d[1] - (a->d[0] < b->d[0]); 103+ r->d[0] = a->d[0] - b->d[0]; 104+} 105+
peterdettman commented at 0:30 am on June 25, 2017:Carry propagation?
apoelstra commented at 0:33 am on June 25, 2017:ais always greater thanbwhen this function is called. Each carry is propogated, except that there is no carry to propogate to the difference of the lowest-significance words.
peterdettman commented at 0:47 am on June 25, 2017:Consider a[0,0,0,1] - b[1,0,0,0], (so a > b), carry at lowest limb not propagated to highest.
apoelstra commented at 4:58 pm on June 27, 2017:Oh I understand, thanks. I will fix this and add a testcase.gmaxwell commented at 5:53 am on June 25, 2017: contributorWe obviously have to handled the cases where scalars differ by large amounts, to avoid attackers making our validation slow with effort linear in the slowdown– but it’s obvious how to handle that.
While thinking about generally adversarial scalars (stronger threat model than we need for aggregate signatures, perhaps, but it’s conservative and we , how could we defend against this pattern?
n_points = 32 randa = random.randrange(2**127,2**128) randb = random.randrange(2**127,2**128 - n_points) scalars = [randa * (randb + x) for x in range(n_points)]This one doesn’t result in gratuitously different magnitudes but it makes the algorithm exceptionally slow to converge.
Should we just have some sanity maximum for the main bos-coster iteration that detects if it is not converging and bails out to a simple straus’ algorithm without precomp? Even for cases where an attacker cannot directly control the scalars except via grinding this might have give us a piece of mind in not having to prove that hard cases are cryptographically hard to reach, since even that attack could only cause a 5 times slowdown or whatever.
peterdettman commented at 8:12 am on June 25, 2017: contributor@gmaxwell Take a look at https://github.com/peterdettman/secp256k1/commit/cea5d3a371917592f8a96b30669f9c12bc717066 (again). The handling for the big-small case is perhaps not what you assumed it is. I tried your case in equivalent Java code and it chewed it up (much faster than random cases). If I switch to the big-small handling mentioned in the eddsa paper, then yes, it’s much slower. With no special case, it essentially hangs, of course.
I don’t yet see a need for a bail-out routine; if the main loop guarantees a minimum 1-bit shortening of the largest scalar in any given iteration (without linear number of point doublings), then AFAICT the overall worst-case is already not much worse than the average. That commit shows a simple way to achieve the 1-bit guarantee, but it can certainly be improved on if we care to.
gmaxwell commented at 9:06 am on June 25, 2017: contributor@peterdettman I confirm that your “internal ladder step when the result is still bigger then the next best” solves my killer test case.
Contrary to my earlier belief the simpler corner case handling ( nX + mY = (n-(2^n)m)X + m((2^n)X + Y) ) is enough to make my ‘killer’ case not run forever (as you observed), though its still a fair bit slower than random cases. Your proposal is, as you note, faster than random for that input.
With your code I think the algorithm must converge exponentially and I am doubtful I can construct something that won’t and I think this can be proven.
(As an aside, I think switching to the binary ladder step feels a lot like the escape to bisection in dekker’s root finding mechanism: https://en.wikipedia.org/wiki/Brent%27s_method#Dekker.27s_method )
apoelstra force-pushed on Jun 28, 2017apoelstra commented at 7:22 pm on June 28, 2017: contributorRebased everything and pulled in Peter Dettmann’s heap improvements.
At Greg’s suggestion spent some time reading Pippenger’s Algorithm by djb. Unfortunately the described algorithm appears almost certainly to be slower than Bos-Coster for our usecase (one multiexp with many bases vs many multiexps that share bases); to get the benefit of Pippenger we need to use the “transpose” of the described algorithm, which seems to require a lot of insight/study to obtain. …Not to knock djb’s writing, he did a phenomenal job translating the original Pippenger paper from a series of lemmas about matrix row counts (seriously) into an algorithm!
Next steps:
- Add benchmarks for 1- and 2-signature aggregates so we get a picture of small-aggregate performance
- Special case the multiexp when there are only 1 or 2 bases, to use the existing ecmult code
- Write a special sign/verify for the 1-signature case to make Schnorr signature creation easy and obviously possible.
Then Greg has suggested we do something smarter about memory management than this “maximum 32 aggregates because we want fixed stack size requirements”. Need more discussion, once we resolve that I think I can take the WIP label off.
(Edit re-push last commit with a signature/timestamp on it)
apoelstra force-pushed on Jun 28, 2017sipa commented at 7:25 pm on June 28, 2017: contributorWould it be worthwhile to separate off the multimul (we can’t really call it multiexp, right?) into a separate PR. That is generally useful utility functionality (which at least @bbuenz has asked for before), while the actual signature scheme may warrant more discussion?apoelstra commented at 7:27 pm on June 28, 2017: contributor@sipa I think so, though the aggregate signatures are (a) the only API exposure of the multimul (that feels weird :)) and (b) are also the only benchmark exposure.
Though I think I might add a ecmult_benchmark anyway since we have so many different versions of that function now..
apoelstra force-pushed on Jun 28, 2017apoelstra force-pushed on Jun 28, 2017in include/secp256k1_aggsig.h:72 in 185fab9792 outdated
67+ secp256k1_aggsig_context *aggctx 68+); 69+ 70+/** Generate a nonce pair for a single signature part in an aggregated signature 71+ * 72+ * Returns: a newly created context object.
instagibbs commented at 8:35 pm on June 28, 2017:returns nonce, I assume
apoelstra commented at 8:36 pm on June 28, 2017:Lol, oops, no, it only returns an error code.in src/ecmult_multi_impl.h:99 in 30b66d4ebc outdated
123- idx[0] = idx[*n - 1]; 124- *n -= 1; 125- /* sift the new root into place */ 126- secp256k1_heap_siftdown(sc, idx, *n, 1); 127+SECP256K1_INLINE static void secp256k1_heapify(secp256k1_scalar_heap *heap) { 128+ size_t root = heap->size >> 1;;
gmaxwell commented at 0:09 am on June 29, 2017:;;
apoelstra commented at 0:11 am on June 29, 2017:Thanks.
This is far from the first time I’ve done this, I wonder what I’m doing to cause it.
bbuenz commented at 0:20 am on June 29, 2017: noneI would still appreciate multiexp. but don’t let that be a determining factor. I guess if I understand @gmaxwell correctly then libsecp256k1 isn’t even designed to build new crypto-protocols but it’s only supposed to be used for a few specific protocols that it has been tested and optimized for.in src/ecmult_multi_impl.h:171 in a915fa9fd4 outdated
166+ 167+ /* To handle pathological inputs, we use a binary ladder step here */ 168+ if (secp256k1_scalar_shr_int(&sc[first], 1) == 1) { 169+ secp256k1_gej_add_var(r, r, &pt[first], NULL); 170+ } 171+ secp256k1_gej_double_nonzero(&pt[first], &pt[first], NULL);
gmaxwell commented at 2:29 am on June 29, 2017:https://www.youtube.com/watch?v=ji1k9hZkN2I
Incompatible with the gej_is_infinity bailout below.
peterdettman commented at 3:24 am on June 29, 2017:I agree. As an aside, this is another case where we could do with some VERIFY infrastructure at the group level. In this case I envisage tracking a “possible_infinity” value in group elements. The current VERIFY_CHECK in _gej_double_nonzero doesn’t achieve much.
gmaxwell commented at 3:44 am on June 29, 2017:Probably we should use the exhaustive_test setup to try all 13^4 possible inputs for two keys, and perhaps 13^6 for three maybe ifdefefed off by default. .
peterdettman commented at 8:39 am on June 29, 2017:@apoelstra Just need to replace those two _double_nonzero calls with _double_var instead.
apoelstra commented at 8:00 pm on July 5, 2017:Fixed, added a test that catches it.in src/modules/aggsig/main_impl.h:270 in 813f3e5ea0 outdated
265+ 266+ if (!secp256k1_fe_set_b32(&fe_tmp, sig64 + 32)) { 267+ return 0; 268+ } 269+ secp256k1_scalar_set_int(&sc[1], 1); 270+ secp256k1_ge_set_xquad(&ge_tmp, &fe_tmp);
sipa commented at 0:20 am on July 7, 2017:If this returns 0, validation should fail. Unsure why your current code doesn’t fail in that scenario (tests_impl.h:118), but if I switch the ecmult code for a Strauss-based version, assertions fail.
apoelstra commented at 0:27 am on July 7, 2017:Good catch. And the test on line 118 is pretty crude.in src/modules/aggsig/main_impl.h:257 in 813f3e5ea0 outdated
252+ 253+ if (n_pubkeys == 0) { 254+ return 0; 255+ } 256+ 257+ /* Compute sum -sG + R + e_i*P_i */
sipa commented at 7:20 am on July 7, 2017:I think it is more efficient to write it as R == sG - e_i*P_i. You compute the right hand side and compare it for equality with R. This reduces the number of ecmult points by 1, which is very significant for low counts.
sipa commented at 5:52 pm on July 7, 2017:I guess this does not matter for Bos-Coster, as the factor 1 effectively turns it into a single addition at the end. It does matter for Strauss-wNAF though, as it avoids building the odd multiples table.
gmaxwell commented at 11:43 am on July 8, 2017:Well it’s also what’s required for the X-only ECDSA or the lagrange symbol only for the batchable schnorrs.
peterdettman commented at 3:59 am on July 11, 2017:Just handle R with an addition (or comparison) outside the multi-exp?in src/modules/aggsig/main_impl.h:276 in 813f3e5ea0 outdated
271+ secp256k1_gej_set_ge(&pt[1], &ge_tmp); 272+ secp256k1_compute_prehash(ctx, prehash, pubkeys, n_pubkeys, &ge_tmp, msg32); 273+ 274+ i = 0; 275+#ifdef USE_ENDOMORPHISM 276+ secp256k1_aggsig_endo_split(&sc[0], &sc[2], &pt[0], &pt[2]);
sipa commented at 7:22 am on July 7, 2017:It would be nice if the endomorphism splitting code was in secp256k1_ecmult_multi (like it is in secp256k1_ecmult). That way the aggsig code (and any other multi-mul users) can be free of ifdefs.
peterdettman commented at 1:46 pm on July 10, 2017:Not only that but the precomputation tables for the endo points are much cheaper if you know they are from the endo.in src/ecmult_multi_impl.h:184 in 813f3e5ea0 outdated
179+ } 180+ } 181+ 182+ VERIFY_CHECK(!secp256k1_scalar_is_zero(&sc[first])); 183+ 184+ if (secp256k1_gej_is_infinity(&pt[first])) {
peterdettman commented at 3:54 am on July 11, 2017:It seems to me this case is a) unlikely, b) safe to handle below, c) fast if handled below anyway. So I’d suggest removing this special handling.
apoelstra commented at 2:26 pm on July 11, 2017:Agreed.in src/scalar_4x64_impl.h:107 in 813f3e5ea0 outdated
95@@ -96,6 +96,17 @@ static int secp256k1_scalar_add(secp256k1_scalar *r, const secp256k1_scalar *a, 96 return overflow; 97 } 98 99+static void secp256k1_scalar_numsub(secp256k1_scalar *r, const secp256k1_scalar *a, const secp256k1_scalar *b) { 100+ int c0 = a->d[0] < b->d[0]; 101+ int c1 = a->d[1] < b->d[1] || (c0 && a->d[1] == b->d[1]); 102+ int c2 = a->d[2] < b->d[2] || (c1 && a->d[2] == b->d[2]); 103+
peterdettman commented at 4:12 am on July 11, 2017:How about a ‘c3’ for a VERIFY_CHECK?in src/scalar_4x64_impl.h:113 in 813f3e5ea0 outdated
104+ r->d[3] = a->d[3] - b->d[3] - c2; 105+ r->d[2] = a->d[2] - b->d[2] - c1; 106+ r->d[1] = a->d[1] - b->d[1] - c0; 107+ r->d[0] = a->d[0] - b->d[0]; 108+} 109+
peterdettman commented at 4:16 am on July 11, 2017:I think something more like _scalar_add using an int128 accumulator would be clearer and probably faster.
apoelstra commented at 3:36 pm on July 13, 2017:Seems a bit slower actually, drops aggsig performance from 730-735us to 740-750us for a 30-sig aggregate.
sipa commented at 4:16 am on July 19, 2017:That’s very surprising, and probably worth investigating further. Should we use the same approach for addition?apoelstra force-pushed on Jul 13, 2017apoelstra commented at 3:49 pm on July 13, 2017: contributor- fix
secp256k1_aggsig_generate_noncedoc return value - Add check for
set_xquadfailing in aggsig/main_impl.h - Change verification equation to
R == sG - sum e_ix_i - Remove infinity check before doing the small multiply at the end of
ecmult_multi - Add VERIFY_CHECK to
scalar_numsubchecking that there is no final carry/underflow - Fix compilation warnings when endomorphism is disabled
Will add “dispatch function” for
ecmult_multithat encapsulates the endomorphism code, does a copy (so that the ecmult API does not require mutable inputs), and is designed so Pieter can hook in the Strauss code there for small input sizes. Will also take theGscalar separately, and when calling my code it will just put it in the pile with the rest of them. But Pieter says Strauss gets a nontrivial advantage from having it be separate, so make that easy.apoelstra commented at 5:32 pm on July 13, 2017: contributorAdded a WIP/draft version of a dispatch function, @sipa what do you think about this API? I need to decide what to do about memory allocation, it’s annoying that aggsig needs an arbitrary-sized scratch space and thenecmult_multineeds the same amount of scratch space just to make an unnecessary copy of the first data.apoelstra commented at 4:52 pm on July 14, 2017: contributorReplaced API with a callback-based one. Now all the looping logic is removed fromaggsig_verifyinto the dispatch function, which gets rid of a bunch of duplicated logic and also means that all of the variable-size-allocation stuff can stay withinecmult_multi_impl.h.in include/secp256k1.h:180 in af4888f95d outdated
158@@ -159,6 +159,16 @@ typedef int (*secp256k1_nonce_function)( 159 #define SECP256K1_EC_COMPRESSED (SECP256K1_FLAGS_TYPE_COMPRESSION | SECP256K1_FLAGS_BIT_COMPRESSION) 160 #define SECP256K1_EC_UNCOMPRESSED (SECP256K1_FLAGS_TYPE_COMPRESSION) 161 162+/** Prefix byte used to tag various encoded curvepoints for specific purposes */ 163+#define SECP256K1_TAG_PUBKEY_EVEN 0x02 164+#define SECP256K1_TAG_PUBKEY_ODD 0x03 165+#define SECP256K1_TAG_PUBKEY_UNCOMPRESSED 0x04 166+#define SECP256K1_TAG_PUBKEY_HYBRID_EVEN 0x06 167+#define SECP256K1_TAG_PUBKEY_HYBRID_ODD 0x07
sipa commented at 4:08 am on July 19, 2017:Weird spacing.
apoelstra commented at 2:01 pm on July 19, 2017:
in src/bench_aggsig.c:2 in af4888f95d outdated
0@@ -0,0 +1,64 @@ 1+/********************************************************************** 2+ * Copyright (c) 2014-2015 Pieter Wuille *
sipa commented at 4:09 am on July 19, 2017:Wow, I can’t remember writing this!in src/ecmult_multi_impl.h:255 in af4888f95d outdated
222+ 223+ sc[0] = *inp_g_sc; 224+ secp256k1_gej_set_ge(&pt[0], &secp256k1_ge_const_g); 225+ idx++; 226+#ifdef USE_ENDOMORPHISM 227+ secp256k1_ecmult_endo_split(&sc[0], &sc[1], &pt[0], &pt[1]);
sipa commented at 4:12 am on July 19, 2017:Doing endo split on the G factor is unnecessary… you can just split in 128-bit parts using mask/shift, and use a precomputed 2^128*G constant (which we probably already have in the verification context).
apoelstra commented at 2:02 pm on July 19, 2017:What do you mean “split in 128-bit parts using mask/shift”?
apoelstra commented at 2:08 pm on July 19, 2017:Oh I understand, using2^128*Grather thanlambda*G. Sure.in src/ecmult_multi_impl.h:183 in af4888f95d outdated
179+ } 180+ } 181+ 182+ VERIFY_CHECK(!secp256k1_scalar_is_zero(&sc[first])); 183+ 184+ /* Now the desired result is heap_sc[0] * heap_pt[0], and for random scalars it is
sipa commented at 4:13 am on July 19, 2017:Mention that it ends with the GCD of the input scalars?
peterdettman commented at 1:36 am on July 21, 2017:I don’t think that holds with the possible ladder step in the main loop.apoelstra commented at 2:04 pm on July 19, 2017: contributor@sipa re using manual carry bits for addition, my belief as to why subtraction is slower usingint128_tis that there are 63 bits of sign-extended 1’s that get repeatedly added when you do things thescalar_addway. So theint128_tcode does way more work than my code. The same wouldn’t be true forscalar_add.sipa commented at 5:58 pm on July 19, 2017: contributor@apoelstra But (a + b) can be rewritten as (a - (~b + 1)). If there is a means to speed up subtraction, it seems that it can be used to speed up addition too.apoelstra commented at 6:09 pm on July 19, 2017: contributorI’m saying that my code and the gcc addition code are pretty-much identical for the case
a + bbecause in both cases you have only one bit of carry to track and no sign extension. I expect that rewriting it asa - (~b + 1)(three primitive operations to do one) will be slower than both of these.I am not claiming any way to “speed up subtraction”, only that adding unnecessary sign extensions to my existing code will slow it down.
sipa commented at 2:04 am on July 21, 2017: contributorBenchmarks with Strauss (#464) and Bos-Coster (this PR):
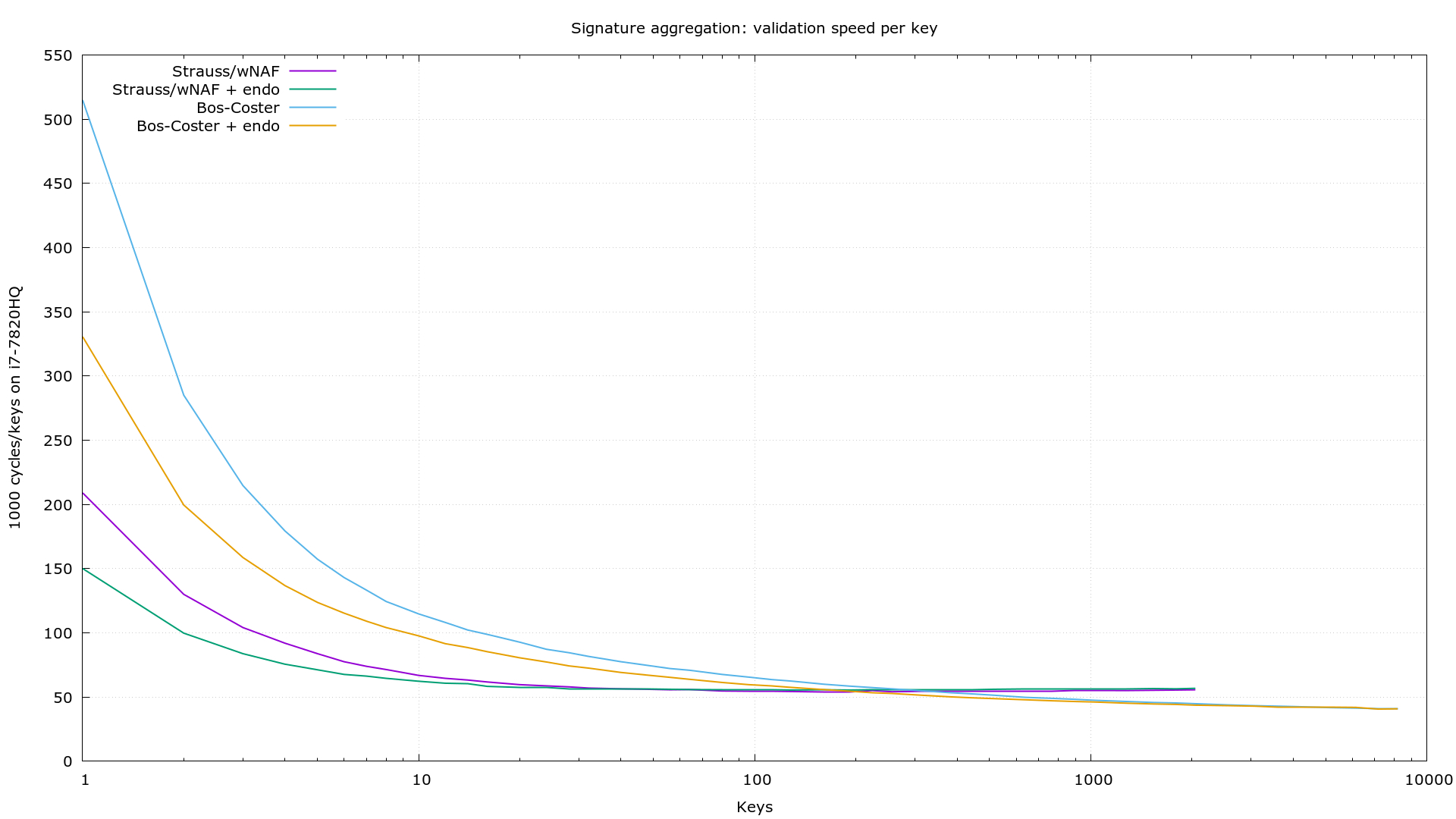 apoelstra commented at 10:00 pm on July 27, 2017: contributoradd support for using heap-based allocationapoelstra force-pushed on Jul 28, 2017apoelstra force-pushed on Aug 10, 2017apoelstra commented at 0:18 am on August 10, 2017: contributorRebase: separate out aggsig stuff from ecmult stuff, move ecmult stuff into
apoelstra commented at 10:00 pm on July 27, 2017: contributoradd support for using heap-based allocationapoelstra force-pushed on Jul 28, 2017apoelstra force-pushed on Aug 10, 2017apoelstra commented at 0:18 am on August 10, 2017: contributorRebase: separate out aggsig stuff from ecmult stuff, move ecmult stuff intoecmult_impl.hrather than having its own file, collapse some of the design iterations into single commits.in src/ecmult.h:15 in 87691f61ba outdated
8@@ -9,6 +9,9 @@ 9 10 #include "num.h" 11 #include "group.h" 12+#include "scalar.h" 13+ 14+#define SECP256K1_ECMULT_MULTI_MAX_N 32
sipa commented at 11:24 pm on August 10, 2017:Does this need to be exposed now?in src/ecmult_multi_impl.h:1 in 87691f61ba outdated
0@@ -0,0 +1,112 @@ 1+/**********************************************************************
sipa commented at 11:25 pm on August 10, 2017:Having this in a separate file from ecmult_impl.h I think will result in a circular dependency between strauss and the dispatch code.apoelstra force-pushed on Aug 10, 2017in include/secp256k1.h:182 in 90e1980ffc outdated
178@@ -166,6 +179,9 @@ typedef int (*secp256k1_nonce_function)( 179 #define SECP256K1_TAG_PUBKEY_HYBRID_EVEN 0x06 180 #define SECP256K1_TAG_PUBKEY_HYBRID_ODD 0x07 181 182+#define SECP256K1_TAG_AGGSIG_NONCE_EVEN 0x12
sipa commented at 11:47 pm on August 10, 2017:Weird indentation.in src/ecmult_impl.h:556 in 90e1980ffc outdated
551+ while (heap.size > 0) { 552+ second = heap.tree[0]; 553+ 554+ do { 555+ /* Observe that nX + mY = (n-m)X + m(X + Y), and if n > m this transformation 556+ * reduces the magnitude of the larger scalar, on average by half. So by
sipa commented at 11:50 pm on August 10, 2017:On average by way more than half, if you have a sufficiently large number of points. If you have 256 randomly distributed 256-bit integers, I expect the difference between the top two to be around 2^247.5.
apoelstra commented at 0:05 am on August 11, 2017:Oh, good point!in src/ecmult_impl.h:566 in 90e1980ffc outdated
561+ 562+ if (secp256k1_scalar_cmp_var(&sc[first], &sc[second]) < 0) { 563+ break; 564+ } 565+ 566+ /* To handle pathological inputs, we use a binary ladder step here */
sipa commented at 11:52 pm on August 10, 2017:Can you explain this in terms of the m/n/X/Y notation above?in src/modules/aggsig/aggsig.h:10 in 90e1980ffc outdated
5+ **********************************************************************/ 6+ 7+#ifndef _SECP256K1_MODULE_AGGSIG_AGGSIG_ 8+#define _SECP256K1_MODULE_AGGSIG_AGGSIG_ 9+ 10+typedef struct {
sipa commented at 11:57 pm on August 10, 2017:This definition (and in fact the whole file) looks kinda redundant.apoelstra force-pushed on Aug 11, 2017apoelstra force-pushed on Aug 11, 2017apoelstra commented at 3:51 pm on August 11, 2017: contributorAddress Pieter’s nits.sipa commented at 6:14 am on August 14, 2017: contributor@apoelstra This will make it easier to integrate Strauss: https://github.com/sipa/secp256k1/commit/67aa632ded9089565cde9ebe311fcbcf5072c794sipa commented at 9:24 pm on August 14, 2017: contributorapoelstra commented at 9:27 pm on August 14, 2017: contributorok, cherry-pickedsipa commented at 0:48 am on August 15, 2017: contributor@apoelstra This adds Strauss-wNAF secp256k1_ecmult_multi (used for n < 200, much scientific, wow). https://github.com/sipa/secp256k1/commit/23602bda1bf4d4a697a262dc9077d4835e3c4142apoelstra force-pushed on Aug 15, 2017apoelstra commented at 0:55 am on August 15, 2017: contributorCherry-picked and rebased. Need to refactor to be sure we’re not putting multiple types in the scratch space (alignment) and to have better dispatch logic.sipa commented at 9:58 pm on August 16, 2017: contributor@apoelstra Squashed, restructured, and with Bos-Coster removed: https://github.com/sipa/secp256k1/commits/20170816_aggsigsipa cross-referenced this on Aug 17, 2017 from issue Multi-point multiplication support by sipaapoelstra closed this on Aug 17, 2017
sipa commented at 6:43 pm on August 17, 2017: contributor@apoelstra No it isn’t, #473 doesn’t include aggsig, only ecmult_multi.apoelstra reopened this on Aug 17, 2017
in src/modules/aggsig/main_impl.h:269 in 8afc544be7 outdated
264+ 265+ /* extract R */ 266+ if (!secp256k1_fe_set_b32(&fe_tmp, sig64 + 32)) { 267+ return 0; 268+ } 269+ if (!secp256k1_ge_set_xquad(&r_ge, &fe_tmp)) {
sipa commented at 6:53 pm on September 3, 2017:When n_pubkeys is 1 (which is probably going to be pretty common), there is a more efficient verification algorithm where you don’t decompress R, but instead just compare the X coordinate of the recomputed version, and check that its Y coordinate is a quadratic residue.
apoelstra commented at 5:46 pm on September 6, 2017:Nice. I don’t think this even needsn_pubkeysto be 1.apoelstra force-pushed on Sep 6, 2017apoelstra commented at 6:01 pm on September 6, 2017: contributorUpdated to compare x-coordinate only of R (and checking that its y-coord is a quadratic residue).apoelstra force-pushed on Sep 6, 2017ignopeverell cross-referenced this on Sep 6, 2017 from issue Study support of vaults in grin/mimblewimble by ignopeverellyeastplume referenced this in commit 9eb90c9fd9 on Dec 6, 2017yeastplume cross-referenced this on Dec 6, 2017 from issue Aggsig work to date - merging by yeastplumeaggregate signatures: add module, implement single-user signing 5fa7589f75apoelstra force-pushed on Dec 10, 2017apoelstra commented at 9:12 pm on December 10, 2017: contributorRebased on latest master. One mild surprise is that I can’t callecmult_multi_varwith a scratch space smaller than 4.5Kb, so I had to update the aggsig tests to use a bigger on.jonasnick commented at 3:49 pm on December 11, 2017: contributorOne mild surprise is that I can’t call ecmult_multi_var with a scratch space smaller than 4.5Kb
Yes, if I recall correctly aggsig previously always used bos-coster and now strauss_wnaf which uses a fair amount of scratch space due to the multiplication table:
- without endo
96+n_points*3656bytes. - with endo
96+n_points*4568bytes.
jonasnick commented at 6:21 pm on January 26, 2018: contributorI have a few minor suggestions in my branch https://github.com/jonasnick/secp256k1/commits/aggsig-module
02e75a09 Stress that seed in aggsig_context_create must be secret 1ffeba25 Allow choosing number of signatures in bench_aggsig 220ad03b Remove n_sigs argument from aggsig API 31cada78 Add aggsig state machine testsjonasnick commented at 4:07 pm on January 29, 2018: contributorIt would be helpful if users could compute the optimal scratch space for verification. I suggest https://github.com/jonasnick/secp256k1/commit/e81fc0659466b759d22751d792e48ad29d32b83djonasnick cross-referenced this on Jan 29, 2018 from issue WIP: Add aggsig example code by jonasnickanargle cross-referenced this on May 29, 2018 from issue Kernel half-aggregation by anarglereal-or-random commented at 10:02 am on March 25, 2022: contributorI’m closing this because I believe it is obsolete given the recent research that led to a better understanding of multi-sigs and aggregate sigs. We can still take it as inspiration for future implementations of aggregate sigs.real-or-random closed this on Mar 25, 2022
github-metadata-mirror
This is a metadata mirror of the GitHub repository bitcoin-core/secp256k1. This site is not affiliated with GitHub. Content is generated from a GitHub metadata backup.
generated: 2026-04-06 04:15 UTC
This site is hosted by @0xB10C
More mirrored repositories can be found on mirror.b10c.me







