
This PR is based on #473 and adds a variant of “Pippengers algorithm” (see Bernstein et al., Faster batch forgery identification, page 15 and https://github.com/scipr-lab/libff/pull/10) for point multi-multiplication that performs better with a large number of points than Strauss’ algorithm.
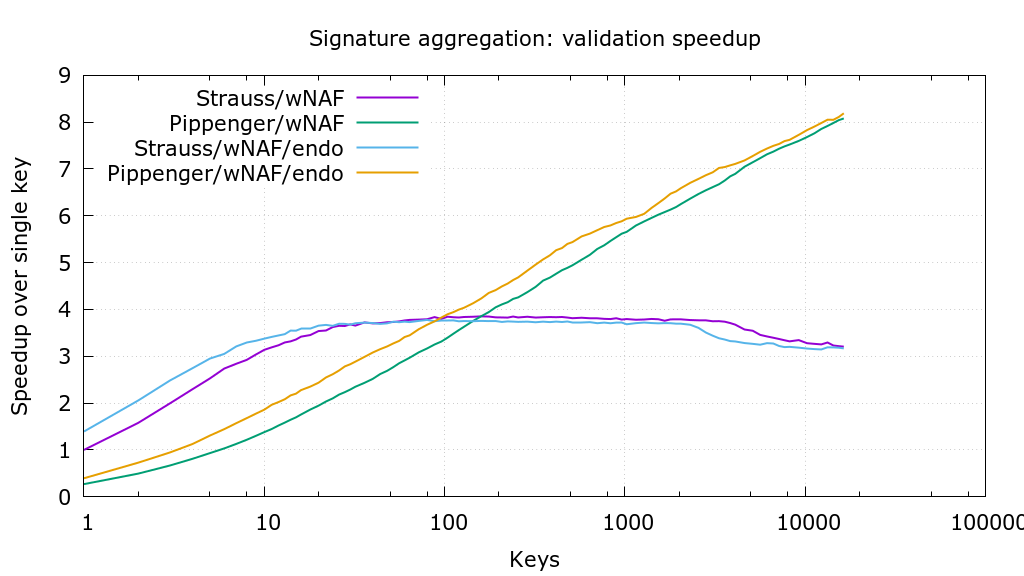
Thanks to @sipa for providing wnaf_fixed, benchmarking, and the crucial suggestion to use affine addition.
The PR also makes ecmult_multi decide which algorithm to use, based on the number of points and the available scratch space.
For restricted scratch spaces this can be further optimized in the future (f.e. a 35kB scratch space allows batches of 11 points with strauss or 95 points with pippenger; choosing pippenger would be 5% faster).
As soon as this PR has received some feedback I’ll repeat the benchmarks to determine the optimal pippenger_bucket_window with the new benchmarking code in #473.


