Hansel and Gretel left bread crumb trails as they went but birds ate them all.
This Pull Request improves the asymptotic complexity of many of the mempool’s algorithms as well as makes them more performant in practice.
In the mempool we have a lot of algorithms which depend on rather computationally expensive state tracking. The state tracking algorithms we use make a lot of algorithms inefficient because we’re inserting into various sets that grow with the number of ancestors and descendants, or we may have to iterate multiple times of data we’ve already seen.
To address these inefficiencies, we can closely limit the maximum possible data we iterate and reject transactions above the limits.
However, a rational miner/user will purchase faster hardware and raise these limits to be able to collect more fee revenue or process more transactions. Further, changes coming from around the ecosystem (lightning, OP_SECURETHEBAG) have critical use cases which benefit when the mempool has fewer limitations.
Rather than use expensive state tracking, we can do something simpler. Like Hansel and Gretel, we can leave breadcrumbs in the mempool as we traverse it, so we can know if we are going somewhere we’ve already been. Luckily, in bitcoind there are no birds!
These breadcrumbs are a uint64_t epoch per CTxMemPoolEntry. (64 bits is enough that it will never overflow). The mempool also has a counter.
Every time we begin traversing the mempool, and we need some help tracking state, we increment the mempool’s counter. Any CTxMemPoolEntry with an epoch less than the MemPools has not yet been touched, and should be traversed and have it’s epoch set higher.
Given the one-to-one mapping between CTxMemPool entries and transactions, this is a safe way to cache data.
Using these bread-crumbs allows us to get rid of many of the std::set accumulators in favor of a std::vector as we no longer rely on the de-duplicative properties of std::set.
We can also improve many of the related algorithms to no longer make heavy use of heapstack based processing.
The overall changes are not that big. It’s 302 additions and 208 deletions. You could review it all at once, especially for a Concept Ack. But I’ve carefully done them in small steps to permit careful analysis of the changes. So I’d recommend giving the final state of the PR a read over first to get familiar with the end-goal (it won’t take long), and then step through commit-by-commit so you can be convinced of the correctness for more thorough code reviewers.
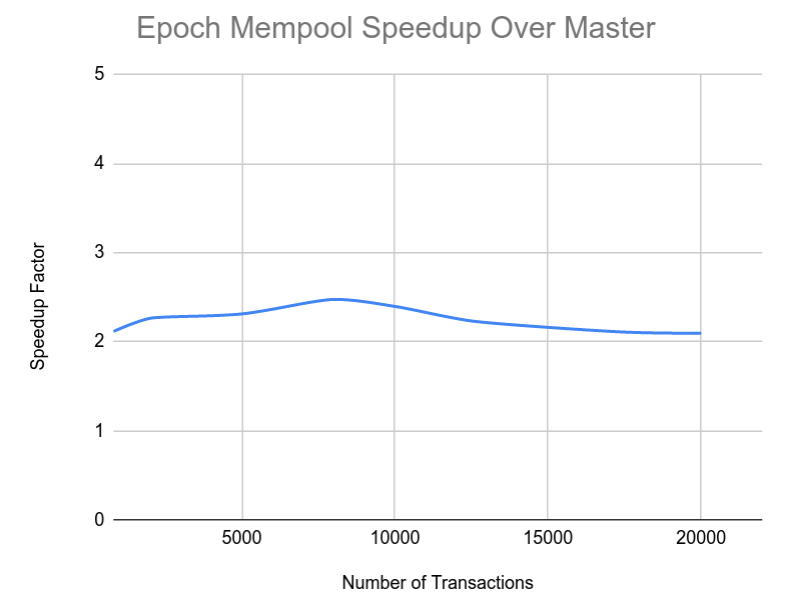
But is it good in practice? Yes! Basic benchmarks show it being 5% faster on the AssembleBlock benchmark, and 14.5% faster on MempoolEviction, but they aren’t that tough. Tougher benchmarks, as described below, show a >2x speedup.
PR #17292, adds a motivating benchmark for the Epoch Mempool.
./src/bench/bench_bitcoin –filter=ComplexMemPool –scaling=5
Before:
# Benchmark, evals, iterations, total, min, max, median ComplexMemPool, 5, 5, 6.62715, 0.264409, 0.265441, 0.2654After:
# Benchmark, evals, iterations, total, min, max, median ComplexMemPool, 5, 5, 3.07116, 0.122246, 0.12351, 0.122783This shows a > 2x speedup on this difficult benchmark (~2.15x across total, min, max, median).
Note: For scientific purity, I created it “single shot blind”. That is, I did not modify the test at all after running it on the new branch (I had to run it on master to fix bugs / adjust the expected iters for a second parameter, and then adjust the internal params to get it to be about a second).
What’s the catch? The specific downsides of this approach are twofold:
- We need to store an extra 8 bytes per CTxMemPoolEntry
- Some of the algorithms are a little bit less obvious & are “less safe” to call concurrently (e.g., from a recursive call, not necessarily in parallel)
But for these two specific downsides:
- The 8 bytes could be reduced to 4 (with code to reset all CTxMemPoolEntries near overflow, but then we would need to more carefully check that we won’t overflow the epoch in a recursive call.
- The 8 bytes could be a 4 byte index into a table of 8 (or 4, or even fewer) Byte epochs + back pointer, at expense of indirection like vTxHashes. Then we would only ever need as many epochs as the things we walk per-epoch.
- We can replace the epoch with an atomic, which would allow for new parallel graph traversal algorithms to build descendants more quickly
- Some algorithms benefit from recursive epoch use
So overall, I felt the potential benefits outweigh the risks.
What’s next? I’ve submitted this a bit early for review to gain concept acks on the approach, independent testing, and feedback on methodologies for testing, as well as to collect more worst-case edge conditions to put into benchmarks. It’s not quite a WIP – the code passes tests and is “clean”, but it should receive intense scrutiny before accepting.