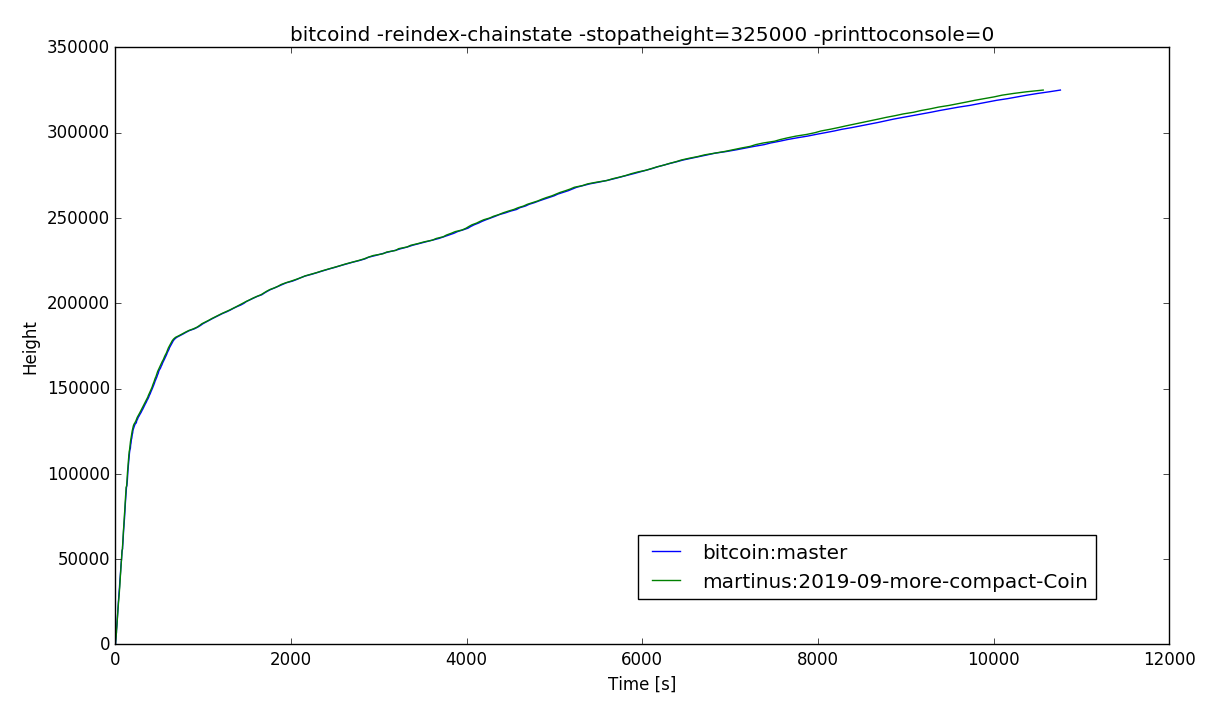
This is an attempt to more tightly pack the data inside CCoinsMap. (replaces #16970, done after my investigations on #16957) Currently, there is quite a bit of overhead involved in the CCoinsMap::value_type data structure (total bytes to the left):
096 CCoinsMap::value_type
1 36 COutPoint
2 32 uint256
3 4 uint32_t
4 4 >>> PADDING <<<
5 56 CCoinsCacheEntry
6 48 Coin
7 40 CTxOut
8 8 nValue
9 32 CScript
10 4 fCoinBase & nHeight
11 4 >>> PADDING <<<
12 1 flags (dirty & fresh)
13 7 >>> PADDING <<<
So there is quite a bit of padding data. In my experiements I’ve noticed that the compiler is forced to use a padding size >=8 only because nValue’s CAmount type is int64_t which has to be 8-byte aligned. When replacing nValue with a 4-byte aligned data structure, the whole CCoinsMap::value_type will be aligned to 4 bytes, reducing padding.
Another 4 bytes can be saved by refactoring prevector to only use a single byte for direct size information, and reducing CScript’s size from 28 to 27 bytes. It is still able to directly cache most scripts as most are <= 25 bytes long.
The remaining 4 bytes due to the 1 byte flag + 3 bytes padding in CCoinsCacheEntry can be removed by moving the flags into Coin, stealing another 2 bits from nHeight.
Finally, the resulting data structure is 20 bytes smaller:
076 CCoinsMap::value_type
1 36 COutPoint
2 32 uint256
3 4 uint32_t
4 40 CCoinsCacheEntry
5 40 Coin
6 36 CTxOut
7 8 nValue
8 28 CScript
9 4 fCoinBase & nHeight & flags (dirty & fresh)
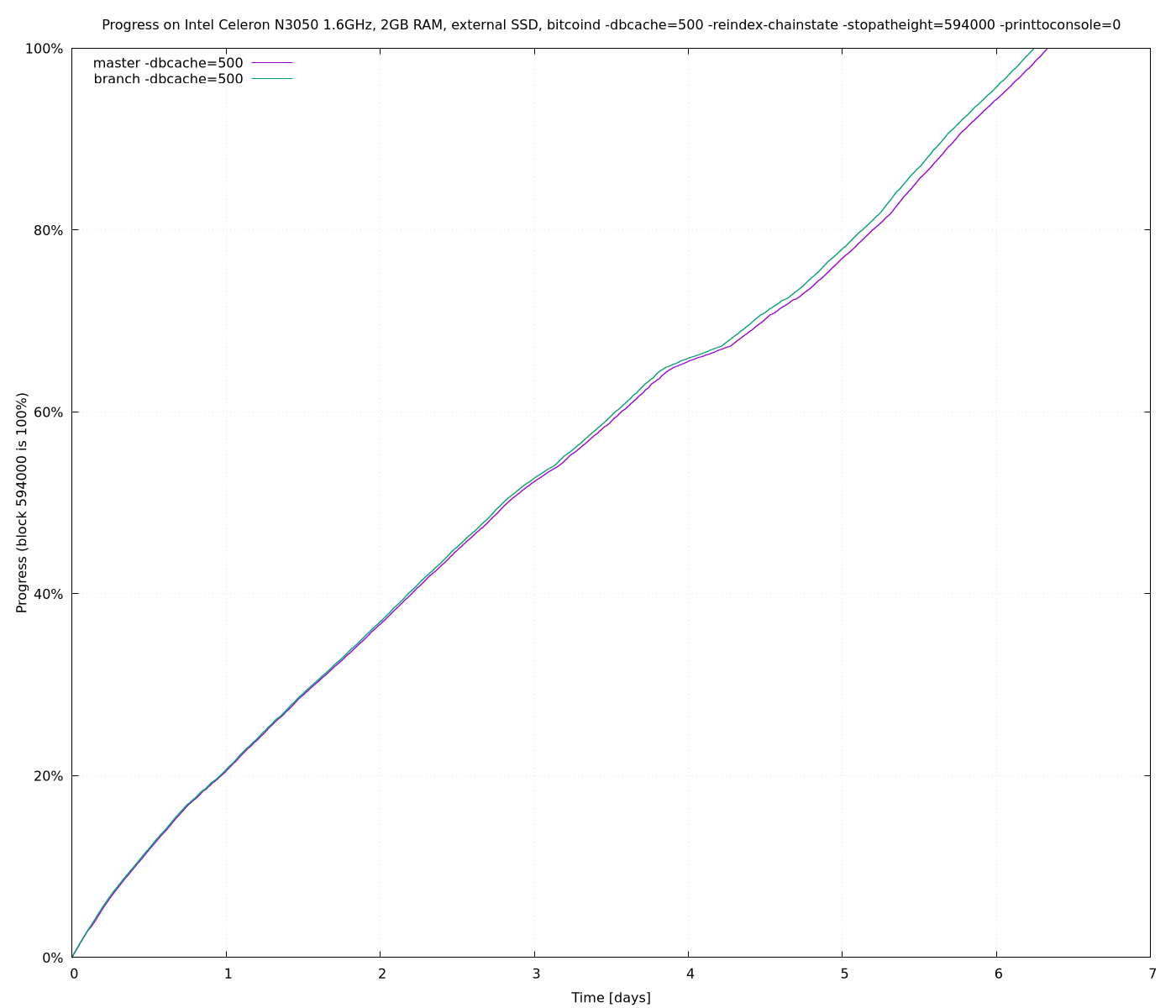
So we can store about 26% more data into dbcache’s memory. I have evalued this on my Intel i7-8700, 32GB RAM, external SSD, for -reindex-chainstate with both -dbcache=500 and -dbcache=5000:
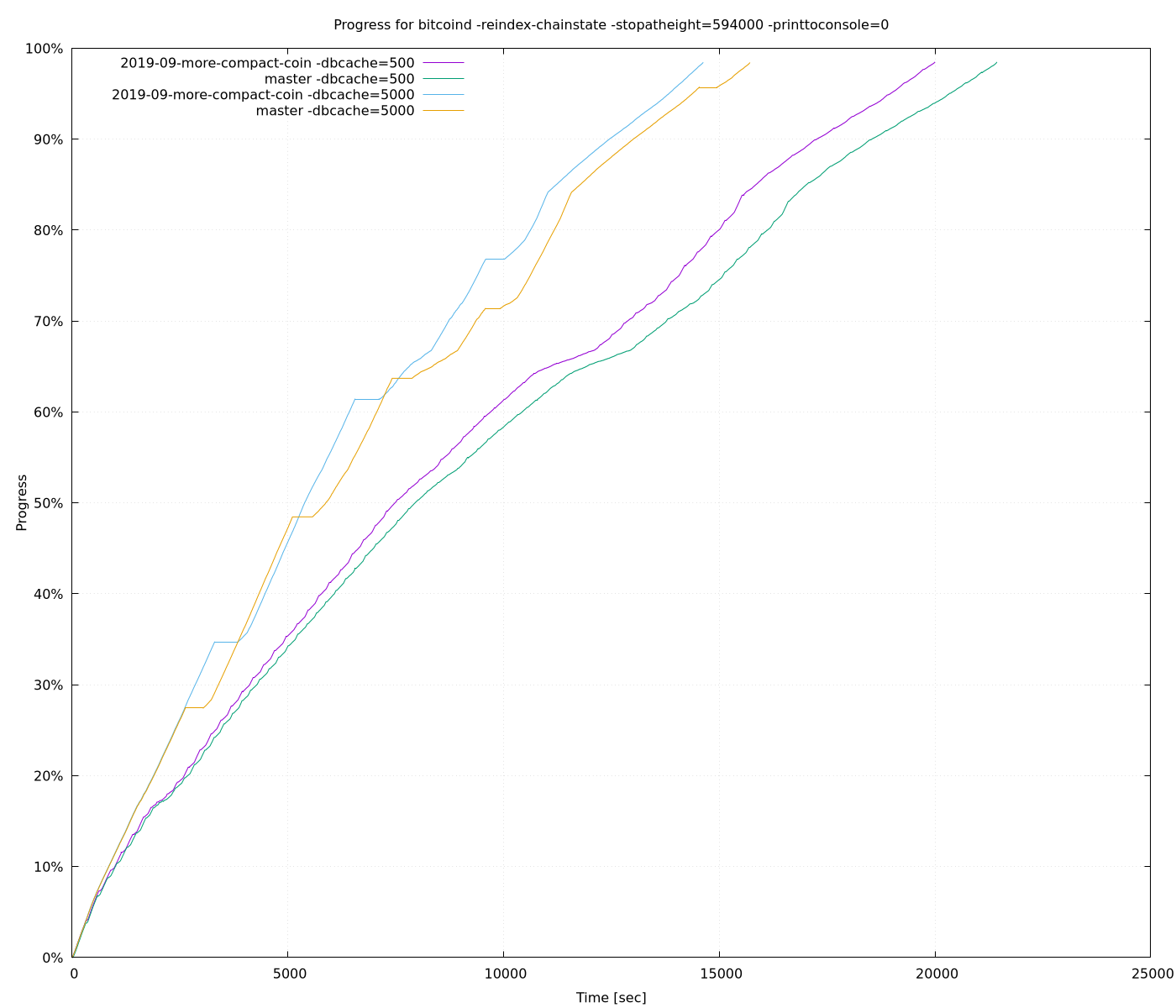
| time | max resident set size | ||
|---|---|---|---|
| master | -dbcache=500 | 05:57:20 | 2957532 |
| 2019-09-more-compact-Coin | -dbcache=500 | 05:33:37 | 2919312 |
| Improvement | 6,64% | 1,29% |
| time | max resident set size | ||
|---|---|---|---|
| master | -dbcache=5000 | 04:22:42 | 7072612 |
| 2019-09-more-compact-Coin | -dbcache=5000 | 04:09:16 | 6533132 |
| Improvement | 5,11% | 7,63% |
So on my machine there is definitive an improvement, but honestly I am not sure if this ~6% improvement is worth the change. Maybe the improvement is bigger with slower disk, as ~26% more transaction can be cached.